度小满金融超大规模图平台实践

分享嘉宾:单黎平 度小满金融
编辑整理:湖人
出品平台:DataFunTalk
导读:金融风控场景数据间有天然的关联。关联信息可以加强模型风险区分能力。复杂数据场景及海量数据规模给关联信息的管理、建模和模型部署都带来了巨大的挑战。本文将介绍度小满内部构建的超大规模图平台的一些经验与思考,并重点讲解在实践中碰到的问题与解决方式。主要内容包括:① 图数据治理;② 图模型训练;③ 图在线部署;④ 总结思考。
图数据治理
图数据治理指的是,如何将图数据以及图数据库、图应用结合起来,包括图平台搭建的一些基础性工作。
度小满的主要业务是信贷,而信贷业务中重要的是风控,风控里核心就是模型。而图平台的建设团队,即是风控模型的工程团队,给风控模型的算法和策略提供技术上和基础能力上的支持。
1. 业务背景
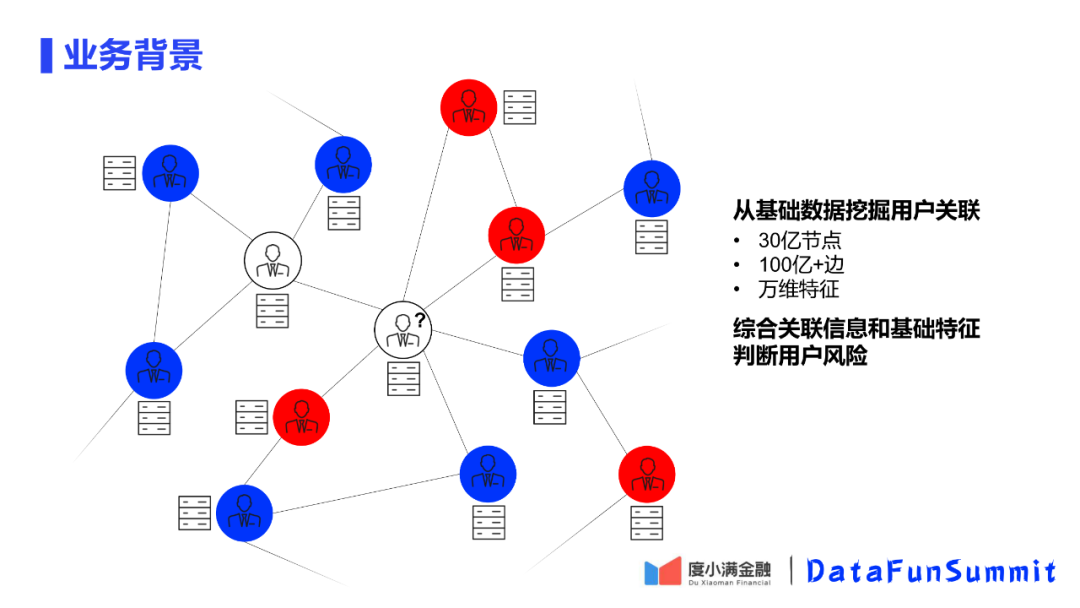
风控的主要业务工作,即是通过积累的信贷风控的用户,根据风控模型判断未知的用户是好用户还是坏用户。在风控用户图中,红色节点认为是坏用户,蓝色节点认为是好用户,风控即是对白色的未知节点是一个好用户还是一个坏用户做一个风险的判断。
以前的风控模型是基于未知用户挖掘出来的一些特征,我们部门团队在这个方面挖掘出来大概几十万的特征,在这些数据的基础上,使用有标签的数据进行模型训练,在生成一个风控模型,这样就可以对没有标签的节点做一个预测。
但在实际生活中,问题和利用的信息并不是这么简单的。举个例子来说,在贷款的时候会留一个紧急联系人的信息,这个信息就会将有标签的用户和无标签的用户连接起来,把所有的用户节点和关系构建成一个图中的大图,这样就可以将用户之间的关系也考虑到模型中来,从而更准确的判断用户的风险。
以图中的白色问号节点为例,周围关联了很多坏用户的节点,那么在判断的时候就会有一个倾向,是否这个用户也是一个坏节点,因此周围的节点会对用户的判断有一定的影响。
我们建立这个图平台的根本目的就是为了通过基础特征和关联信息判断用户的信贷风险。在通过长时间的积累后,我们已经挖掘到30亿的用户节点和100亿以上的边,构建起了一个异构的大图。
2. 风控场景能力
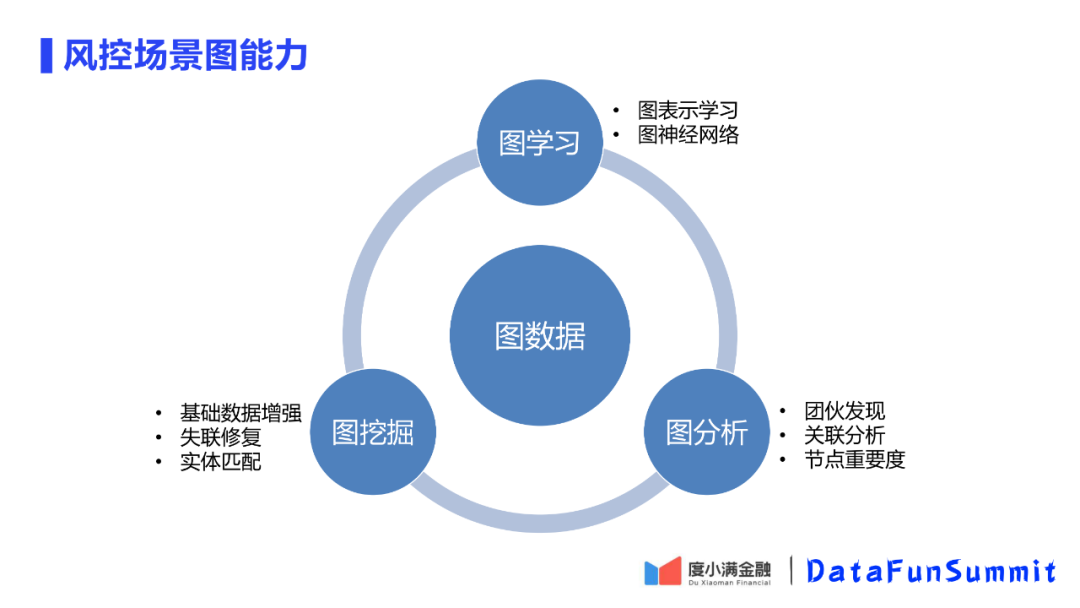
除了对图进行建模以外,我们还会要求图平台能够提供其他的一些基础的图的能力。三个层次的能力,围绕图数据展开。
① 图学习
