教你用Flink实现超大规模用户行为分析(附代码、视频教程)

来源:AI前线
作者:吴昊
本文长度为3000字,建议阅读5分钟
本文整理自瀚思科技吴昊在柏林“Flink Forward”上的演讲《如何利用 Flink 实现超大规模用户行为分析》。瀚思科技是中国第一家大数据安全公司。
以下是本次演讲的完整视频,WiFi党可任性点开播放,当然我们也为流量党们整理了文字版本,任君选择~
今天的演讲主要分为四大部分:
网络安全中的用户行为分析(简称 UBA);
实时超大规模用户行为分析的技术挑战 ;
Drools 规则引擎在 CEP 中的应用 ;
Flink 原生 CEP 组件。
网络安全中的用户行为分析
用户行为分析到底是什么?简而言之,其通过分析用户数据(例如交易数据,用户登录数据),找出异常行为以检测外部及内部人士的攻击活动。举例来说,外部攻击通常是由外部黑客通过破解 VPN 密码并夺取员工帐户的方式实现。而内部攻击则往往表现为心存不满的或者即将离职的员工对敏感信息的窃取。
我们需要分析的源文件通常表现为多种数据类型,例如服务器数据、网络数据、数据库数据、应用程序数据、安全数据等。传统的用户行为分析系统通常以离线批处理模式根据既定规则对这些数据进行分析。而如今的最新趋势则倾向于添加某种形式的机器学习方案,从而利用在线 / 流式处理,对实时数据进行分析以区分威胁行为与正常行为。
实时超大规模用户行为分析的技术挑战
实际应用中,由于部分技术挑战的存在,目前机器学习模型在这一领域中尚未能带来可观的助益。此类挑战具体包括:
输入信息规模过大(往往包含来自十余个领域的上万名独立用户);
实际需求往往需要以实时方式检测攻击活动(例如在反欺诈场景中,需要实时监控用户的交易数据);
检测逻辑需要将黑名单、业务逻辑规则以及机器学习算法加以结合 ;
检测逻辑需要以近实时方式进行定制化调整。
那么,我们该如何解决上述挑战?又为何选择 Flink?
首先,我们需要一个吞吐量大且资源消耗低效率高的流处理引擎。这一点 Flink 作为新一代的流处理引擎完全符合我们的需求。
其次,面对不同的用户数据格式,我们必须支持多种数据源。这一点上 Flink 内置的对多种数据源的支持(CSV,Kafka,Hbase,Text,Socket 数据等)也为用户数据的接入提供了便利。
第三,Flink 内置的 RocksDB 数据存储格式使其数据处速度快且资源消耗少。
第四,Flink 强大的窗口机制(包括翻转窗口,滑动窗口,两者的组合,全窗口以及用户自定义窗口)可以满足复杂的业务逻辑,使得用户可以编写复杂的业务规则。同时 Flink 对算子(operator)的高可控性,使得用户可以灵活添加删除或更改算子。
下面来看我们这套解决方案的具体架构:
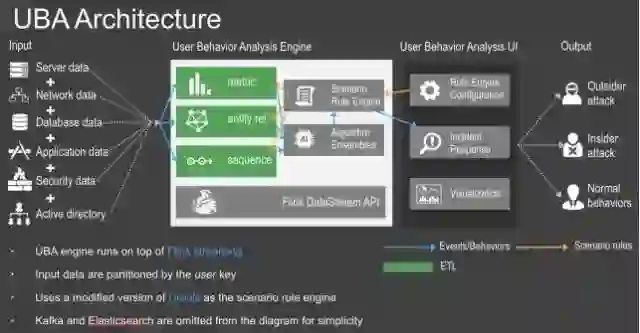
如大家所见,我们在左侧列出了作为输入信息的多种不同的数据类型。中部位置为核心引擎,而 Flink 则处于底部。上方为三种 ETL 类型:统计指标、实体关系与序列。我们可以将这些 ETL 类型转换为由 Drools 引擎运行并配合部分机器学习算法的 Scenario 规则。同时在生产环境当中需要为用户提供良好的 Web 界面。因此,我们设计出这样一套界面以帮助用户进行规则配置、响应安全事件并对数据进行可视化展示。
Drools 规则引擎在 CEP 中的应用
规则引擎方面我们有两个选择:Flink 原生 CEP 和 Drools。那么两者各有什么优势和劣势呢?
Flink CEP 是一套极具通用性、易于使用的实时流式事件处理方案。作为 Flink 的原生组件,省去了第三方库与 Flink 配合使用时可能会导致的各种问题。但其功能现阶段看来还比较基础,不能表达复杂的业务场景,同时它不能够做到动态更新。而 Drools 作为一个完备的规则引擎,在功能全面性上更胜一筹,同时其动态更新的设计方针,能够保证我们在无需对系统进行重新编译及重启的前提下将其部署在运行中的系统当中。
好的,接下来我们将深入探讨如何利用 Drools 来实现用户行为分析系统。
Drools 究竟是什么?
Drools 是一套业务规则管理系统(简称 BRMS),且可基于规则引擎实现向前与向后推理。这是一套基于 JVM 的系统,其语义与 Java 非常相似。

