【智能金融】机器学习在反欺诈中应用
机器学习在反欺诈中应用
当前机器学习在金融行业已经运用非常广泛,尤其在金融业的信贷领域。在实践中,欺诈与信贷业务强相关,所以,反欺诈变成机器学习在信贷领域的一大应用。反欺诈一般会用到机器学习、深度学习以及图谱关系,其中,机器学习与深度学习多是针对个人欺诈风险,而图谱关系则多用于团伙欺诈风险的识别。因此,本次分享将介绍欺诈风险的特点以及机器学习、深度学习和图谱在实践中的应用。
一、关于反欺诈
(一)欺诈风险简介
在信贷领域有两类风险,一类是信用风险,一类是欺诈风险。信用风险主要是对借款人还款能力和还款意愿进行评估,而反欺诈则是对借款人的目的是否正当进行判断。
一般借款人出现信用风险,金融机构可通过风险定价和自有备付金进行防范,风险可控性较大。而当借款人在借款时便以骗贷或骗钱为目的,且金融机构未能及时识别欺诈,则会出现未能通过借款赚取利息,反而被骗走本金的情况,尤其无法识别团伙欺诈时,会在短时间内遭受非常严重的后果,金融机构面对此类风险的可控性便会非常小,所以欺诈风险是金融机构零容忍的。
(二)反欺诈生命周期简介
信贷反欺诈要从防御开始做起,所以应从用户申请到放款整个生命周期的各个阶段特点进行分析,针对各个阶段采取具有针对性的反欺诈措施。其生命周期可参见下图:
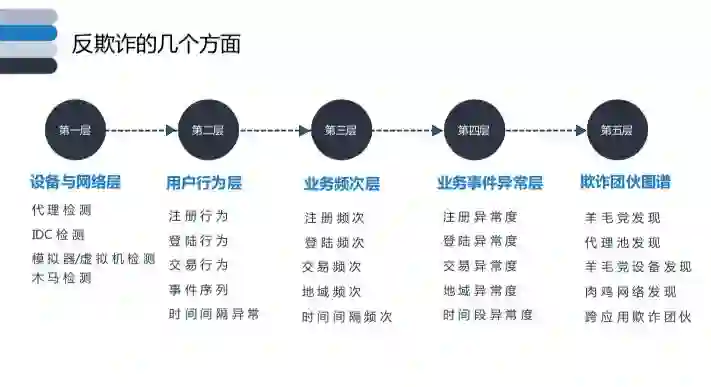
如上图,设备与网络防御是反欺诈的第一步,可通过设备和网络层面的检测,防止用户利用设备对金融机构进行欺诈;在第一层进行防御了部分欺诈用户后,再从用户行为层、业务频次层及业务事件异常层识别用户是否有欺诈行为;再经过前四层之后还会通过复杂网络对团伙欺诈进行识别。
二、机器学习应用
(一)反欺诈规则的缺点
反欺诈一般通过两种方式,一种是设定规则,另一种是通过算法。
规则在反欺诈实践中应用也较多,但是缺点也明显,主要表现为:
1. 策略性较强,命中直接拒绝,而且黑名单本身的误伤性也较强;
2. 无法给出用户的欺诈风险有多大;
3. 未考虑用户从信用风险向欺诈风险的转移,尤其是在行业不景气时。
以上缺点机器学习可以进行有效的避免,如可计算用户的欺诈概率有多大,从而采取一定的措施争取客户,而不是直接拒绝,同时也可以通过模型计算用户从信用风险转移为欺诈风险的概率,从而金融机构可及时进行风险控制与准备。
(二)机器学习有监督模型
评分卡一般运用在信用风险评估,如:A卡(申请评分卡)和B卡(行为评分卡)等,反欺诈也会运用有监督学习,如评分卡(F卡),具体如下:
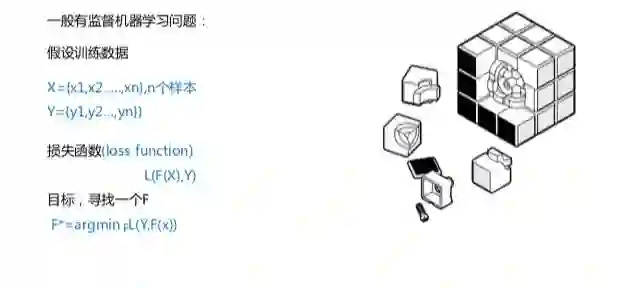
做模型的过程中,特征很重要,特征决定模型的效果。反欺诈模型需要从欺诈的角度来做特征,要注意与信用特征区分开,以免与A卡和B卡的耦合度过高。模型算出的多是概率,一般会将用模型算出的概率映射到分数,具体如下图:

(三)部分常规机器学习在反欺诈中应用
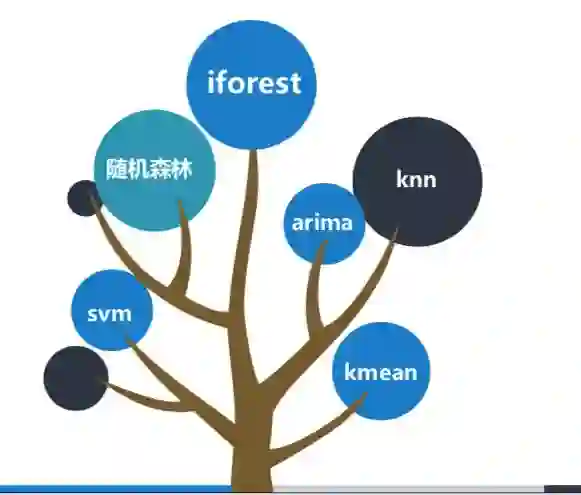