包含图建模的能力,针对节点间关联的信息不考虑图节点特征的图表示学习,也可以包括对图节点聚合的图神经网络的学习。
② 图挖掘
举个例子,在借钱的时候有紧急联系人,打过去以后是空号,可以通过图关联信息,找到该用户的其他亲密用户,从而对这条链路进行修复。
③ 图分析
反欺诈场景,对欺诈团伙的发现是一个重要应用,这里就会用到社群发现等图聚类的一些算法。
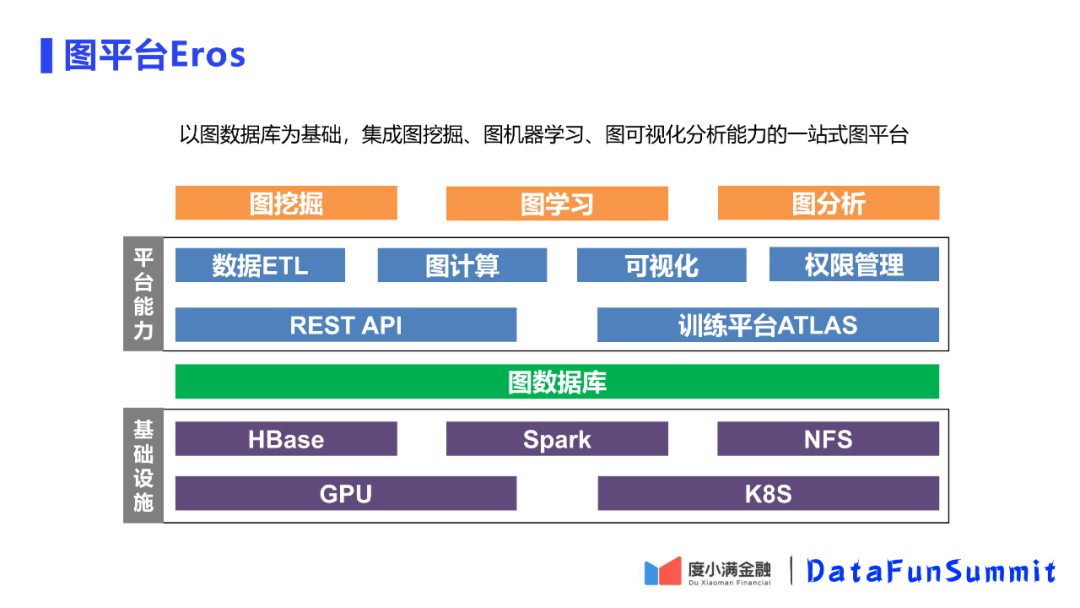
3. 如何围绕图数据建立起图的平台
图的数据不同于宽表的结构化数据,其最大特征就是非结构化数据。图的数据要用图数据库,对每个节点来说比较重要的特征就是有多少个邻居、跟其他节点的最窄路径等都有所不同。图数据库和传统数据库的最大区别就是建立索引不同,图数据库更多的是把有关联的边和节点聚合在一起去建立一个节点。
在图数据库之上,我们对于图数据库的能力进行了封装,做了一些开放的查询接口,例如查询一阶、二阶邻居,即webService。除此之外,需要对图数据进行导入导出的功能,即数据ETL模块,包括对数据仓库和图数据库之间的导出和导入。
图学习和图分析总结起来都属于图计算的能力,我们围绕图数据库提供了图计算的框架和能力的支持。图适合做可视化展示的数据结构,用图平台的用户可能不精通图挖掘、图数据、图模型,比如某些用户用图数据来做自己的一些分析,可视化是提高分析效率的重要工具。
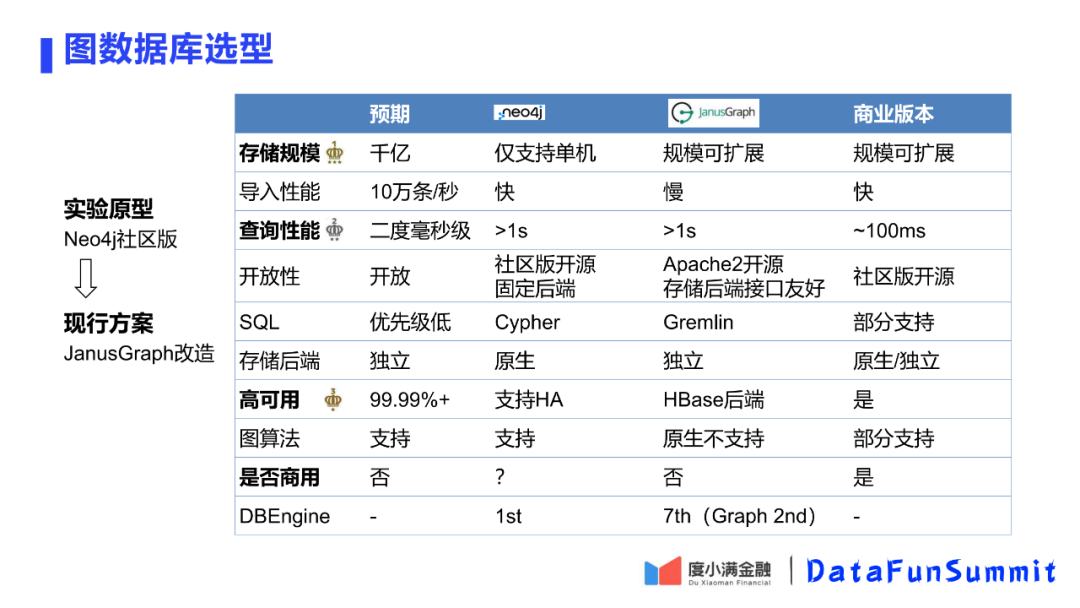
4. 图数据库选型
在内部的图数据库版本经历了演变的过程。现在是在JanusGraph做改造。下面对neo4j和JanusGraph和某商业版本数据进行一个对比。
① 存储规模
未来预期超过点边规模超过千亿,Neo4j只支持百亿,还不包括在边或节点存储实体关联的属性信息。在JanusGraph和某商业数据库上都支持分布式存储,支持可扩展。
② 查询性能
图模型最后的目标是可以在线计算的,因此要求图数据库由一个二度的毫秒级的响应能力。Neo4j、JanusGraph都有一个大于1秒的响应速度,可能JanusGraph更慢一点,而商业版本百毫秒的量级。
③ 高可用
Neo4j只有HA,但不是分布式版本;除了本身集群的健壮性还要考虑是否有很好的运维方式。JanusGraph有HBase的后端,节省了运维成本。开源版本还是商业版本,商业版本健壮性高,但是一旦出现问题是否能及时进行处理不能保证;商业版本的私有化是封闭的版本,在这上面是否能做二次开发或者更深一步的优化,这个也是待考虑的问题。最后选择了JanusGraph,主要看中可扩展性。
