DeepMind 推出贝叶斯 RNN,语言建模和图说生成超越传统 RNN
新智元编译
来源:arXiv
作者:Meire Fortunato、Charles Blundell、Oriol Vinyals
译者:文强
【新智元导读】DeepMind 研究人员今天在 arXiv 上传他们的新作《贝叶斯 RNN》。据介绍,论文有四大贡献,其中一种技术不仅适用于 RNN,任何贝叶斯网络都有效。作者还写道,“我们在两项经过广泛研究的基准上提高了测试结果,性能大幅超越了现有的正则化技术,比如 dropout”。作者 Oriol Vinyals 更是现身 Reddit 及时答疑并更新论文,让讨论更加火热。赶紧来看看这项工作吧。

摘要
在这项工作里,我们探讨了一种用于 RNN 的简单变分贝叶斯方案(straightforward variational Bayes scheme)。首先,我们表明了一个通过时间截断反向传播的简单变化,能够得出良好的质量不确定性估计和优越的正则化结果,在训练时只需花费很小的额外计算成本。其次,我们展示了一种新的后验近似,能够如何进一步改善贝叶斯 RNN 的性能。我们将局部梯度信息合并到近似后验,以便在当前批次统计数据周围对其进行锐化。这种技术并不仅限于循环神经网络(RNN),还可以更广泛地应用于训练贝叶斯神经网络。我们还经验性地演示了贝叶斯 RNN 在语言建模基准和生成图说任务上优于传统 RNN,以及通过使用不同的训练方案,这些方法如何改进我们的模型。 我们还引入了一个新的基准来研究语言模型的不确定性,便于未来研究的对比。
循环神经网络(RNN)在一系列广泛的序列预测任务上取得了业内最高水平的性能(Wu et al., 2016; Amodei et al., 2015; Jozefowicz et al., 2016; Zaremba et al., 2014; Lu et al., 2016)。在这项工作中,我们将通过将贝叶斯方法用于训练,考察如何在 RNN 中增加不确定性和正则化。
贝叶斯方法为 RNN 提供了另一种表达不确定性的方法(通过参数)。同时,使用一个先验(prior)将各种参数整合,使许多模型在训练期间平均化,使网络实现正则化的效果。近来,有的方法试图将 dropout(Srivastava et al,2014)和权重衰减证明为一种变分推理的方案(Gal&Ghahramani,2016),或者应用随机梯度 Langevin dynamics(Welling&Teh,2011,SGLD)在时间上直接截断反向传播(Gan et al,2016)。
有趣的是,最近的工作还没有进一步研究像 Graves(2011)所做的那样,直接应用变分贝叶斯推理方案(Beal,2003)。(注释:原文没有提到 Graves 2011 年的工作,这里是有人在 Reddit 上指出后,Oriol Vinyals 立即做的修改。)
我们在(Blundell et al,2015)Bayes by Backprop 工作的基础上,提出了一个简单直接的方法,经过实验表明能够解决很大规模的问题。
我们的方法是对通过时间截断反向传播的一个简单改变,得到了对 RNN 权重后验分布的估计。
将贝叶斯方法应用于成功的深度学习模型有两大好处:对不确定性和正则化的明确表征。我们的公式明确地导出了一个有信息理论支撑的成本函数(cost function)。
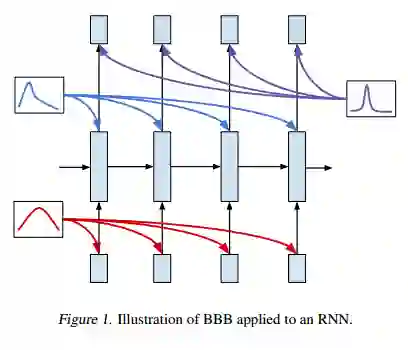
变分推理后验的形式决定了不确定性估计的质量,从而影响着模型的整体表现。我们将展示如何在批次的局部调整(“锐化”)后验,提高 RNN 的性能。这种锐化使用基于批次的梯度来调整一个批次数据的变分后验。这一过程可以被视为层次化分布(hierarchical distribution),其中局部批次梯度被用于调整全局的后验,在每个批次都形成一个局部近似。
将变分推理应用于神经网络时,这为高斯后验(Gaussian posterior)的典型假设提供了更灵活的形式,减小了方差(variance)。这种技术可以在其他变分贝叶斯模型中更广泛地应用。
我们展示了如何将 Backprop By Bayes(BBB)有效应用于 RNN。
我们开发了一种减少 BBB 方差的新技术,可以被广泛地用于其他最大似然框架当中。
我们在两项经过广泛研究的基准上提高了测试结果,性能大幅超越了现有的正则化技术,比如 dropout。
我们为研究语言模型的不确定性提出了新的基准。
作者在论文中给出了他们新方法在图说生成在 MSCOCO 上与此前方法的对比。可以看出,BBB 相较以前的结果有显著提升。




论文的其余部分组织如下。第 2 节和第 3 节分别回顾了通过反向传播做贝叶斯(Bayes by Backprop,BBB)和通过时间做反向传播(Backprop through time)。第 4 节推导出了用于 RNN 的 Bayes by Backprop,而第 5 节描述了后验的锐化。第 6 节简要回顾了相关工作。第 7 节做了实验评估,最后在第 8 节进行讨论并得出结论。
论文地址:https://arxiv.org/abs/1704.02798
Oriol Vinyals 在的 Reddit 讨论页面:https://www.reddit.com/r/MachineLearning/comments/64o579/r_bayesian_recurrent_neural_networks_fortunato_et/

3月27日,新智元开源·生态AI技术峰会暨新智元2017创业大赛颁奖盛典隆重召开,包括“BAT”在内的中国主流 AI 公司、600多名行业精英齐聚,共同为2017中国人工智能的发展画上了浓墨重彩的一笔。
点击阅读原文,查阅文字版大会实录
访问以下链接,回顾大会盛况:
阿里云栖社区:http://yq.aliyun.com/webinar/play/199
爱奇艺:http://www.iqiyi.com/l_19rrfgal1z.html
腾讯科技:http://v.qq.com/live/p/topic/26417/preview.html