在反欺诈中用到的机器学习主要有下图几种。其中,iforest通常用来做数据离群点的异常检测,在应用方面,金融公司可根据自身的规则和算法,将检测出的离群点在评分卡入模的数据方面,进行加权或算法调整。svm通常也用来做异常检测;arima则用来作时间序列预测分析;根据现在信贷数据坏样本较少的特点,knn和kmean可以用来做聚类;随机森林则是在做异常检测时进行分类,以上机器学习可通过博客进行更多了解,此处不进行深入讲解。
三、深度学习应用
此部分对人工神经网络(ANN)和时间序列进行简单介绍。
神经网络通常需要大量彼此连接的神经元,每个神经元通过特定的输出函数,计算处理来自其他响铃神经元的加权输入值。神经元质检的信息传递强度,通过加权值定义,算法会不断自我学习,调整加权值。神经网络算法的核心是:计算、连接、评估、纠错和疯狂培训。
时间序列部分介绍RNN(循环神经网络)和LSTM(长短记忆循环神经网络)两种算法。LSTM是RNN的优化版,在特征较多时,RNN计算量会呈指数式增长,其计算复杂度也会增加,如下图:
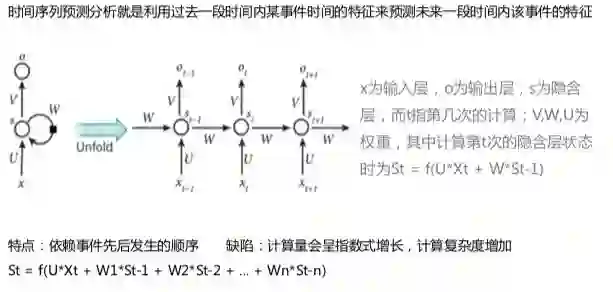
LSTM则是在RNN的结构以外加入遗忘阀门(forget gate)、输入阀门(input gate)和输出阀门(forget gate),其通过这些阀门节点实现记忆功能,改善了RNN在计算过程中会出现的问题,如下图:
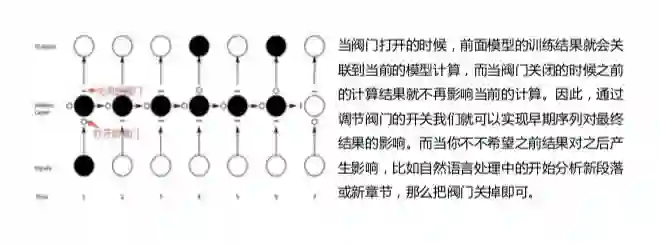
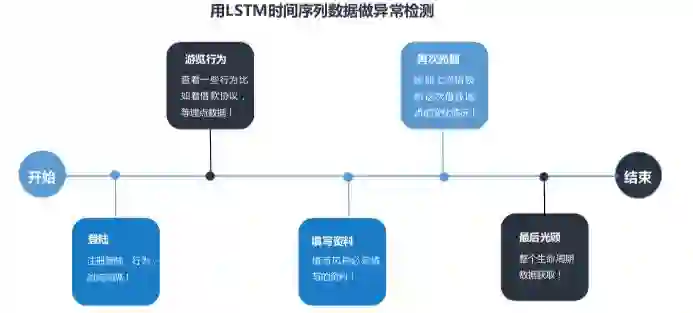
时间序列在信贷中有两个比较重要应用场景,一是B卡(行为评分卡),一是异常检测。我们着重介绍LSTM在这两个场景中的应用。在行为评分卡的应用中,当用户在金融机构进行多次借款时,可以将其以往的借款行为通过统计方法或其他相关方法生成embedding进行LSTM计算。异常检测的应用可参考下图:
另外在使用LSTM时需注意4点:
1. 应限制每一个时间序列embedding的长度;
2. 对缺失数据做补0操作;
3. 针对离散变量的embedding尽量不要做onehot处理;
4. 样本量少时,应通过仿真模型进行异常检测评估,仿真模型能够有效解决信用风险转欺诈风险的导致模型失效的问题。
四、图谱相关应用
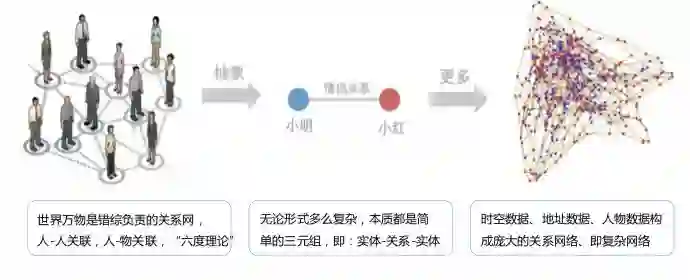
图谱主要用来防止团伙欺诈,也可以根据用户的周边关系判断用户的好坏概率。此次介绍三种图谱关系在反欺诈中的应用。
其中,常规统计一般不会直接用规则,而是将规则做成特征,再带入模型进行统计。比如一度联系人中有多少黑中介,一度联系人中的逾期人数有多少,此类特征的KS较高且有效。常规统计一般会用到社群分割和强连通算法。而种子传播层面则需要用到trustrank,关系embedding则可以通过衍生变量将关系向量化,将向量化的关系带入模型进行进一步的分析和统计。