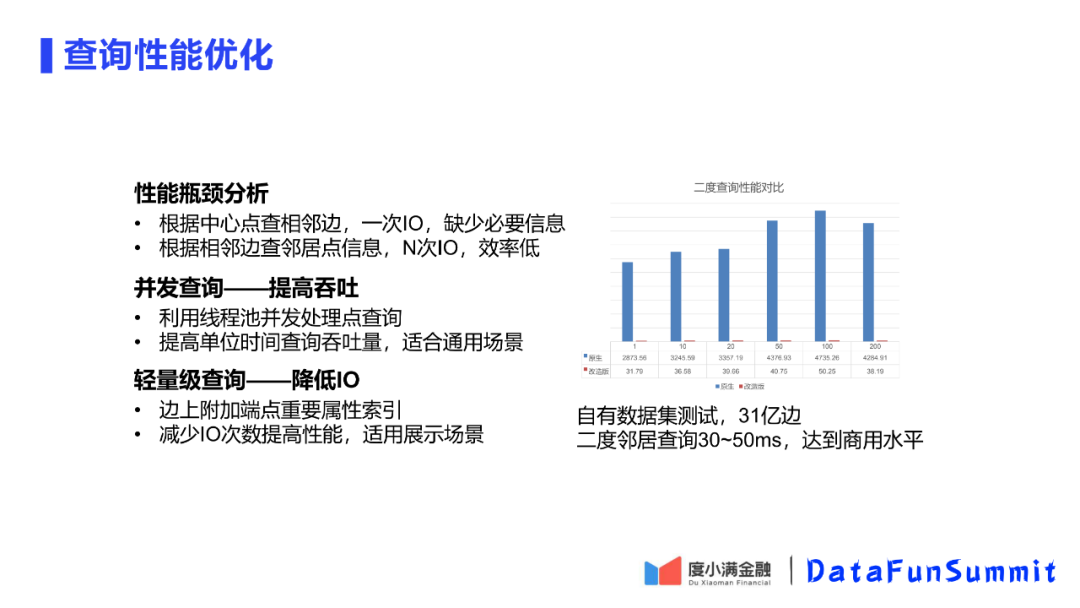
5. 查询性能优化
先看图库如何对一度二度邻居查询的。第一步,先对中心点查询边,而边上带有邻居的ID,这个查询是一次IO,这次查询可以看到一度的结构,但看不到一度的任何特征及属性信息。然后图数据库会根据查到的邻居ID做N次IO,查询每个邻居的信息。
可以看到这种查询方式效率很低。为了解决查询效率低的情况,对图数据库进行了两点优化。
① 并发查询——提高吞吐
在图数据库的第一次查询完成后,利用进程池对N个邻居使用进程池进行并发查询,从图中可以看到,可以提高几十倍的吞吐量,这种优化方式对于所有的查询场景都是适用的。
② 轻量级查询——降低IO
第二个优化点是降低IO,做轻量级查询。在平台应用场景中,我们首先呈现的是图的结构,而具体的节点信息用户需要点入再看到。这样在边索引时,我们可以将邻居节点的重要信息,例如ID加到可读的边上,减少IO的次数,这样查一度邻居只用一次IO,查二度邻居只用N次IO。这样在可视化场景可以对查询性能做一个很大的优化,表中可以看到二度查询提高了两个数量级。
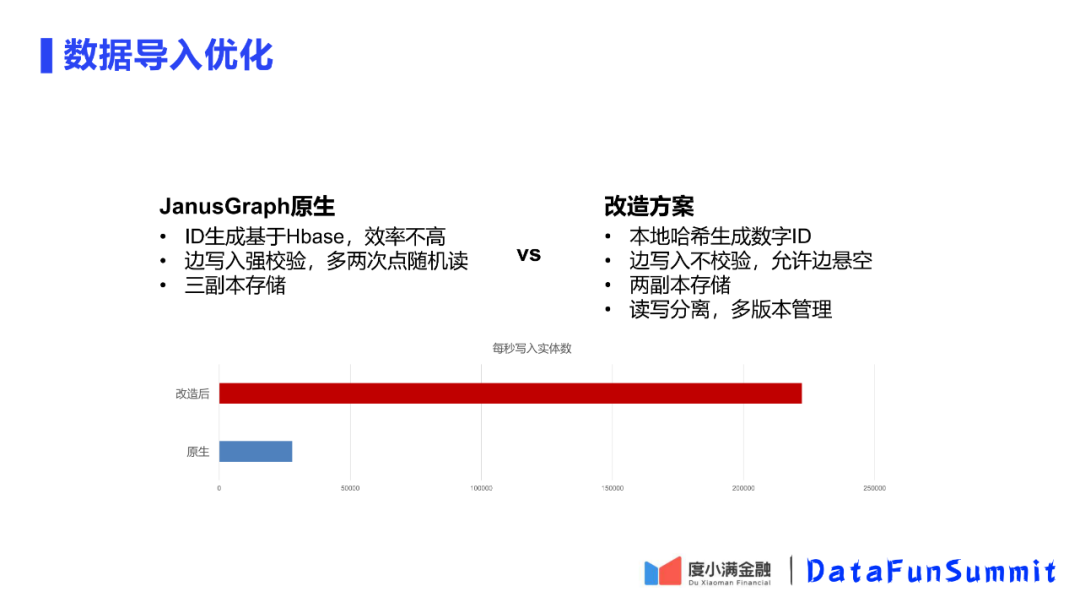
6. 数据库导入优化
在做完查询优化后,发现JanusGraph的原生数据导入其实也是比较慢的。针对原生数据导入的缺陷,平台进行了三点优化:
① 哈希生成替代Hbase生成
JanusGraph的ID生成原生是基于HBase,虽然是分布式系统,但是并没有为这么高的并发情况设计一个写入机制,所以生成效率是比较低的。
优化方案是使用本地哈希,不使用HBase。
② 允许边悬空
JanusGraph对于边写入有一个强校验机制。看一个边的两个节点是否都在图内,如果不在则认为是僵尸边,这会增加两次随机读的请求。
优化采用去掉校验,因为平台的数据入库前经过清洗的,可以保证没有悬空边或者很少,对最后查询无影响。
③ 两副本存储替代三副本存储
HBase默认是三副本存储,我们使用两副本存储,保证安全性、可用性前提下提高一定的效率。在写入时同时有读,做了一个多版本管理,读写分离开。
最后的优化效果可以达到读写每秒20w条以上,可以保证百亿边的数据可以在一天的时间内重新洗一遍。
