分享嘉宾:周玉驰 贝壳 资深算法工程师
文章整理:许继瑞
内容来源:贝壳找房知识图谱技术大会
出品平台:DataFun
注:欢迎转载,转载请在留言区留言。
导读:
贝壳找房积累了大量房、客、人的行为关系数据,我们通过关系图谱的相关技术对这些行为关系进行挖掘,并在实际应用中取得了不错的效果。本次分享将主要介绍关系图谱在贝壳找房的构建历程和落地应用探索。
1. 关系图谱的基础建设,包括:关系图谱的基础数据建设,关系强度量化,子图抽取的方法(异质网络和同质网络)
2. 关系图谱的能力,包括:节点影响力和Graph Embedding
3. 关系图谱的应用探索
从第一行可以看出,贝壳的客户、房数量较大,每日新增也很大,经纪人增长也很快,小区相对稳定,增量不大。第二行是2019年贝壳找房房产行为数据。如何从如此庞大的数据中得到有用于决策的信息,是我们现在要做的工作。用什么方法挖掘数据背后的价值?我们想到了关系图谱。
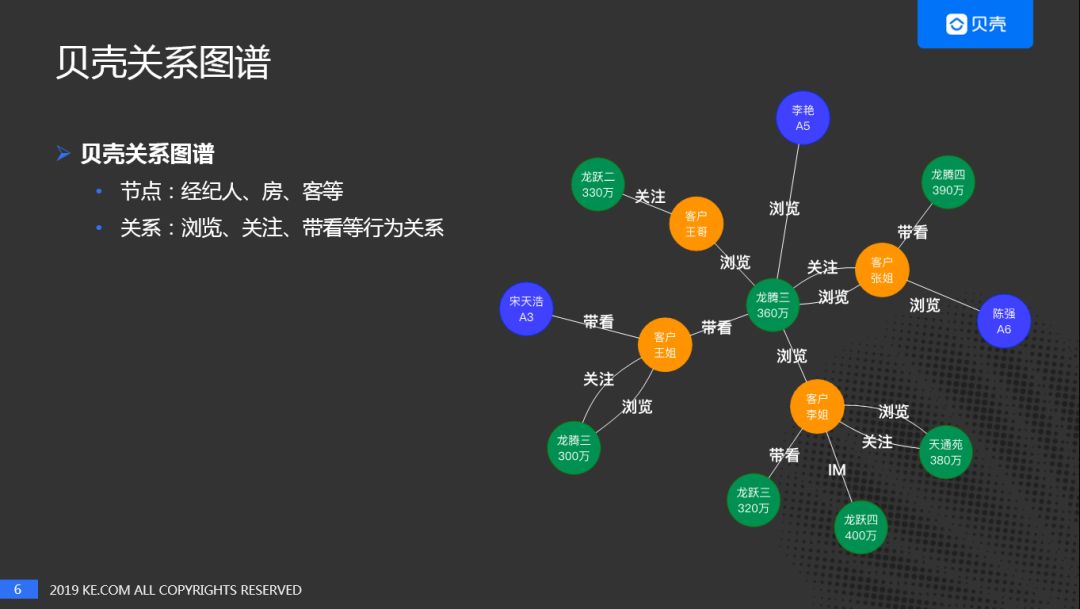
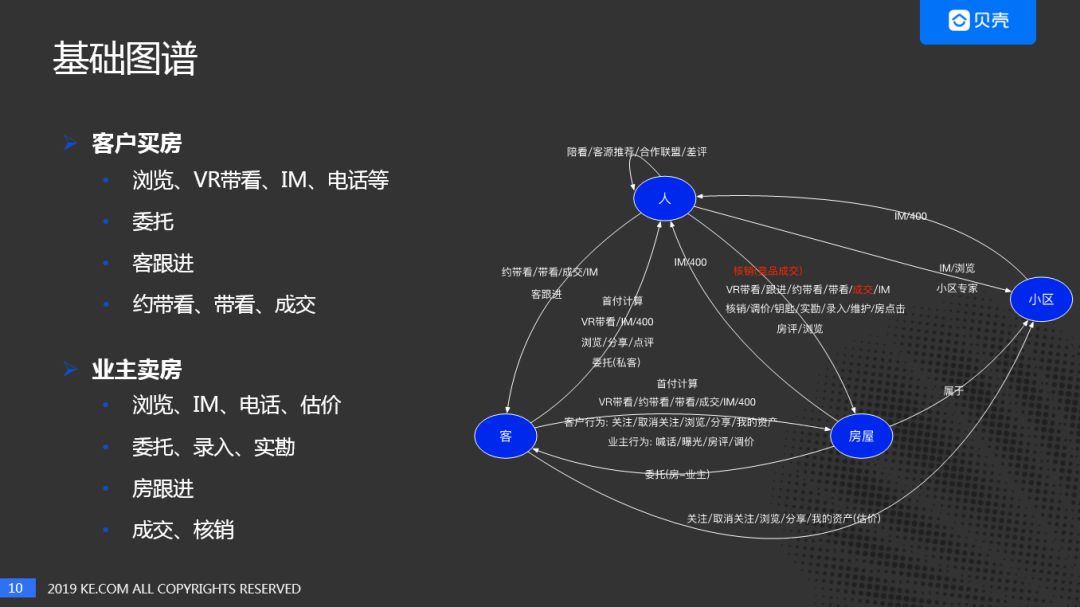
"关系图谱"在业内通常也叫"网络图谱",上图展示了贝壳关系图谱的实例。实例中,节点是:经纪人、房、客人等。关系:浏览、关注、带看等行为关系。有些是常见的行为,有些是贝壳找房独有的行为,如:带看,等。
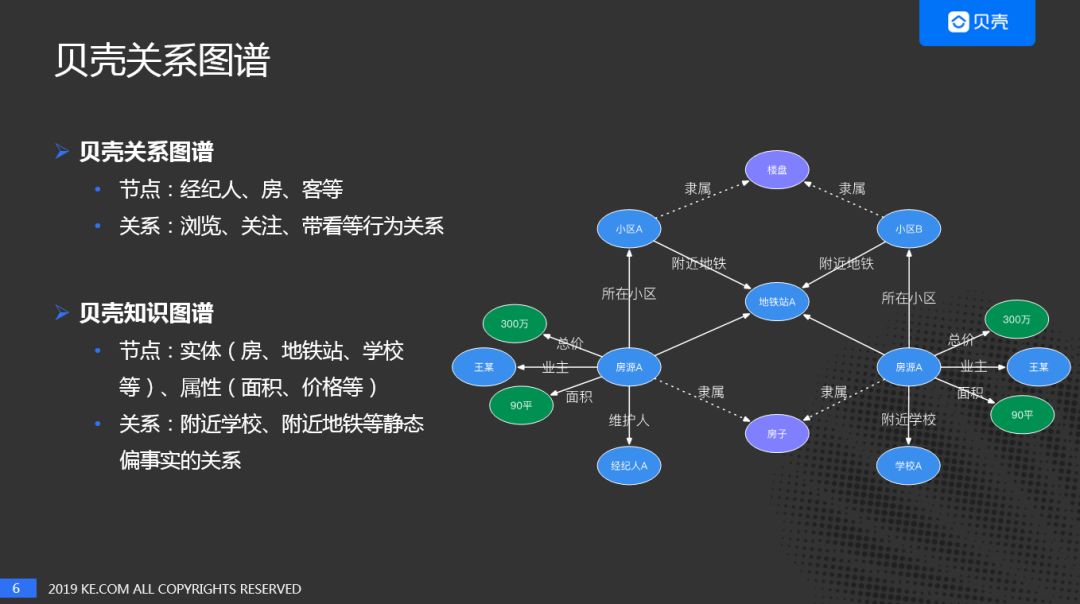
关系图谱与知识图谱的差异,首先看下贝壳知识图谱的示例,节点是:房、地铁站、学校等,关系是附近学校、附近地铁等静态的关系。关系图谱更偏向动态的行为网络而知识图谱更多的是偏实时的静态的知识网络。
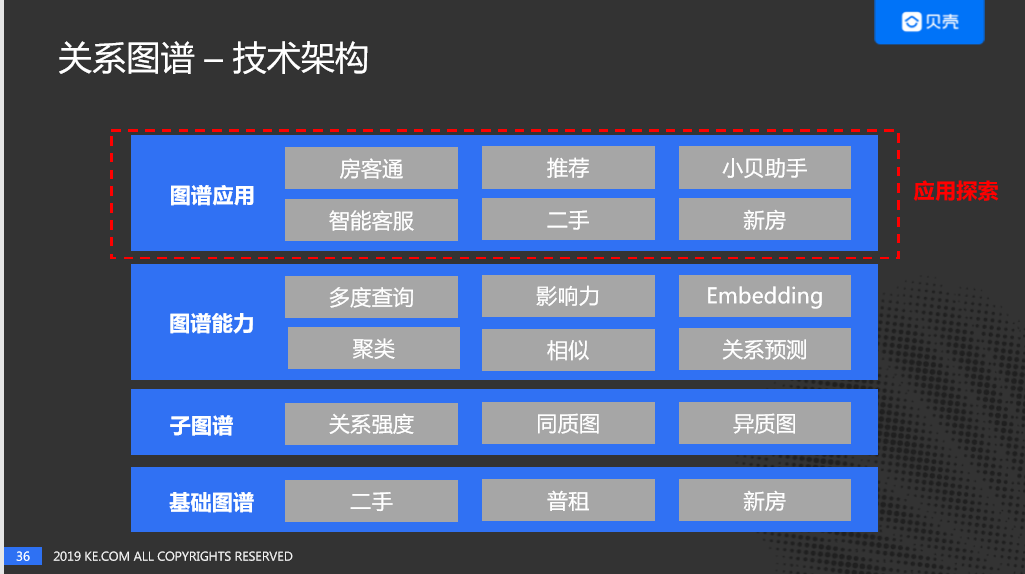
介绍完基本的关系与节点,下面来讨论一下,如何从0到1搭建关系图谱。在这个过程中离不开三个核心:关系图谱能做什么?如何设计?如何应用?下面以贝壳关系图谱的整体技术架构为切入口,为大家详细介绍下:
贝壳关系图谱的技术架构,自下而上分为:
基础图谱、子图谱、图谱能力、图谱应用。
基础图谱
:
基础图谱定义了各种行为的关系。基于基础图谱构建了子图谱。
子图谱:
基于基础图谱构建了子图谱,分为同质图和异质图以及关系强度。同质图是节点、实体和关系,是同一种类型的。在构建子图谱中,有一个非常重要的过程就是关系强度的量化。
图谱能力:
基于子图谱,贝壳进行了图谱能力的建设。
包括:
-
-
-
-
聚类,有社群发现的算法也有基于Embedding 的聚类;
-
相似,比如相似房源等,也是基于Embedding 来计算的相似;
-
图谱应用:
基于关系图谱的能力,进行了关系图谱应用的探索,这个部分会在后面介绍。
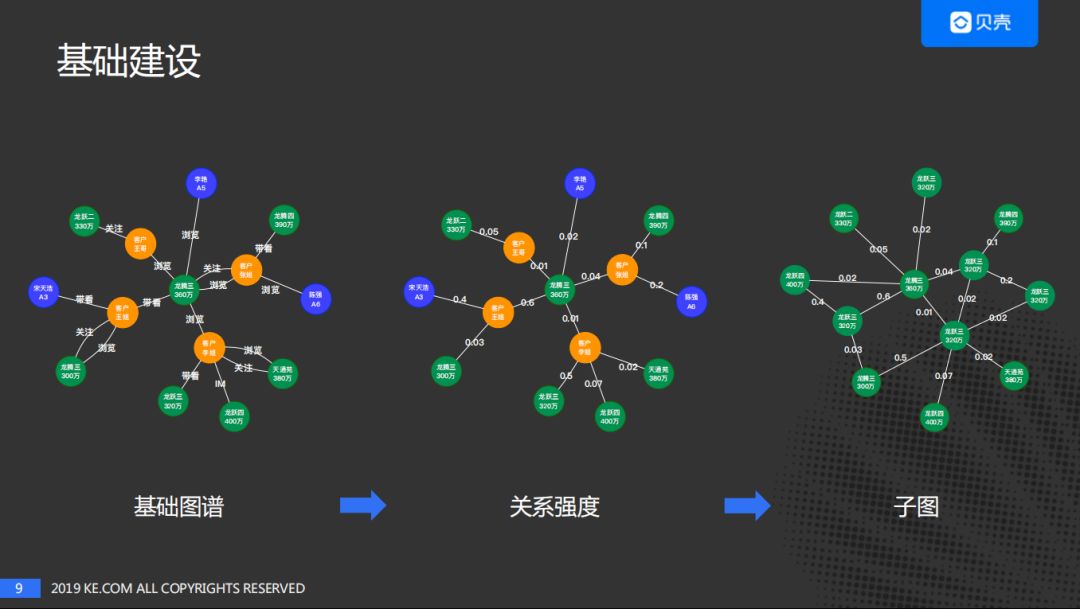
先探讨一下基础建设部分,包括:基础图谱及子图谱。我们首先建设基础图谱,然后量化关系强度。在量化关系强度之后,两个边之间的内容由关系变为数值,值越大表示两个节点直接的关系变的越紧密。关系强度可以做一些直接的应用,如客户偏好的计算,也可以用来做子图的抽取,基于子图做一些应用。
上图中的子图是一个房子关系图谱的示例,节点全部都是房子,房子之间的强度被量化成数值。
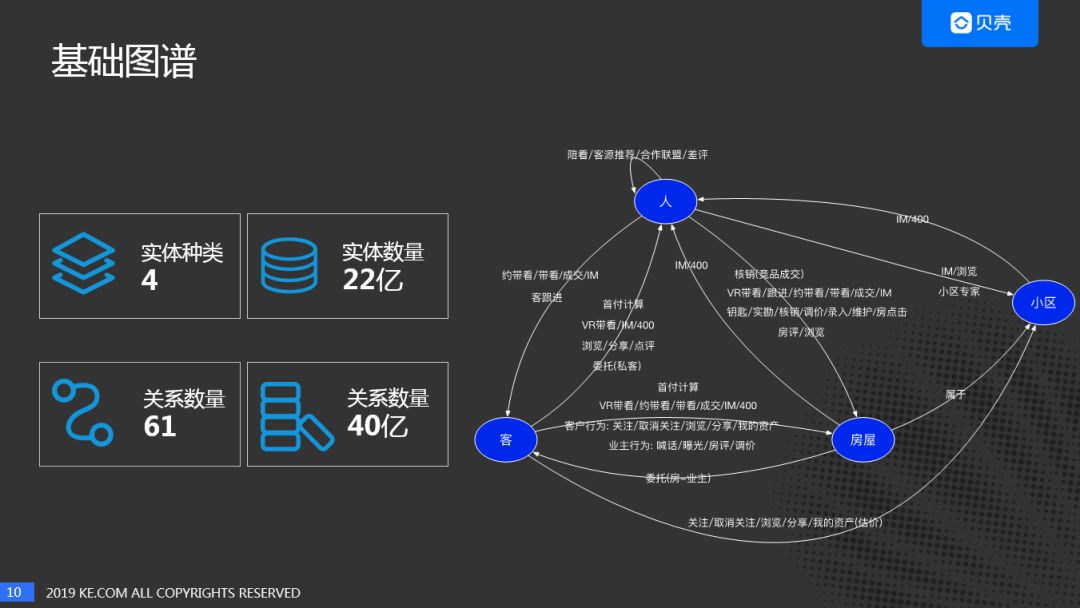
贝壳二手房关系图谱,如下图所示。有四个实体,人:经纪人,客:客户/业主,房,小区。实体数量22亿,关系数量有61种,40亿。
下面通过两个流程,了解关系图谱中实体之间的行为关系。
客户首先到贝壳App上浏览房源,可以通过App体验贝壳VR带看,如果想进一步了解房源可以通过IM、电话聊天等方式咨询经纪人。如果客户对经纪人比较满意,可以进一步合作,成为该经纪人的私人客户(其他经纪人无法看到此客户信息)。经纪人负责后续跟进,带看,成交等活动。
业主通过贝壳App浏览房源了解市场行情,通过IM、电话联系经纪人,也可以通过贝壳估价评估业主房子的大致价格。在业主确定房子出售时,可以把房子委托给贝壳,有专门的经纪人对房源进行录入及实勘。房源维护人会经常和业主联系,了解目前业主对房屋出售的意愿,判断业主是否愿意降价等。如果通过贝壳出售了该房子则达成成交,如果被其他中介出售房子,也需要及时的核销。
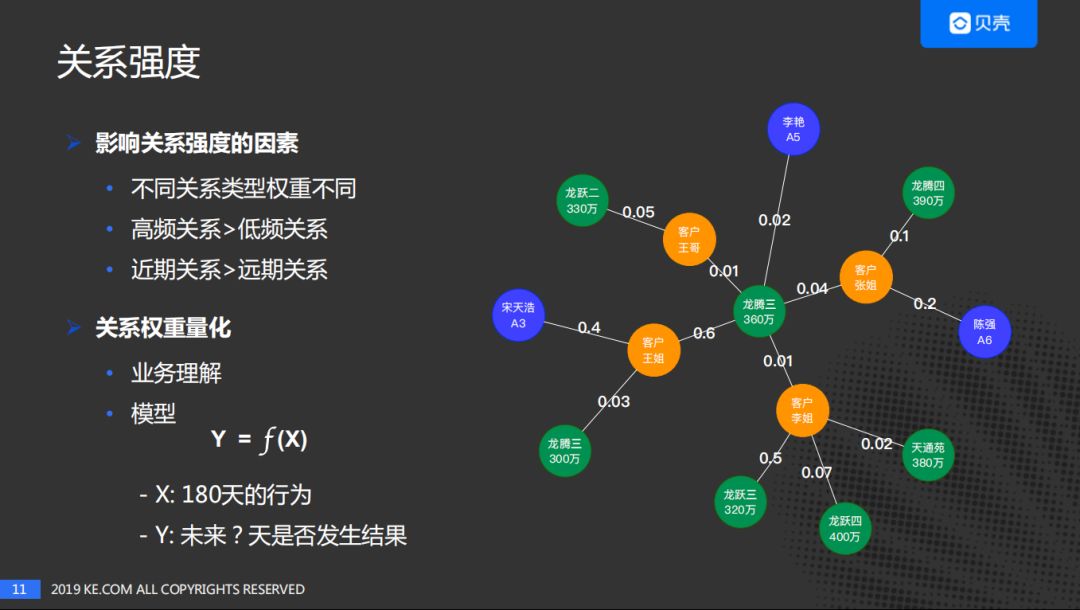
在基础图谱的基础上,量化各节点的关系强度。最主要的影响因素有:
-
不同关系类型的权重不同:如带看的强度大于浏览的关系强度;
-
高频关系>低频关系:当一个行为发生的频率越高其对应的关系强度值越大;
-
近期关系>远期关系,离当前时间越近强度就越大,会做一些时间维度的强度衰减。
-
基于业务理解,结合数据生产的漏斗,定义了不同关系类型的权重。
-