(一)常规统计
因为资源限制或提高投资回报率的原因,黑产一般会最大程度的利用已有资源,比如,重复的使用现有设备和信息进行多次贷款申请,这样就会出现同一手机号码、登录IP或硬件设备出现在多个申请信息中,形成关联网络。常规统计的运用,是通过将数据进行关联,形成关系网络图,然后使用社会关系网络分析工具,分析关系网络图中是否有大量共用设备等拓扑结构。
(二)复杂网络embedding算法
有时候机器无法识别信息,需要将信息向量化(embedding),将信息向量化后才可以做后续的算法操作。embedding的方法有很多,此次仅介绍node2vec一种。node2vec的原理是前端为随机游走(random walk),后端为word2vec。random walk则采样,将概率最大的关系采样出来并生成类似文本的序列数据,这类序列数据相当于词的共现性,对词的共线性可以做word2vec,这里的word2vec与NLP的word2vec无差异。Embedding后会生成50维到128维的向量,之后进行聚类和分类的操作,具体如下:

(三)trustrank算法
Trustrank是pagerank的升级版,当前我司用的trustrank并不是传统的trustrank,而是改变其中的某些算法。trustrank是传播关系的一种算法,根据人与人的关系进行判断和识别。比如,小红和小明是情侣关系,当小红违约时,小明的违约概率会增大,根据类似传播关系用来做定额和模型的衍生变量。Trustrank的使用需要建立起图谱关系,数据量小时,spark的sparkgragh对trustrank的图谱关系支撑较好。
Trustrank涉及种子用户(含白种子和黑种子)的定义,当前的大多使用中只有一种传播方法,也就是白种子只传播白用户,黑用户只传播黑用户。但是其实可以进行变量的衍生和算法的改进,比如一个用户既跟黑中介有联系,又跟高净值用户有联系。
以下图为例,trustrank为种子用户(下图的1和2)定义一个初始值,每次传播后会改变矩阵的值,最后收敛得到trustrank的分。
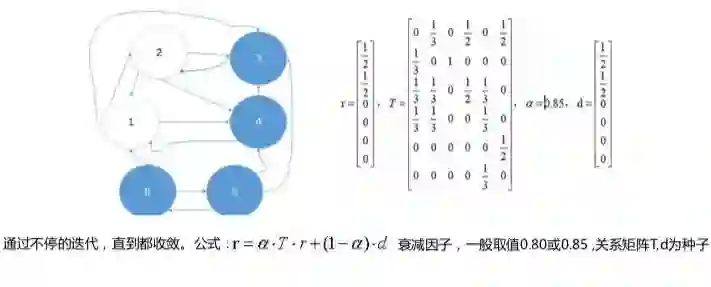
以上图谱关系可以进行改进和升级,如在传播的过程中可以加入通讯录关系,号码通,老乡、目前所在地、兴趣、职业等,形成以用户画像传播的好坏用户,在不同的用户画像传播中做不同的权重传播。
作者介绍:

陈德建 新浪金融 高级模型算法研究员
美国德克萨斯州大学硕士,本科毕业于北京理工大学,原百度高级算法工程师,3年NLP深度学习算法工作经验,后参与微博借钱模型团队组建,搭建反欺诈和复杂网络团队,整体负责反欺诈和复杂网络等工作,擅长文本及关系图谱挖掘。
——END——
内容来源:DataFun AI Talk
出品社区:DataFun


工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。