7. 图计算
解决性能之后,讲解一下如何对图计算进行支持的,图计算作为平台的核心功能,可以提供各类图计算的能力。
图分析算法,平台集成了Graphx。Graphx对于spark和JanusGraph集成度很高,而且可以提供很多算法和计算原语,有很高的效率,有丰富的算法库可调用,在实现图算法的时候有很高的效率。
图学习功能,是基于DGL实现的。图学习包括两大类,分别是图表示学习和图神经网络。DGL也具有丰富的算法库。

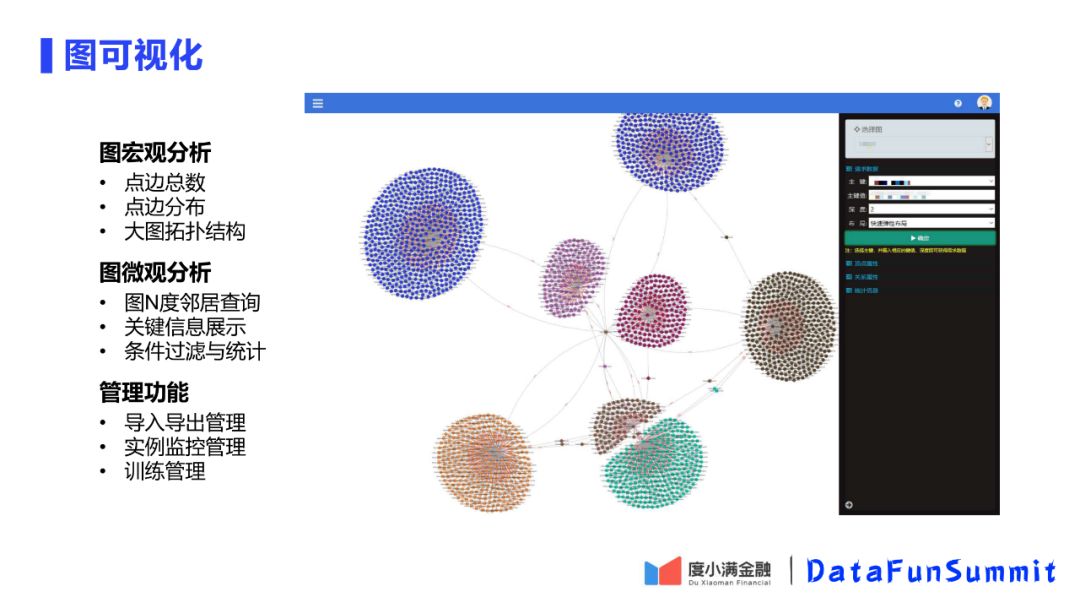
8. 图可视化
最后图平台提供了三个可视化功能。图宏观分析可以查看图的点边总数、点边分布、图和图之间的关联拓扑;图微观分析包括图N度邻居查询、关键信息展示、基于条件的过滤与统计功能,可以辅助业务分析;管理功能包括三方面,导入导出管理功能,导入就是对于上游的数据源是什么,设定导入任务多久启动一次,导出可以管理从异构大图中导出子图,实例监控管理可以查看数据分布以及健康性,训练管理可以选择模型和数据进行训练。
最根本的目的是为了解决图数据如何应用到风控模型中,所以第部分重点讲如何将图数据放到模型数据中应用。
1. 图模型-理论与现实
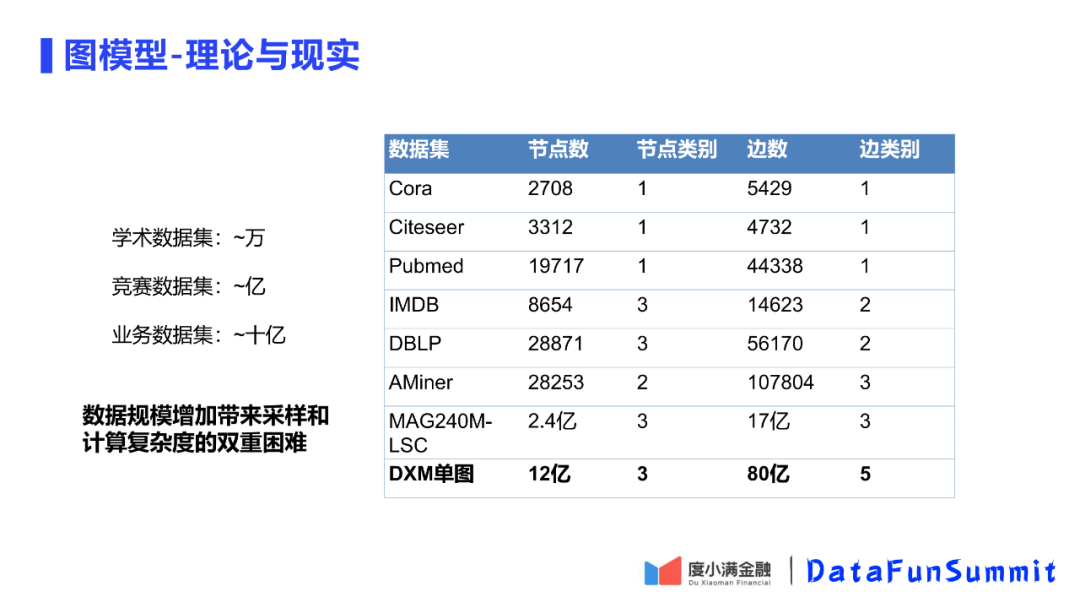
首先看一下实际遇到的问题与公开数据集的差异。表中前6行是公开模型数据,前3行是同构图数据、后3行是异构图数据。学术数据规模在10w以内,第7行的比赛数据,达到了亿级规模,这对于学术界是超大规模了。但度小满单个模型训练的数据集已经达到了10亿级别,比比赛的公开数据集又大出一个量级。所以学术数据集、竞赛数据集、业务数据集有一个巨大的鸿沟。另一方面图的数据是有关联的,例如Node2vec的邻接矩阵,当点边关系增加,矩阵规模会膨胀迅速,因此在训练中如何解决规模问题是训练中要考虑的重点。
2. 学习框架选择
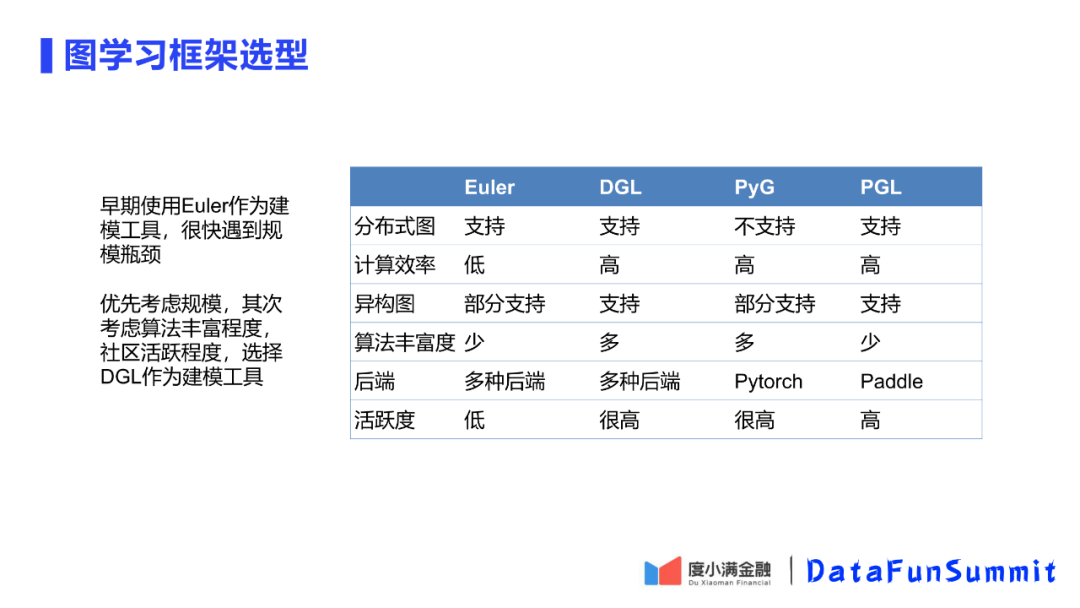
对于图学习目前没有完全成熟的框架,度小满最早使用Euler作为建模工具,但是很快到规模瓶颈。最后选择了DGL作为建模工具。在建模工具选择时,最优先的考虑就是是否支持大规模学习,因此排除掉了PyG,虽然该模型工具在学术界流行,但无法支持分布式训练。
3. DGL性能规模存在问题分析
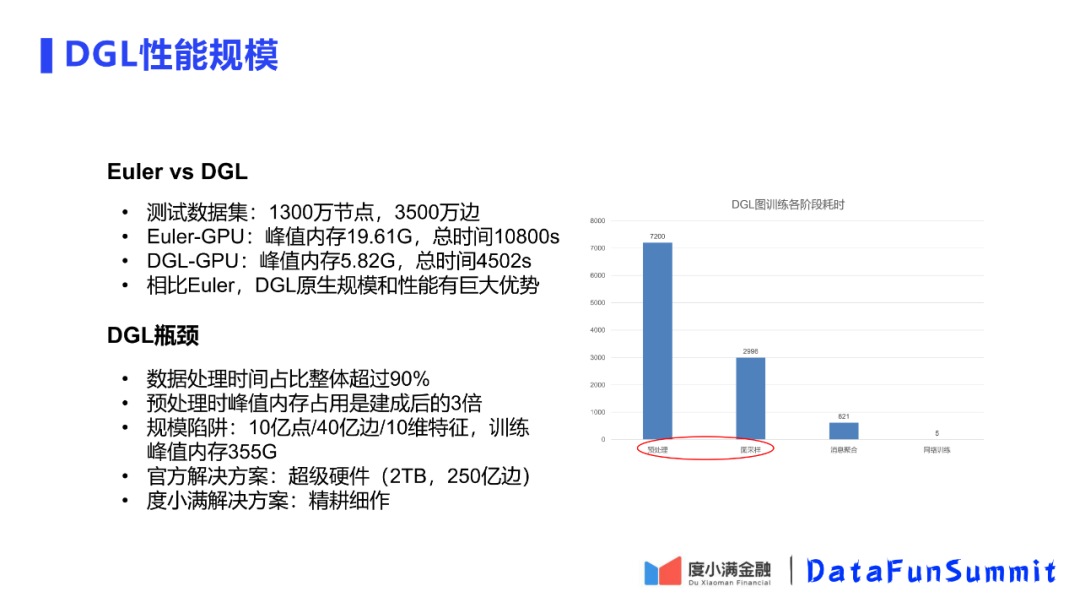