采用模型化的方法进行计算,以成交为目标,已导致成交的因素为特征来进行预估。但是这种方法只能对部分关系进行量化,如有的行为,行为量比较少,不足以成为影响成交的行为,且有些关系和成交没有直接关系。模型化的方法主要是对用户行为及业务理解进行交叉验证。
下面介绍下房子的关系图谱是如何进行构建的,有两种方法:
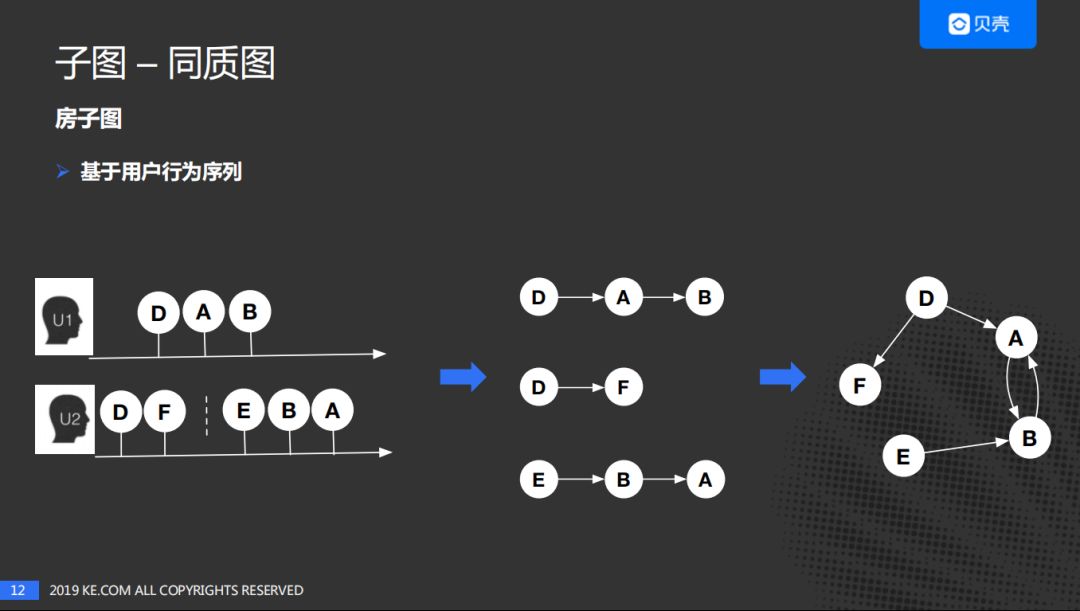
假定一段时间窗口内,用户先后浏览了一些房子,依次可以建立关系。主要考虑两点,一是用户的兴趣短时间内不会发生偏离,二是考虑计算资源的成本。
用户1先后看了DAB三个房子,用户2分两个时间段分别看了,DF及EBA房子;我们由此推断,对于用户1可以由D到A,A到B建立联系;对于用户2,第一个时间窗口D到F及E到B,B到A可以建立联系;最后进行聚合可以得到第三个图,就是房子的关系图谱。
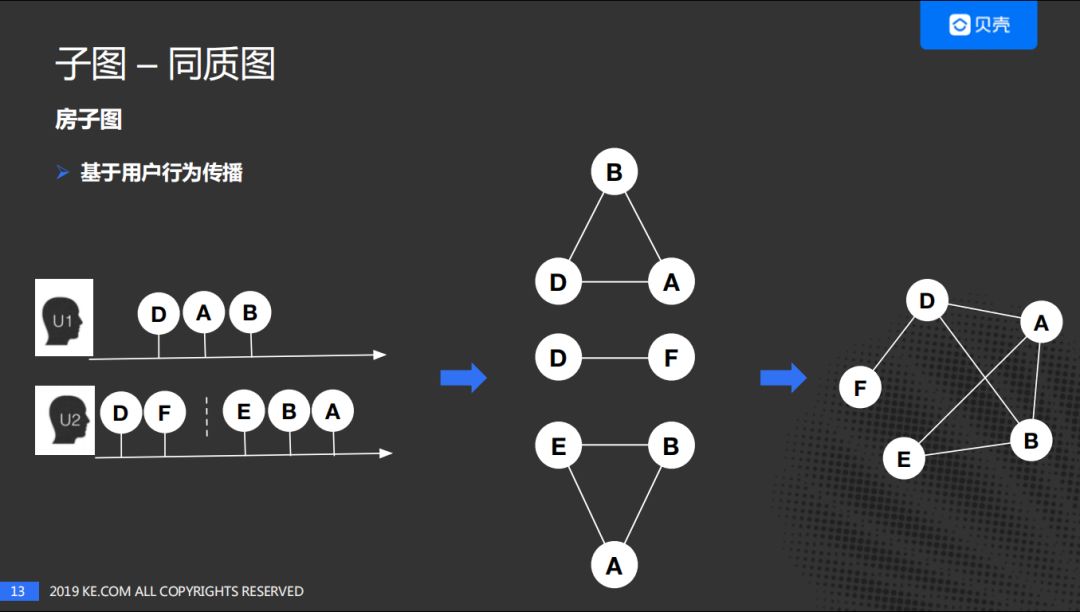
进一步,假定在这个事件窗口期内用户的兴趣不变,我们认为用户的行为可以进行传播,即在事件窗口期内用户浏览的房子可以在两两之间建立联系。最后进行聚合得到最后的图谱。类似于协同过滤的思路。
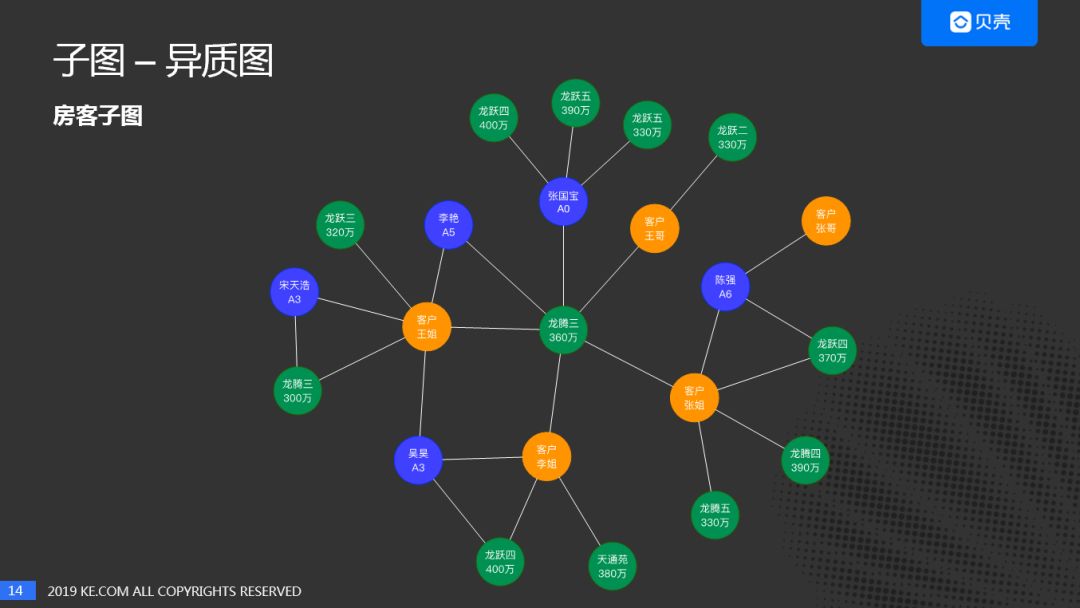
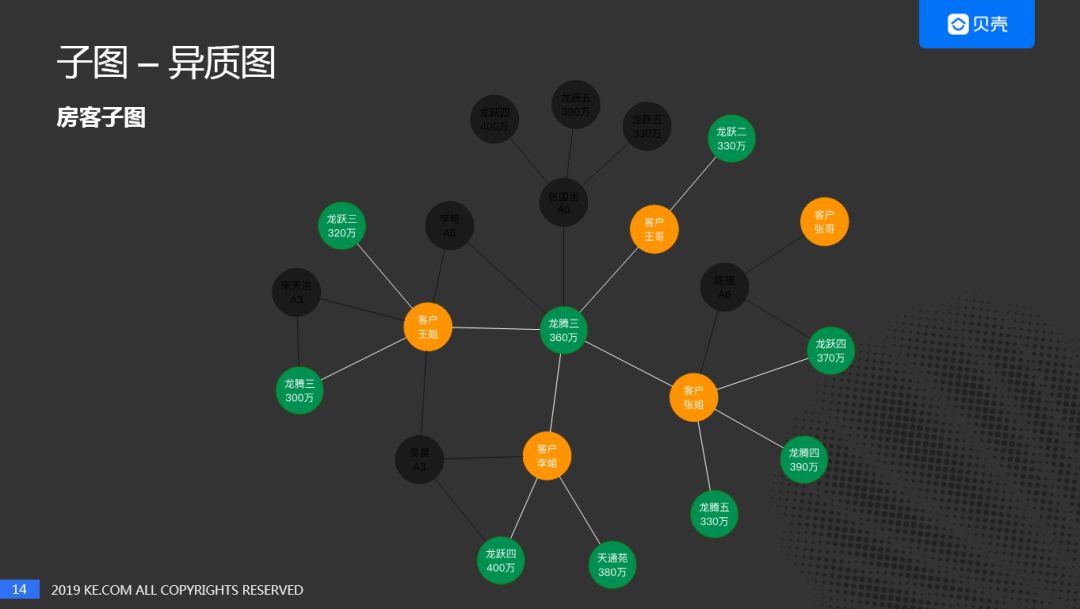
我们社会中的网络,大部分都是异质图。在我们这边首先研究的是房客子图,为什么选择房客子图?主要因为我们的图谱中是有经纪人的,考虑到房和客的特征和偏好存在倾向性。一个想要买房子的客户对目标房子的面积和价格是有预期的,同理房子的特征也是确定的。对于经济人来说,对房子的价格和面积是不介意的,可以卖任何价位和任何面积的房子。
房客子图的抽取方法比较简单,就是我们图谱中的一部分,再加上关系量化的过程。
基于子图谱的建设,我们进行了图谱能力的建设,主要介绍四种能力:影响力、Embedding、相似、关系预测。多度查询就是图数据库的查询,就不做专门介绍了;聚类在实际中暂时没有合适的落地场景,也不做介绍。
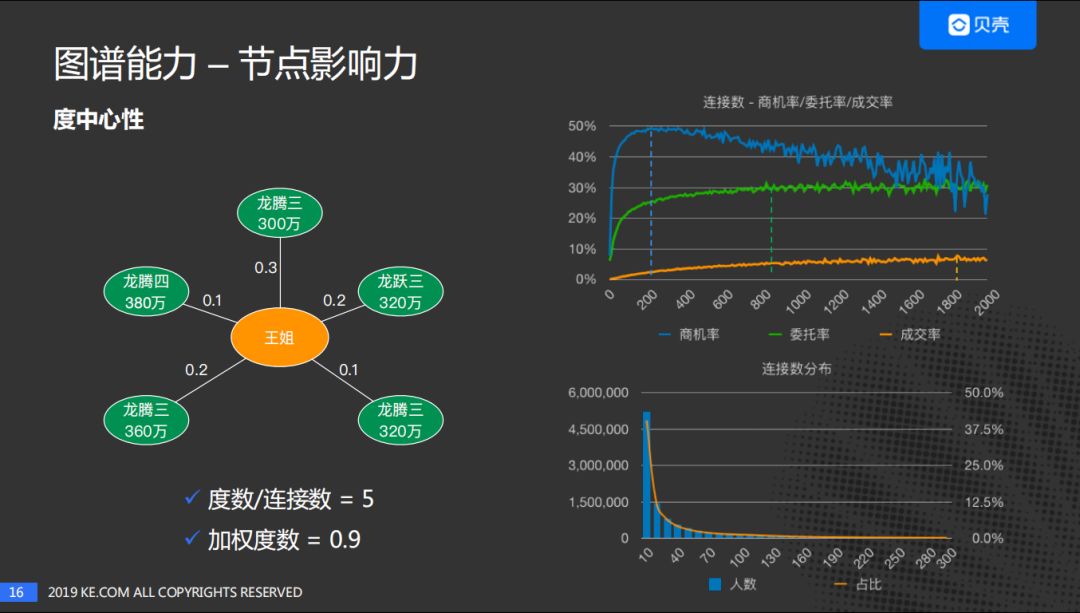
节点的影响力反应了节点的强度,我们采用了度中心性的办法。度中心性就是一个节点的度数/连接数/边数,当然,大家可也以选用PageRank。我们以图中的"王姐"为例子,周围的边是5条,度数就是5,加权度数就是考虑这些边的强度,对边的强度进行加和。