Drools 的最大优势在于,它语法规则简单,类似 Java,因此编写门槛不高、能够无缝化与 Java 集成,且用户可以对 Drools 规则进行动态配置。但这套方案也存在着自己的不足,例如其内置聚合功能速度缓慢,不适合我们自身或者客户使用场景下的大量聚合操作任务。另外,其内置事件序列处理机制也需要消耗大量内存资源。
作为常用的业务场景,我们需要将三种 ETL 类型翻译成对应的 Drools 规则。具体来讲,事件 / 数据中的每一行都需要由三种 ETL 类型进行处理:统计指标、实体关系与序列,并借此将内容转换为实际行为:
统计指标:特定翻转窗口内的聚合值,例如一小时内的登录次数。
实体关系:两个实体之间的关联,例如用户使用哪台设备。
序列:事件经过过滤并按时间戳排序后,被转换为有序状态。
以上三种 ETL 皆在场景规则当中进行定义,以 drools 规则文件的形式被部属到系统中。如何做到这一点呢,Flink 的 CoFlatMapFunction 提供了完美的解决方案,我们可以利用该功能同时处理两种数据流:事件流与规则流。
听起来不错,很多朋友可能认为 Flink 与 Drools 的配合可能完美无瑕。但事实并非如此——大家在实际使用中可能遇到以下问题:
需要在特定时段之内维持原有窗口状态(作为 Drools 规则引擎的中间结果)。
Flink 内置的窗口机制会在窗口结束时发送输出结果并清除窗口状态。
Flink 内置的 RocksDB 后端会在窗口清除时删除所有记录。
来自 Flink 的结果会被不断的注入 Drools 规则引擎进行规则匹配,事件一多就会快速耗尽内存资源。
当然,我们可以对 Flink 进行修改以克服上述问题。举例来说,我们可以为 RocksDB 添加“TTL“属性,保证其不再直接删除各条目。另外,我们还可以为内存内能够容纳的条目数量设定阈值,同时及时清除未使用的条目,从而优化 Drools 的内存管理。
Flink 原生 CEP 组件
以上是使用 Drools 的方案,那么我们是否只能选择 Drools?还有没有其它更好的解决方案?
就目前来看,我们也可以使用 Flink 1.4 中提供的 Flink CEP 新特性。Flink 近期推出了一系列新功能,我们可以利用其解决“无法热部署“的难题:
触发保存点、取消作业,更新规则,恢复作业。
保存点内惟一标识运算符状态。
[FLINK-6927] 在 CEP Flink 1.4 中支持模式组。
[FLINK-7129] 动态变更模式开放发布。
利用上述新特性,我们可以设计出一套新的 Flink CEP 系统,其工作流程如下:

用户利用我们定义的语言编写场景规则,此后我们将这些规则翻译为 Java 代码。接下来,我们对代码进行编译并打包为 jar 文件。最后,我们触发保存点并撤销当前正在运行的作业,部署新规则 jar 而后恢复该作业。
为了将这一思路付诸行动,我们进行了具体实验并发现了一些有趣的现象。如果我们为每种规则创建一条独立的规则流,那么规则数量一旦过多(上千)即会导致初始化缓慢以及内存不足的问题。
那么如何将多条规则纳入同一流?
CEP API 仅允许单规则 = 单流
Flink CEP 1.4 提供 GroupPattern 将多种规则合而为一
目前尚无法对多模式进行优化
因此总结来讲,这套解决方案拥有以下优势与弊端:
优势:
易于实现,代码量仅为 Drools 版本的五分之一。
可扩展性与并发性更出色,不存在单一大负载的算子。
易于获取各模式中的运行时指标 。
弊端:
保存点与恢复部署流程会造成数秒延迟。
好了,说了这么多 我们来看一个实例演示,这样大家可以更直观的理解我刚演讲的内容:
首先我们登录系统,大家可以看到这里我已经预置了一条规则。此规则中包含两个判断条件:转账数额大于 19000 和小于 300 的。我们现在发布这条规则到 Flink 来看看它是否生效。大家可以看到,在警告界面已经有满足规则的事件被告出。
回到规则界面,我们先关闭这条规则并新增一条按时间窗口聚合的规则。在 10 秒的翻转窗口中设置 5s 的滑动窗口来计算转账数额的总和,一旦总和大于 100000,就被视为可疑事件被告警。同样我们发布这条规则到 Flink 再去告警界面看是否有满足条件的事件。
很显然新规则已经生效,相关告警已经显示在告警界面。同时第一条规则已失效,大家可以看到没有满足第一条规则的事件被告出。让我们再一次回到规则配置界面,让第一条规则再次生效并发布它。这样我们就有两条规则同时在运行。回到告警界面我们可以看到两条规则都已生效。