下面具体分析早期使用的Euler框架和最后选择使用的DGL框架的区别。可以看到DGL的占用资源和运行时间都只有Euler的几分之一。因此DGL有规模性能优势。
但DGL框架本身也存在一些问题,并不是完美的。
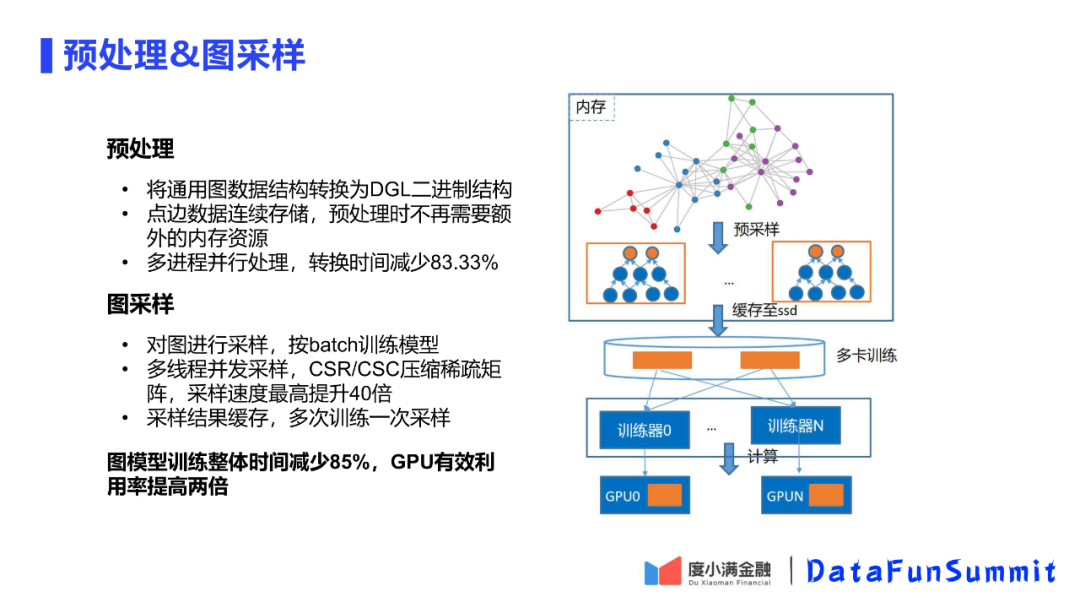
对于一个基于DGL的完整训练,首先要对图进行预处理,将图结构处理成DGL存储的二进制的结构,这个过程需要对数据进行采样,将每个batch所需要的数据采样出来,对这些数据进行聚合,最后才是将数据应用于DNN等模型训练的过程。
通过分析统计整个训练过程的时间性能,发现预处理和采样这两个过程会占到DGL图训练整个阶段的时间的90%以上。而此处还有一个规模陷阱,在预处理时所需要的内存空间是与处理后数据所需内存空间的3倍。虽然对于DGL官方依托于AWS使用了一个超级硬件来解决这个规模陷阱问题,但是这对于大部分的公司无法使用到这样的硬件,对于度小满来说需要对整个过程做一个精耕细作的优化。
4. DGL预处理和采样阶段的优化
首先是对DGL训练预处理和采样阶段的优化。经过两步的整体优化后,减少了85%训练时间,提高了GPU利用率。
① DGL预处理阶段优化
DGL在预处理阶段并非使用的连续存储方式,而是使用的类似链表的存储结构,会浪费很多存储空间。经过对存储方式的修改后,发现预处理阶段不会比训练阶段更多了,保证了只要满足训练阶段的内存大小即满足各阶段内存需求。
② 多进程并行处理
在采样阶段第一个修改是对压缩矩阵进行一个多线程并发,可以提高40倍。进一步优化,考虑使用不采样思想,对同样一份图数据,对采样数据进行缓存,训练时只加载采样缓存,节省采样过程。
5. DGL分布式训练的支持优化
单机再优化,性能也是有上限的,所以需要分布式的训练支持。图训练方面DGL原生支持分布式;图分割方面,DGL虽然没有直接支持分布式,但是推荐可以使用parMetis对大图进行分割。
但是DGL的分布式训练本身会存在一些问题,数据分片之后,ID会进行重分配。需要能从新的ID找到原来的global的一个GID,因此需要存储一个映射表。映射表使用的是Key-Value的查询方式,对于100亿边的图所需要的映射表内存占用为160G,因此映射表就会吃空资源。
平台对此问题进行了改造优化,将图分割映射表改为了区间映射表。在图分割之后,在ID重排的时候,将ID的分配成连续的ID,通过这种方式,只需要保留边界处的偏移就可以还原出原ID。在此基础上实现了规模的突破。