-
右上图,是连接数和转化率之间的关系。横坐标是连接数,纵坐标是转化率。可以看到连接数在一定范围内,连接数越大转化率越高。
-
右下图,连接数
与客户数量关系分布图。可以看出大部分用户连接数比较低:40%的用户,与房的连接数小于10;大约80%的用户,与房的连接数小于140。
从这两个数据可以看出:贝壳平台需要增加用户的连接数。增加连接数,可以增加用户的转化率。这也是贝壳平台需要做的事情,也是我们平台的价值。
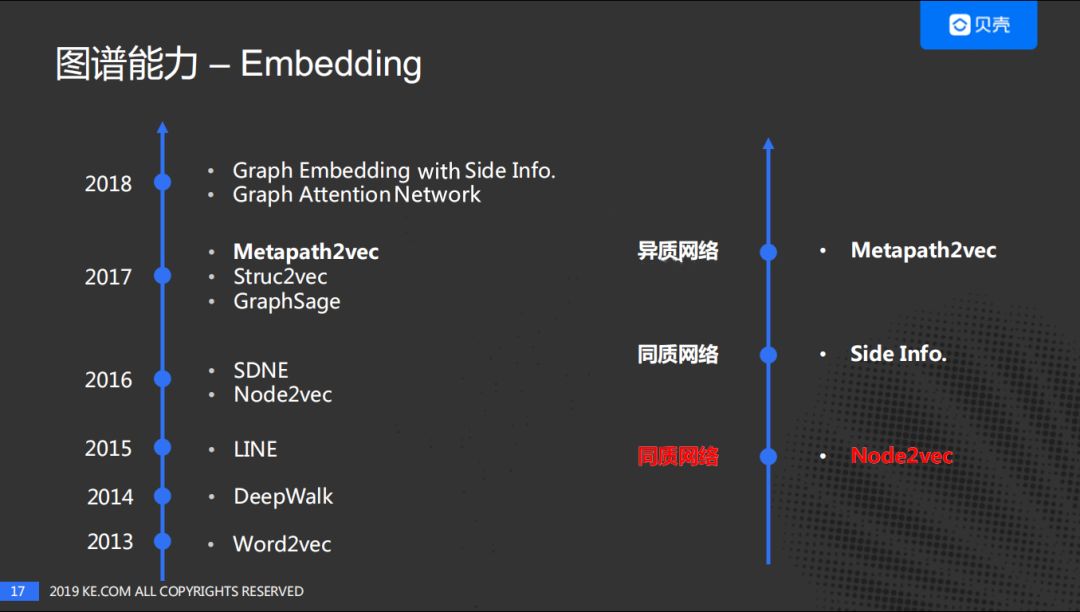
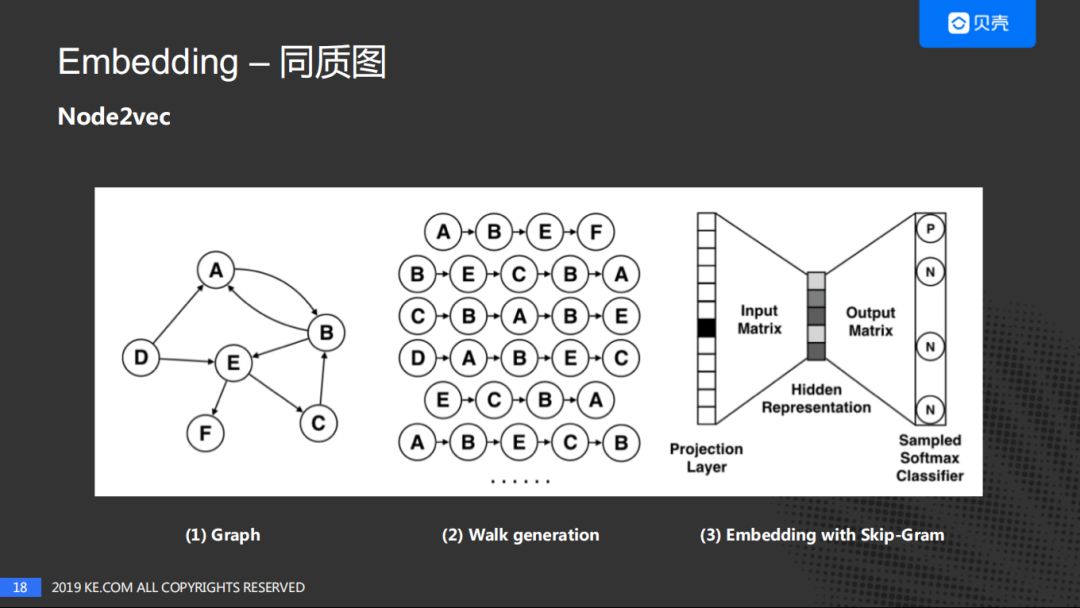
Graph Embedding近年来发展迅速,在各大公司陆续开始应用,并取得了不错的效果。结合贝壳自身的情况,对于同质图的网络采用的是Node2vec,并尝试使用Side Info来优化Node2vec;针对异质图网络尝试使用Metapath2vec。
针对同质图网络的Node2vec。对左边的房子图谱通过随机游走抽取序列,使用Word2vec进行量化。
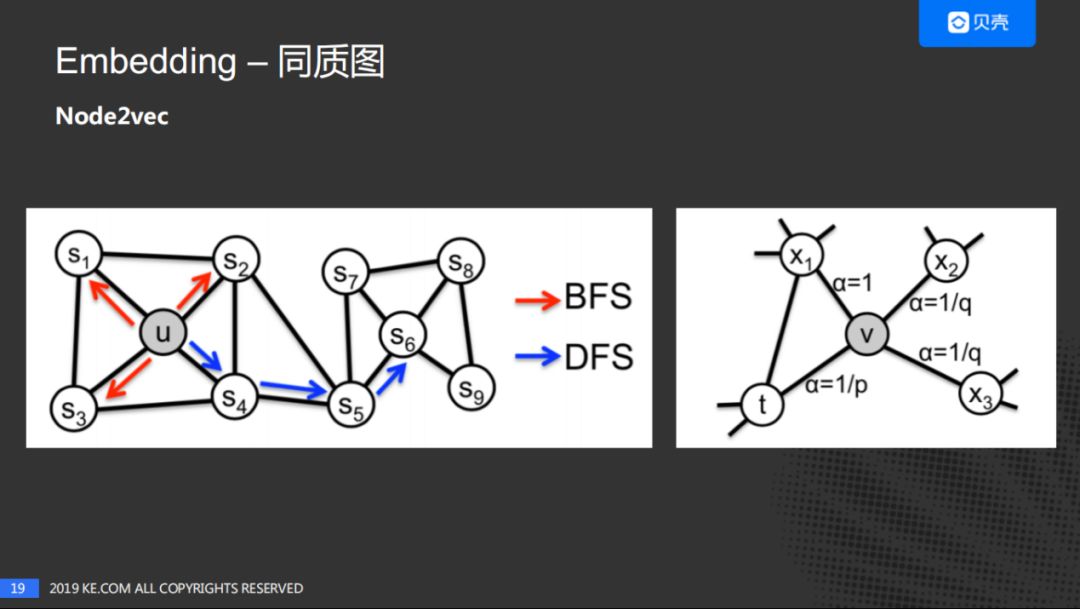
Node2vec的核心优点是:平衡了深度优先搜索和广度优先搜索,通过p和q控制了下一跳的跳转概率,进而选择是深度的遍历还是广度的遍历。
首先来回忆一下Word Embedding评估方法:通过词的语义判断词的相似性。例如:"would",通过Embedding相似性得到can,could,may,...是它的相似词,通过语义我们可以判断出来这些结果是相似的,这种Embedding的计算方法是有效的。
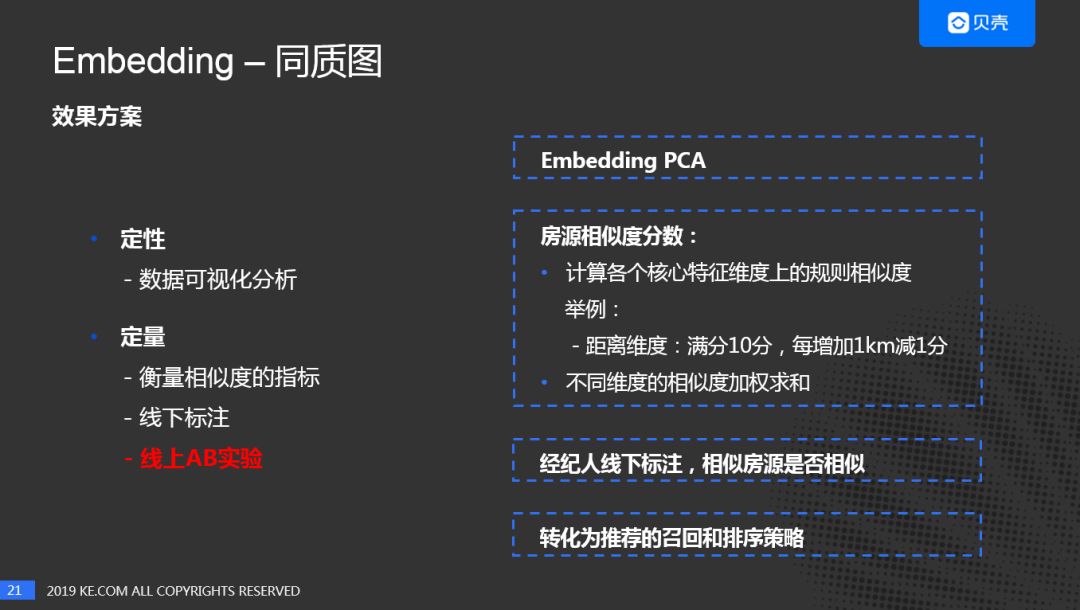
对于House,如何判断房子是否相似?我们通过房子的特征来判断房源是否相似,可以从定性和定量两个角度进行评估。
-
数据可视化分析,Embedding PCA的降维。
-
衡量相似度的指标:
定义了一个房源相似度的分数,通过规则打分的方式判断房子是否相似。
规则打分的计算逻辑:
首先在核心维度上如房价、面积、区域来判断每个维度上的相似度。
如距离维度,当两个房子的距离越近即可认为比较相似;
当价格越近, 两个房子是相似的;
最后,对不同维度进行加权求和,得到房子的相似度分数,分数越高即越相似,当然这也不是绝对的。
-