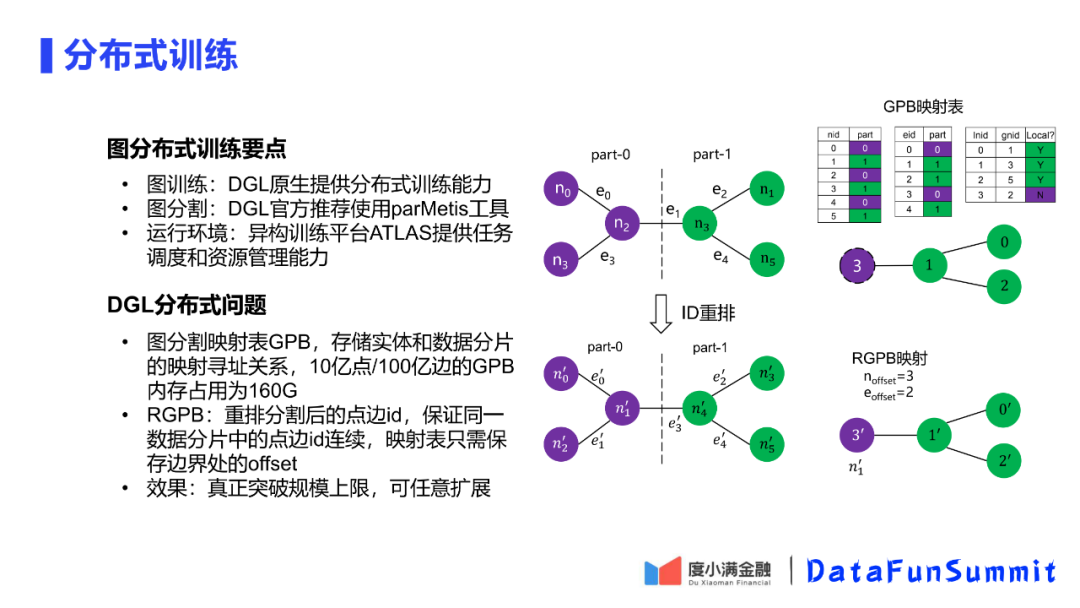
6. DGL异构图的优化
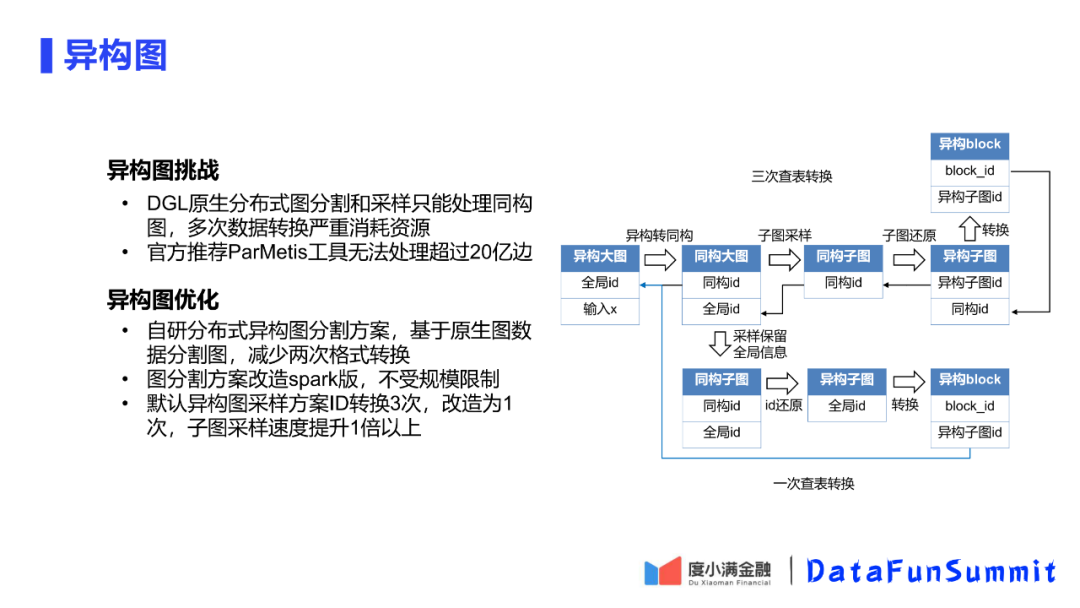
生活中,业务中的大部分数据都是异构图,只有少部分是同构图。
对于DGL只支持同构图,因此训练时需要将异构图转换为同构图。同构图和异构图的相互转换会消耗资源。官方推荐工具无法处理超过20亿的边,因此无法满足需求。
度小满通过自研的分布式图分割方案解决了这一问题。基于直接导出的图数据进行分割,这样可以减少两次转换过程,同时该方案被改造部署在了spark上,因此可以不受规模限制,可以运行任意规模分割。另外在异构图的采样过程中,将DGL推荐的效率较差的多次转换的方案进行了优化,改造为了1次,从而提升了采样速度。
第三部分讲解在平台部署图模型遇到的问题及解决方案。在部署阶段,主要会遇到一致性、时效性和效率三方面问题,下面介绍遇到的问题以及度小满的解决方案。
1. 在线风控模型
首先讲解一下在线部署的风控图模型的基本情况。该模型的业务背景是信贷风险分析,判断用户好坏。模型引入了实体和实体的联系,包括人和人、人和公司关系。整个图是一个异构图,具有12亿顶点与80亿边,而其中每个人又选择了94维以征信为主的特征。
右边的图展示了模型架构,设计了一个双层的GraphSAGE和GAT融合的模型,首先在模型的右边会将图深度为2的信息进行聚合,然后向右使用Node Attention机制对一个类别内的邻居信息进行学习得到表征,然后对不同类别的信息再使用Heter Attention机制进行交叉学习,最后得到一个对于中心节点的基于图的深层学习表示。
整个模型的效果对于AB卡的业务会有1%以上的提升。
但是此处会存在几个问题。首先是如果一般训练得到模型后,会对已注册用户进行离线打分,但是对于新用户没有任何信息,那就无法对新用户打分,而且将小模型集成到大模型中时,会存在覆盖率缺失的问题。因此需要把图进行线上部署,将它的计算变成在线的。
那么,在线部署,就会引出一致性、时效性和效率,这一系列相关的问题。

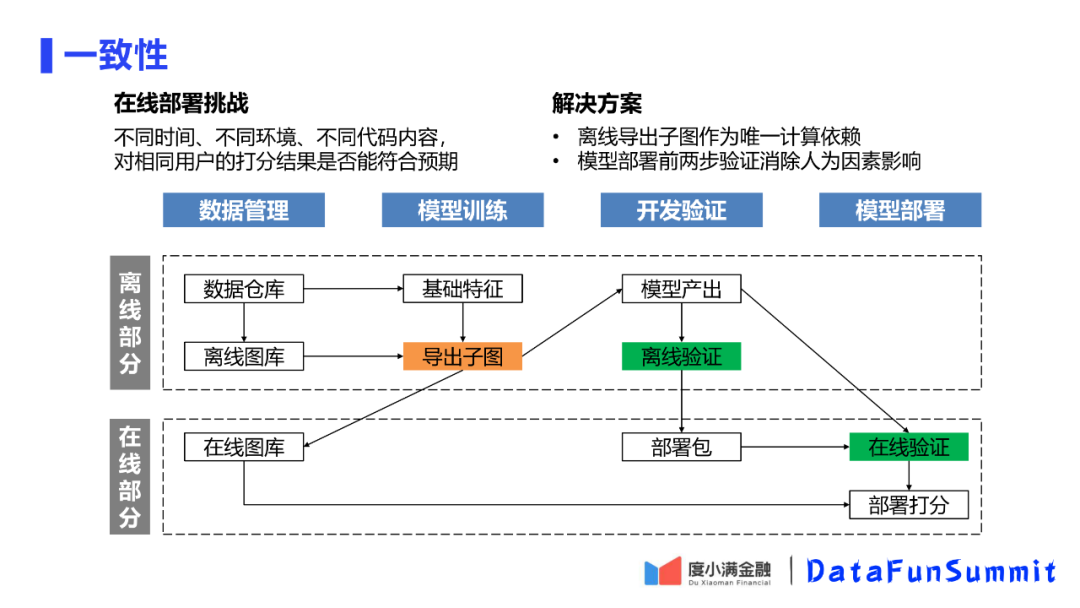
2. 在线部署一致性解决方案
离线模型和在线模型对比,打分的时间、代码、环境等方面都会不同,那么在线模型的结果是否和离线模型结构一致?
首先可以将整个在线打分的过程分为离线部分和在线部分。其中关键的部分是将数据仓库以及离线图库的导出子图作为离线训练和在线打分唯一的数据来源。既用于离线训练,也用于在线的数据导入。另外在部署模型包前要先做一次离线验证,保证本地打分与训练的结果是一致的。在模型部署上线后,也进行一次在线验证,保证在线环境得到的分数也和预期的一致。用数据一致性和计算一致性保证在线打分的一致性。
3. 图深度与性能问题
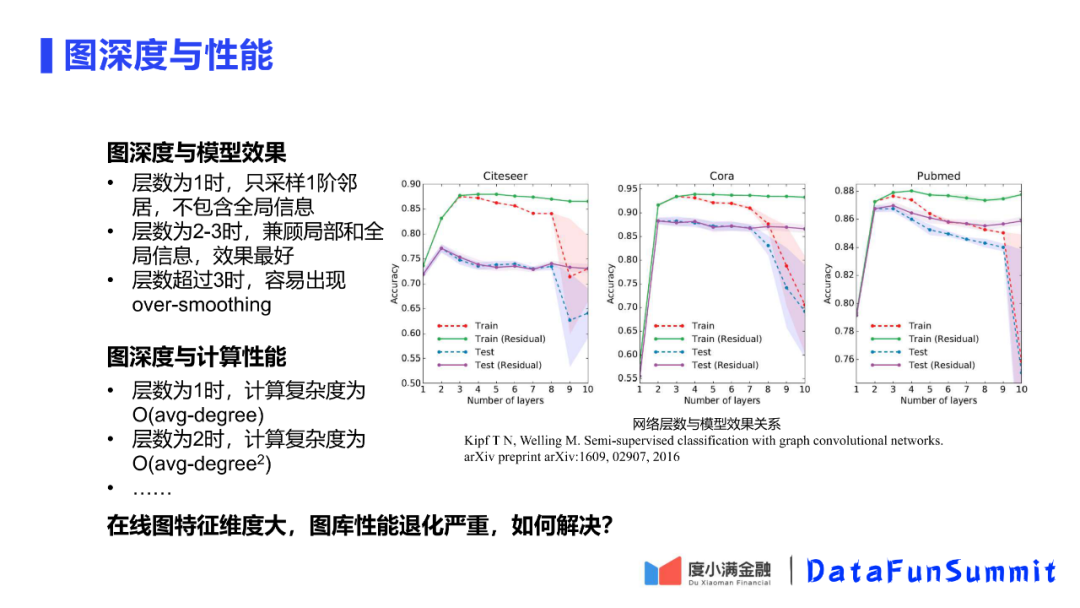
刚才讲到图模型的采样深度是两层的,这里引用GCN文章的一个评测结果进行分析,为什么会选择两层的采样深度。
当层数为1时,只采用一阶的邻居,只包括了节点周边的信息,而没有图的全局信息,对图采样是不充分的,无法学到很好的信息;当采样层数为2、3时,文章结果表示此时可以兼顾全局与局部,模型训练的效果是最好的;当层数超过3时,会出现over-smoothing,也就是说层数过深,得到的采样结果都是一样的(比如六度空间理论,通过6个人就可以认识所有人了),因此学习到的结果也就是一样的。
那么采样的深度又会给图计算的性能带来什么问题呢?
当层数为1时,复杂度是O(avg-degree);当层数为2时,复杂度为O(avg-degree2),图库的性能就会退化严重。
4. 图深度与性能效率优化
图模型的训练预测阶段与图的展示阶段不同,这里的2层深度信息是实时需要的,而具体的信息特征也需要知道,因此这是一个更高复杂度的问题。
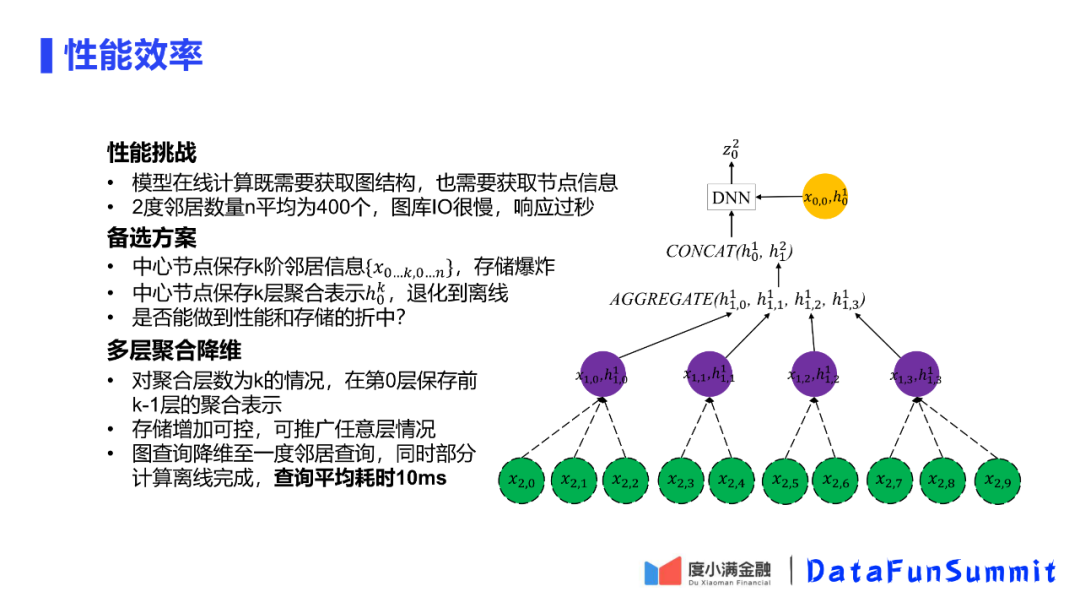
经过分析发现,2度邻居的数量平均有400个,这就需要400次IO,这对于任何数据库响应都需要过秒。
对于这种情况,可以从三个角度考虑。首先是是否可以使用空间换时间,直接在中心节点保存2度邻居的所有信息,这种方式会导致存储爆炸400倍,因此这种方式不可扩展;第二种方案是在中心节点保存2度聚合的结果,但是这种方式与直接将模型进行离线计算是没有区别的;第三种角度考虑是否可以将性能和存储进行折中考虑。