线下标注:
通过经纪人进行线下标注,标注房源是否相似。
-
![]()
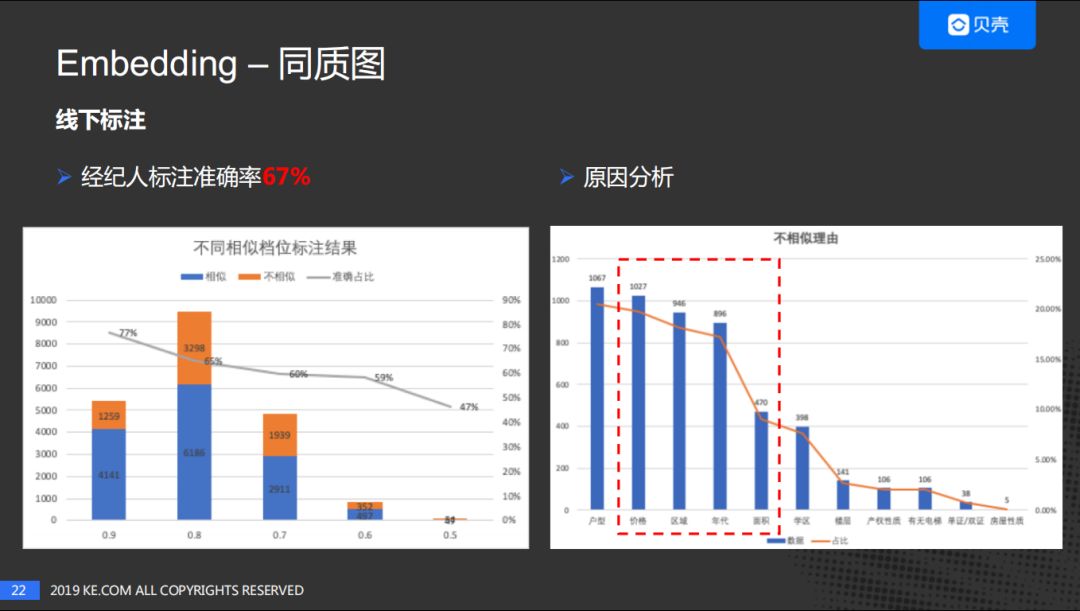
上图展示了V1版本经纪人对Node2vec线下标注的结果。我们考虑了不同种类的房子,包括高端房源、普通房源,也包括学区及远郊和市中心的房源,最终结果的准确率是67%。左图是对不同标注挡位的标注结果进行的分析,横坐标是不同相似度的挡位,柱状图蓝色表示相似的数量,橙色表示不相似的数量,折线图表示对应的准确率。我们可以看到余弦相似度越高,房源相似度越高。
同时,我们还分析了经纪人给出的房源不相似的原因,横坐标表示不相符的原因,柱状图表示不相似的数量,折线图表示百分占比。我们可以看出不相似的原因比较集中,第二版使用Side Info来做优化,把房源的特征加入到模型当中,但是其中的户型图并没有加进来,因为户型图的覆盖量没有这么高并且户型图是难以量化的。
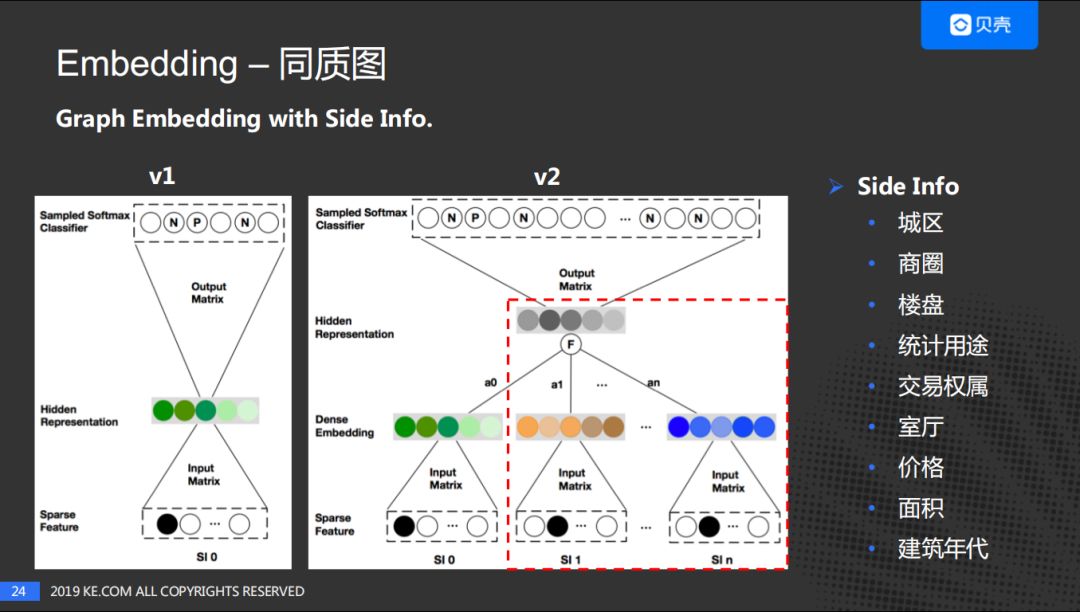
这是2018年阿里在KDD上的一篇文章,简单比较一下这两个方案:
V1是Node2Vec,V2是Graph Embedding with Side Info。两个图中的SI0是通过随机游走产生的房子序列,右边的SI1到SIn是房源的特征,进行Embedding之后再做一个平均。Side Info,基于经纪人帮助我们评估,我们采用了右边的九大维度。
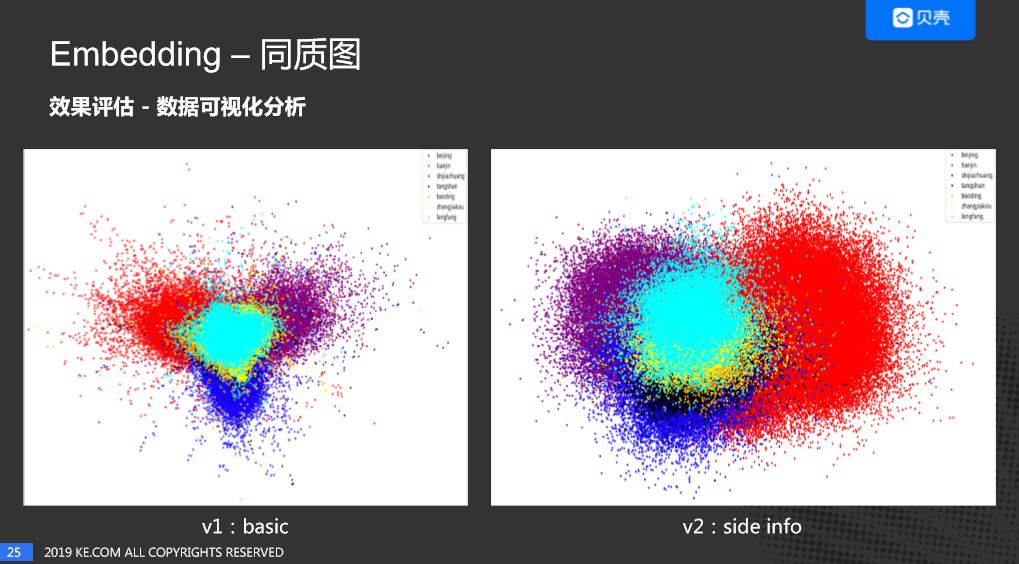
这是两个版本PCA降维之后的结果,每个颜色代表一个城市。可以看出来,Embedding在不同的城市里面是有一定的聚集度的。同时也可以看出加入了房子特征之后的V2版本,效果比V1版本好很多。
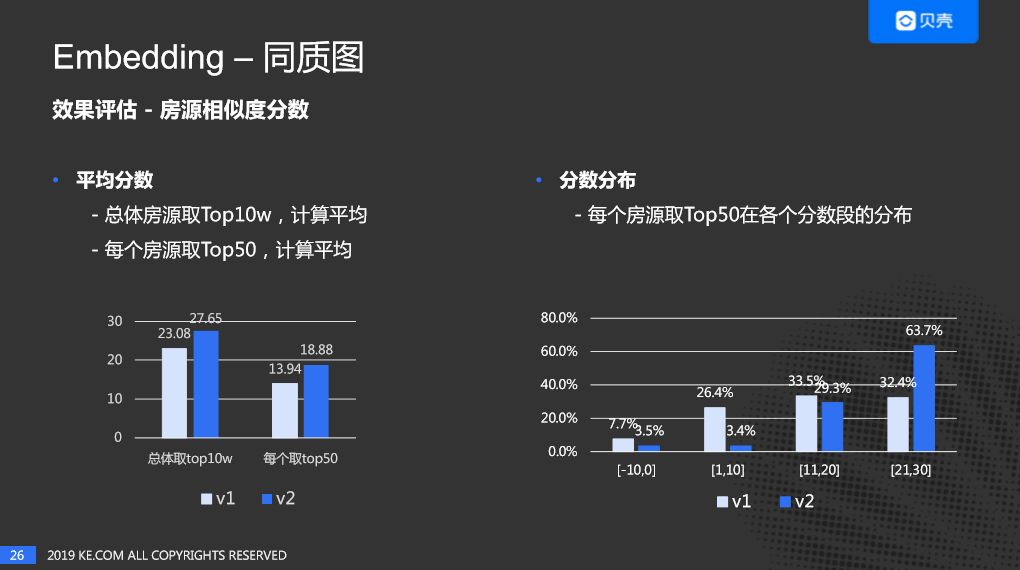
这是评估房源相似度分数的情况,左边是平均分数,从两个维度来考虑,第一个是把所有的房子两两之间计算它们的相似度,然后取Top 10W,第二个是对每套房源取Top 50。 通过左边的图表,我们可以看出V2的效果要明显好于V1。右边的图是分数的分布,对每个房源取Top 50,然后分析相似房源规则打分分数的分布,可以看出V2明显是分布在高分段之中。蓝色是V2 版本,浅色是V1版本。
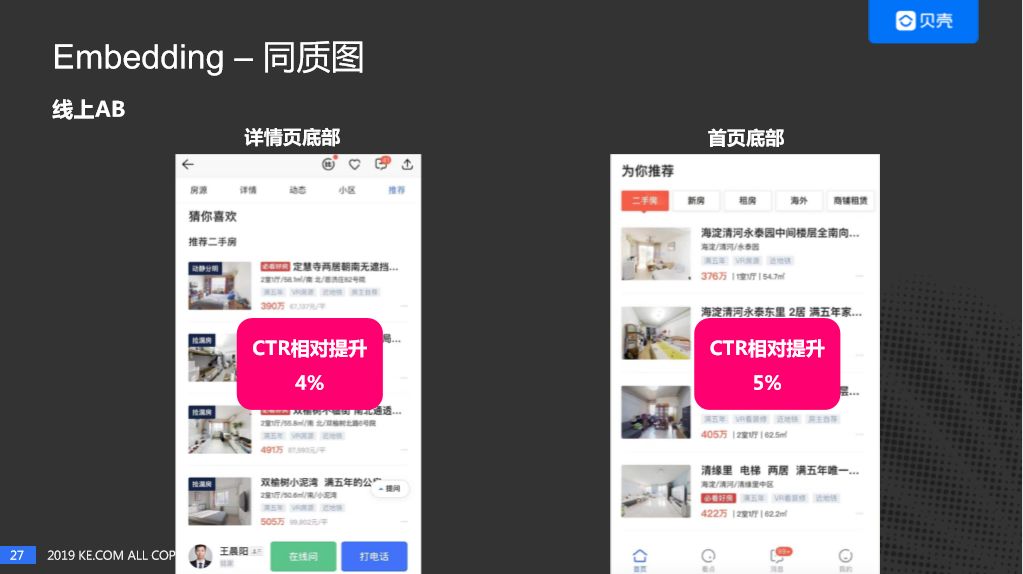
最后,我们进行了线上实验,在贝壳详情页的底部"猜你喜欢",还有首页的底部,"为你推荐"做了AB实验,在房源详情页面的底部CTR相对提升了4%,在首页底部,相对提升了5%。
有了房源Embedding之后,我们来计算下用户的Embedding,有两种方式:第一种是基于用户行为的序列进行加权平均,第二种方式是基于异构网络。
我们通过一个示例,来分析如何通过用户行为序列进行Embedding计算:
首先,用户先后浏览了三套房源,然后进行向量化,最后进行加权平均,作为用户的Embedding。在实际应用时,我们考虑了实时数据和时间衰减两个因素,最后应用在推荐,在贝壳APP首页的底部进行了AB实验,CTR 相对提升了3%。
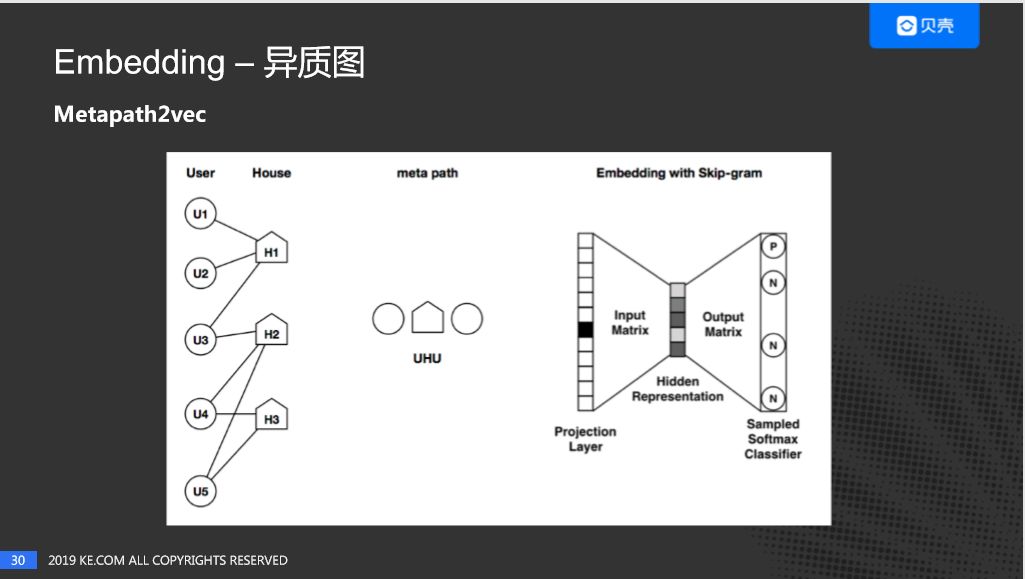
简单回顾一下Metapath2vec的原理,最左边是客房子图,中间是metapath(我们是客房客),基于metapath,对左边的客房子图进行随机游走,产生一个序列,最后通过word2vec对序列进行向量化。在构建房子图时,我们考虑了客户和房子之间的行为可以进行传播,假定用户的兴趣不变,我们取客户30天的行为,我们认为客户在这30天之内的兴趣是不变的。
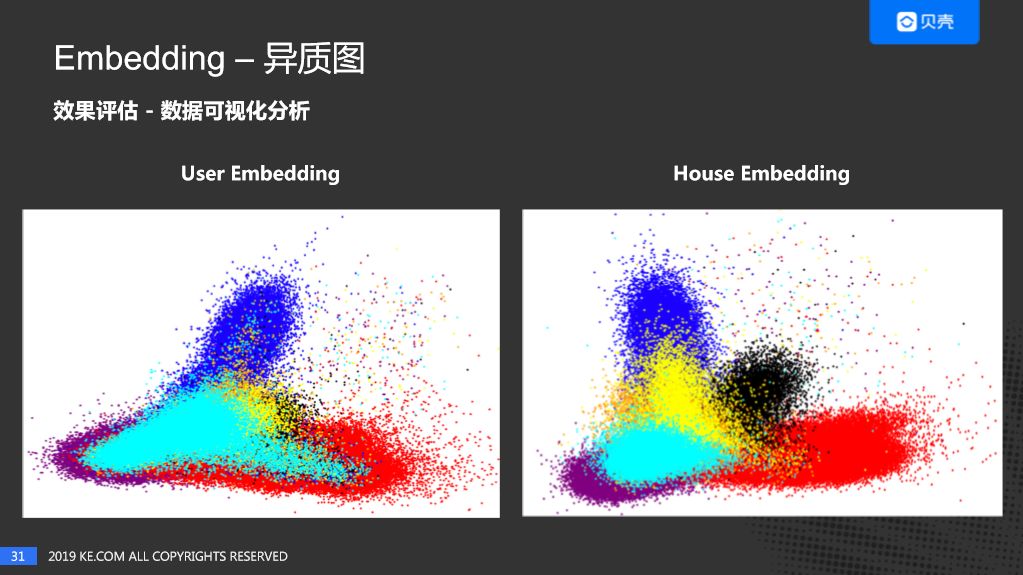
这是异质网络的 User Embedding 及 House Embedding PCA 降维后的结果。不同的颜色也代表不同的城市,我们可以看出来在不同城市也是有一定聚集度的。
有了Graph Embedding,我们如何进行关系的预测及推导呢?主要有两种方式:
-
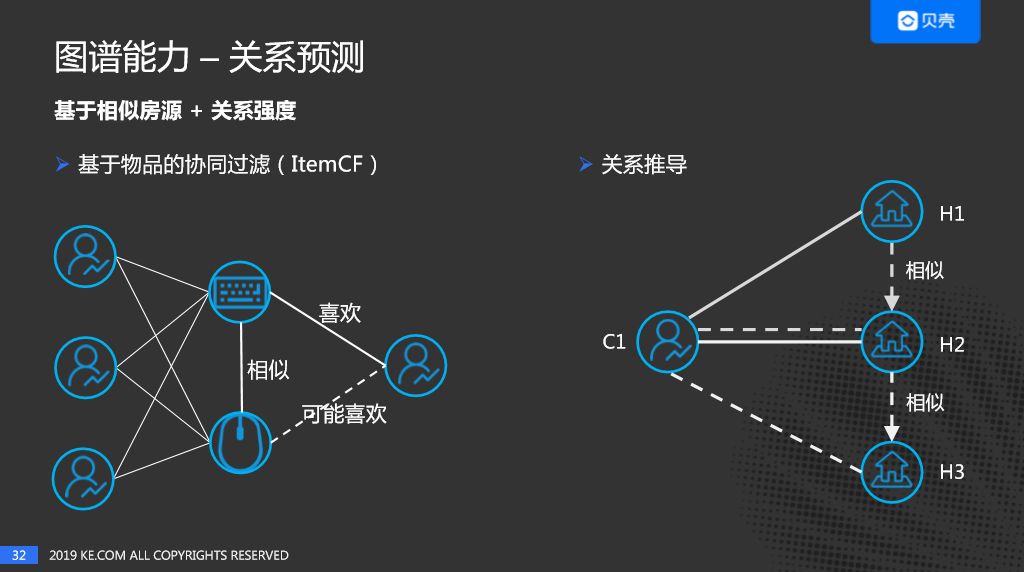
第一种,基于相似房源或者相似用户,再结合关系强度来进行关系预测;
-
第二种,基于异构网络,User embedding和House Embedding。
首先看下基于相似房源,首先回顾下基于物品的协同过滤原理:当多个用户同时喜欢两个物品时,我们认为这两个物品是相似的,当某个用户喜欢其中一个商品时,我们认为用户也可能喜欢另一个商品,这是协同过滤。我们来看下如何利用相似房源+关系强度进行关系推导:
用户C1分别对H1和H2产生过直接的行为关系,如果H2的相似房源是H3,可以推导出C1和H3之间可以建立一个关系,关系强度 = 强度(C1与H2)* 相似度(H2与H3)。同样,如果H1的相似房源是H2,C1和H2之间可以叠加一个关系强度。