如图中的h01,上标表示第1层的聚合结果,下标表示是第0层的节点,而第0层节点表示的就是中心节点。度小满考虑的方式是对在倒数第二层保存以下所有层的节点的聚合结果。这样既不需要保存所有原始信息,也可以将查询缩减到查1的情况,从而得到性能保障。在真正模型计算时,对于中心节点,会对所有邻居节点进行聚合表示(上标为1),然后将该表示结果与中心节点的第一层聚合结果进行拼接,然后将结果放入DNN,最后得到期望输出Z02。
这样既保持了存储空间可控,最多增加一个存储节点情况下,可以推广至任意聚合K层的情况。可以保证在查1度10ms的情况下,完成在线的计算打分。
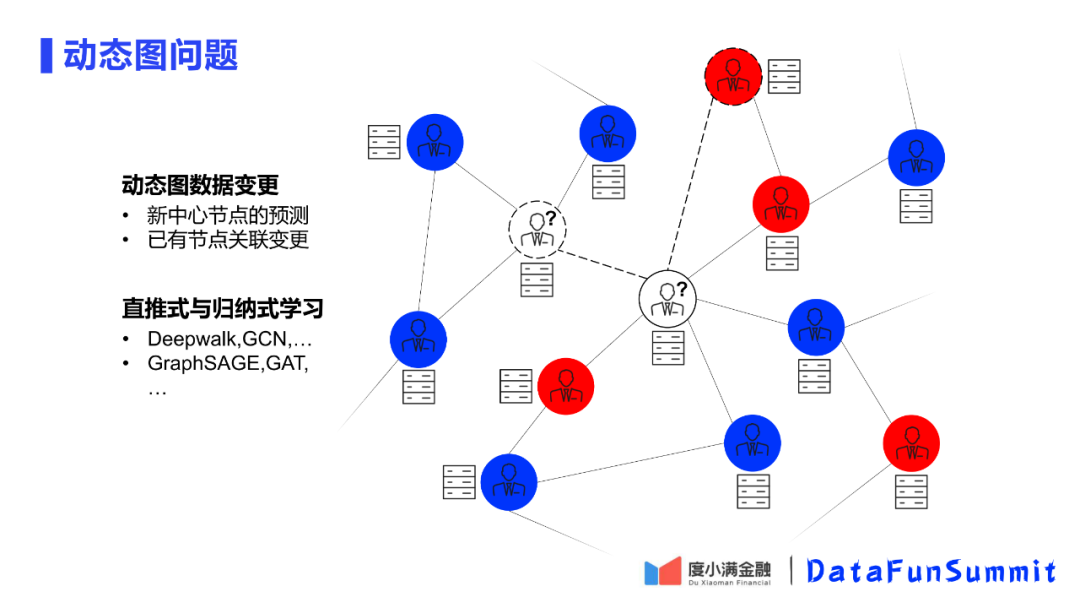
5. 动态图问题
在前面提到在线部署会存在用户节点在线变化的问题,这里存在两种情况。第一种如图中的左边白色节点,本身就是更新了一个新的中心节点;第二种如图中的右边白色节点,该中心节点已经存在,但是它的关联信息发生了变换,比如和其他节点建立新的边。
同时为了支持在线计算,平台使用了归纳式学习模型。
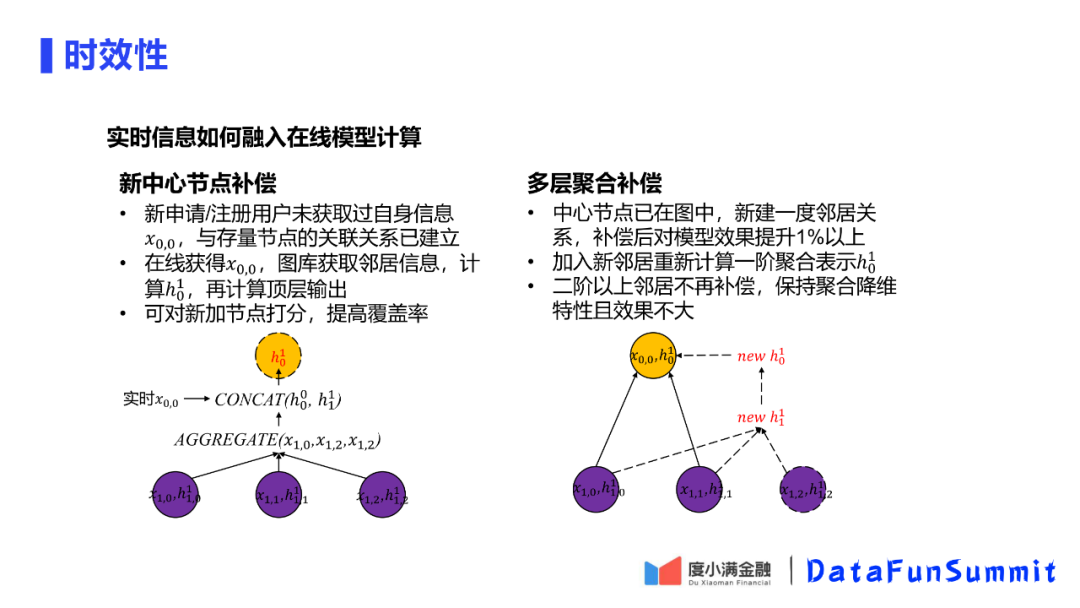
6. 动态图的时效性优化
对于新的中心节点的补偿,根据邻居节点的一阶和二阶的信息,重新计算中心节点的一阶、二阶的图表示,相当于一个重新打分的过程。这样可以做到一个对中心节点的无损打分。
对于多层聚合补偿,如果是建立新的关系,只聚合一阶邻居信息,而不需要再计算二阶邻居信息。

最后对整个图平台的建设进行一下总结。
首先,在建设过程中发现图数据的复杂性会给规模问题带来新的挑战,这与传统的数据不同,传统数据一般是线性增长,而图数据可能会有爆发式增长的情况,在解决这类问题上要多采用降维的思想,另外可以考虑使用并行、缓存等方法,最简单的方法可能是最有效的。另外在建设平台过程中,需要针对实际的场景设计方案,如果设计的方案在实际的训练、结果过程中有一个好的表现,那么它就是一个好的、适用的方案。
未来,会在建立的图平台的基础上,挖掘更多的数据,希望可以实现到千亿的规模,也期望有更多的应用;另一方面我们会将图平台和图模型进行更好的融合,从而降低图学习应用门槛,让图平台更高效的应用起来。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“图计算” 就可以获取《图计算专知资料》专知下载链接