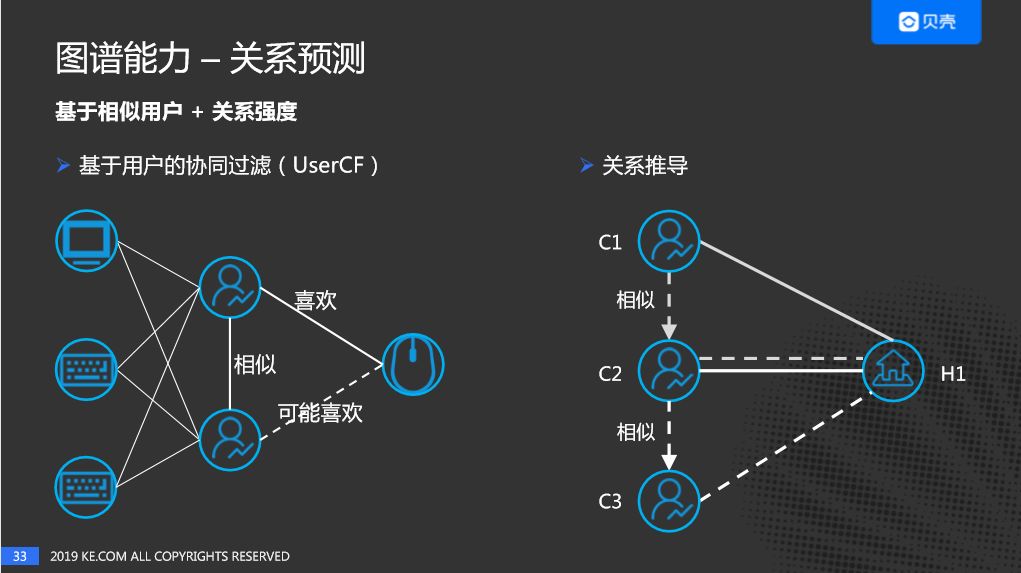
基于用户的协同过滤(UserCF)当两个用户同时喜欢多个商品时,我们认为这两个用户是相似的。如果某一个用户喜欢某一件商品,我们认为另一个用户可能也喜欢这个商品。
两个用户C1与C2分别和房源H1建立了直接的联系,C2的相似用户是C3,可以推导C3和H1之间可以建立一个关系。关系强度的计算方法同上。同样,C1的相似用户是C2,C1与H1之间可以叠加一个关系强度。
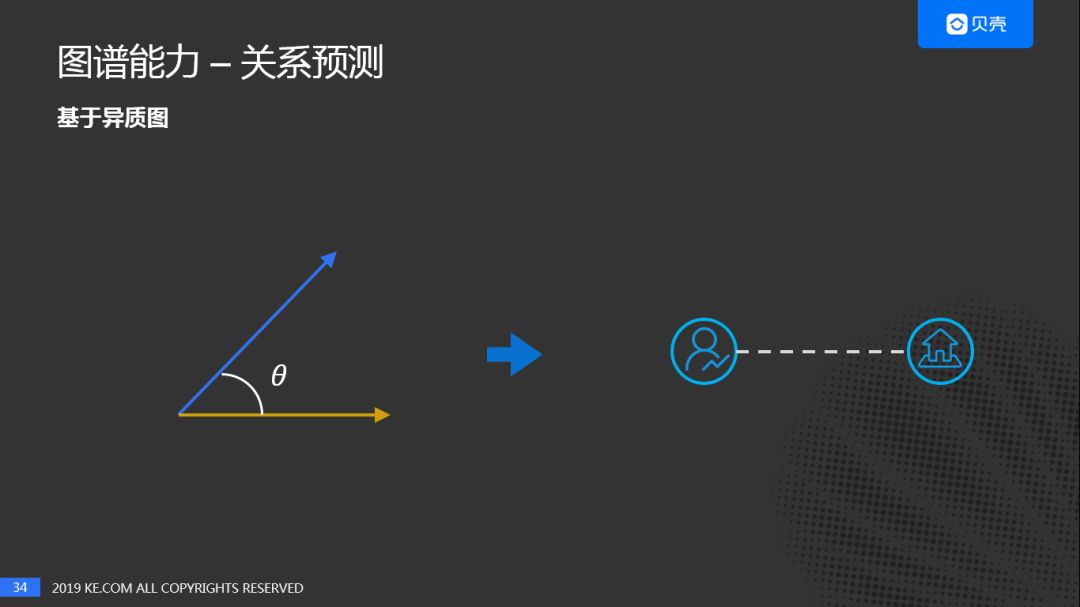
基于异质图的关系预测,直接计算用户和房源的余弦相似度,然后取Top N,Top N的房屋和用户就可以建立关系,关系的强度就是他们的余弦相似度。
-
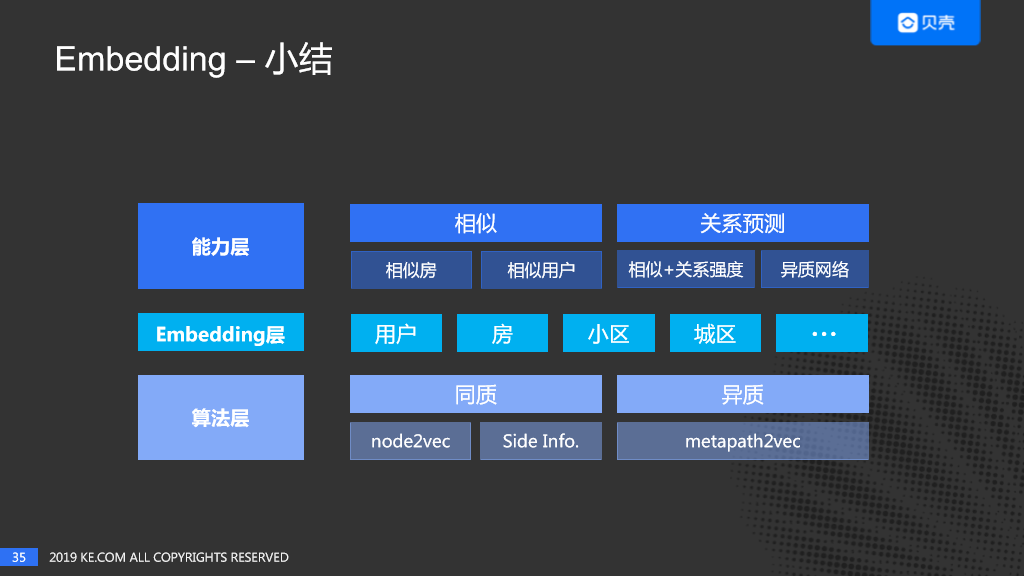
在算法层,对于同质图,尝试了node2vec及side info;对于异质网络,我们尝试了metapath2vec,另外,我们也在尝试一些其它的算法。
-
在Embedding层,我们有用户、房子、小区、城区等等的Embedding。
-
在能力层可以做相似,如相似房,相似用户;同时,可以做关系预测,一个是基于相似+关系强度,一个是基于异质网络。
以房客通项目为例:当某个用户经常浏览关注或者咨询某个房源时,房源的维护人A1和客户的维护人A2。A1会邀请A2带着客户来带看房源,这是一个三度查询的示例。产品上线之后,采纳率提升了20%。
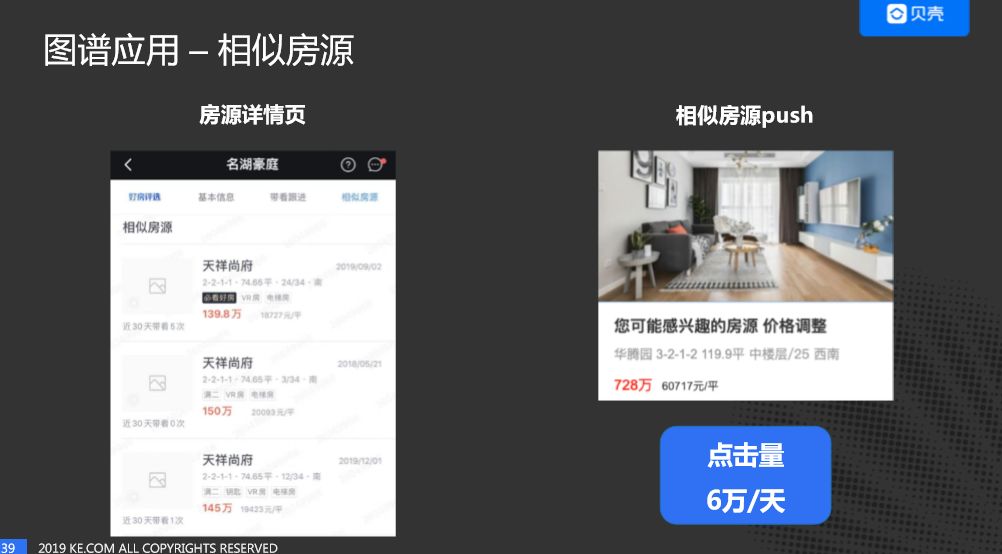
一个是房源详情页,在底部进行相似房源推荐;一个是相似房源push。其原理是当一个房子降价时,我们看经纪人关注的房源的相似房源是否是降价的这套房源,如果是,可以认为经纪人对这套降价的房源感兴趣,我们就会push一条消息给他。这个产品是近期上线的,每天的点击量是6W 左右,效果还不错,因为我们已经暴露了这套房子的核心信息,经纪人点进去,说明是比较感兴趣。
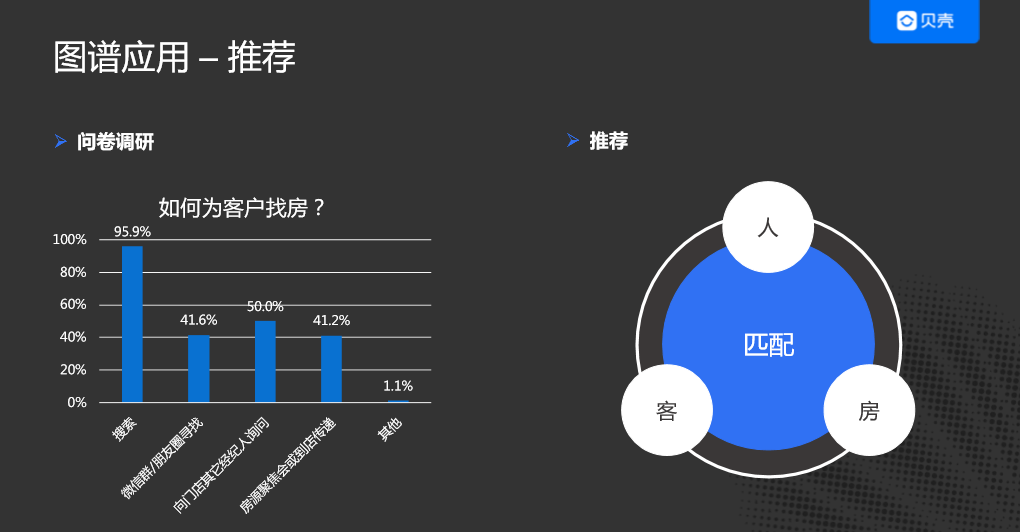
大家可能对C端的推荐比较熟悉,就不做介绍了。这里主要介绍B端的一些探索,如何助力经纪人。我们做了一个问卷调查,关于经纪人如何为客户寻找合适的房源,我们发现经纪人主要有4种方式:第一是搜索,第二是微信群或者朋友圈,第三是向门店的其他经纪人咨询,第四是房源交流会时大家相互交流。我们发现,经纪人在为客户找房的过程是比较原始的,没有好的策略及算法来支撑他们。
我们通过人、客户、房源匹配的算法对经纪人进行助力:
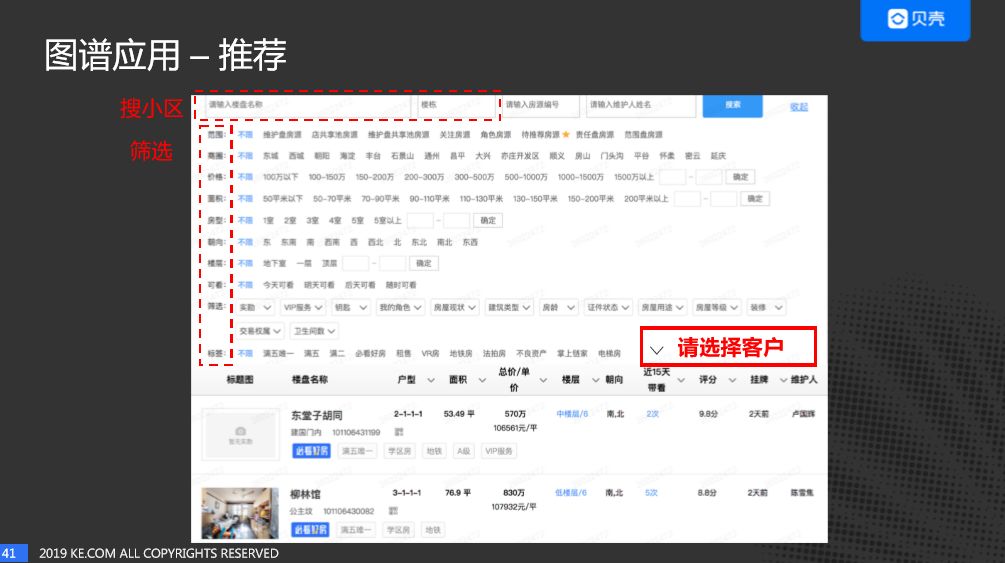
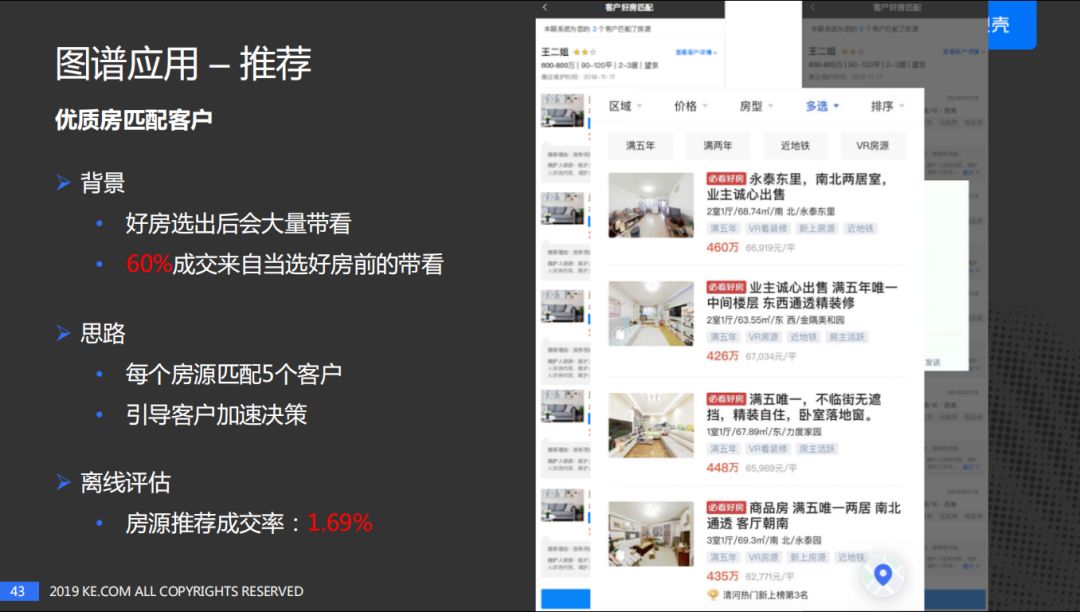
这就是帮助经纪人匹配房源的产品原型,搜小区然后根据房子的特征进行筛选。在此基础上考虑是否可以添加一个功能,可以选择客户然后推荐相关房源。
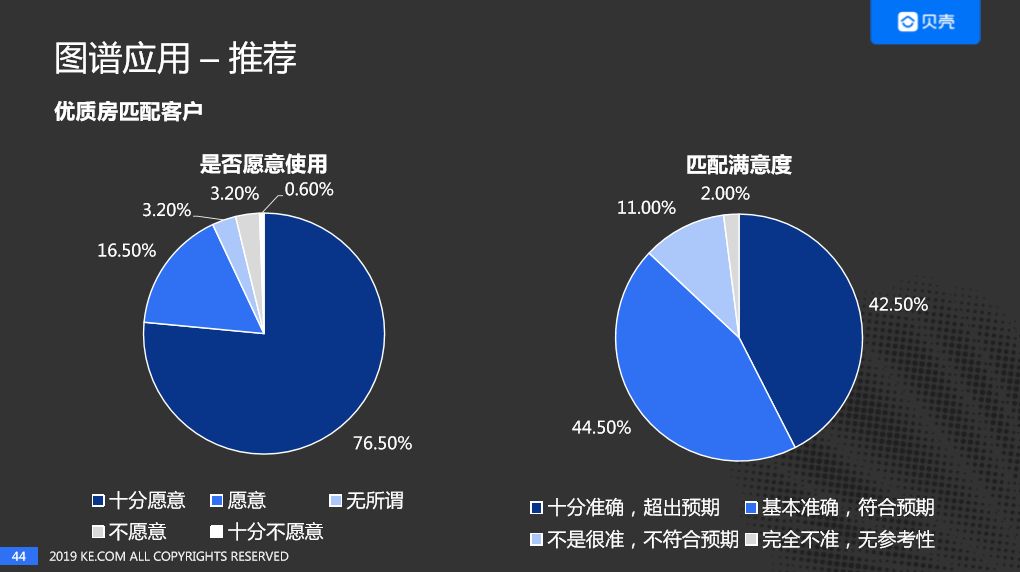
这个项目已经陆续在新房及二手房上线,从上图可以看出推荐提升了好几倍的效果。
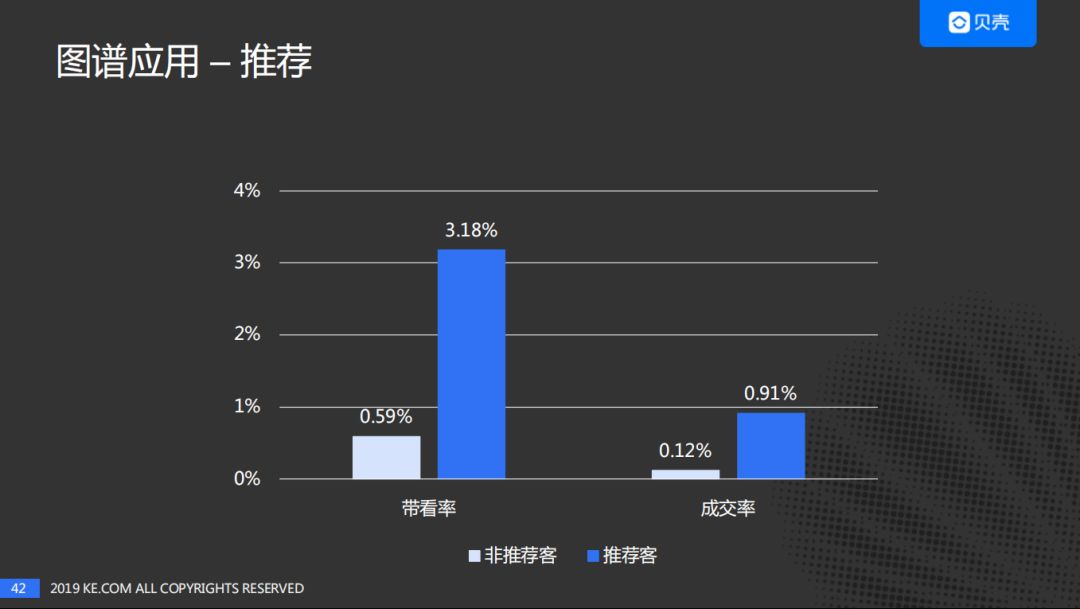
右边的图是"必看好房"项目,如果大家在贝壳APP上有过浏览房源的经历,会看到有的房子上面打着必看好房的标签。每周都会选出一些好房来作为必看好房,好房选择出来之后,会进行大量的带看争取把房子快速出售。根据分析,60%的成交来自于当选为好房之前的带看,这样会导致好房被选出来之后很多的带看是多余的。
因此,我们设计产品的思路是给每个房源匹配5个客户,引导客户加速决策。
房源推荐的成交率是1.69%,就是如果房子被系统推荐的5个客户购买则作为正例,否则是负例,效果还是比较不错的。
挖掘图谱的思路:
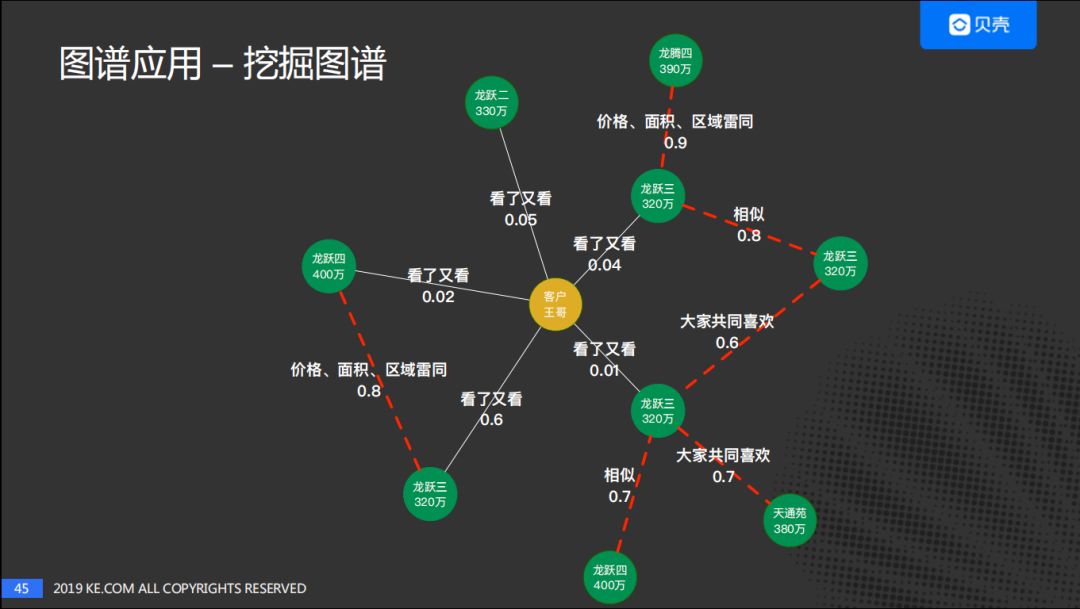
我们有了基础图谱,有了子图谱,也可以根据子图谱进行能力的建设,用在一些推荐的场景下。那么,我们能否用一种方式把所有的能力结合起来?比如,中间是客户,我们以客户为中心,基于基础图谱得到与他直接相关的房源信息,然后对相关房源信息经过图谱能力(房子图/协同过滤)进行挖掘找到相似的房源。也可以通过房子的特征找相似房源,即图中红色线段所示,就是二度关系。这样我们设想通过可视化的方法直接展示房源信息,然后把推荐变成可视化推荐的方法。我们正在通过这样的思路,设计产品。
欢迎加入
DataFunTalk知识图谱技术交流群
,跟同行零距离交流。如想进群,请加
逃课儿
同学的微信(微信号:
DataFunTalker
),回复:
KG
,逃课儿会自动拉你进群。
——END——
文章推荐:
关系图谱在贝壳找房风控体系的应用与实践