替换Transformer!谷歌提出 Performer 模型,全面提升注意力机制!
考虑到 Transformer 对于机器学习最近一段时间的影响,这样一个研究就显得异常引人注目了。

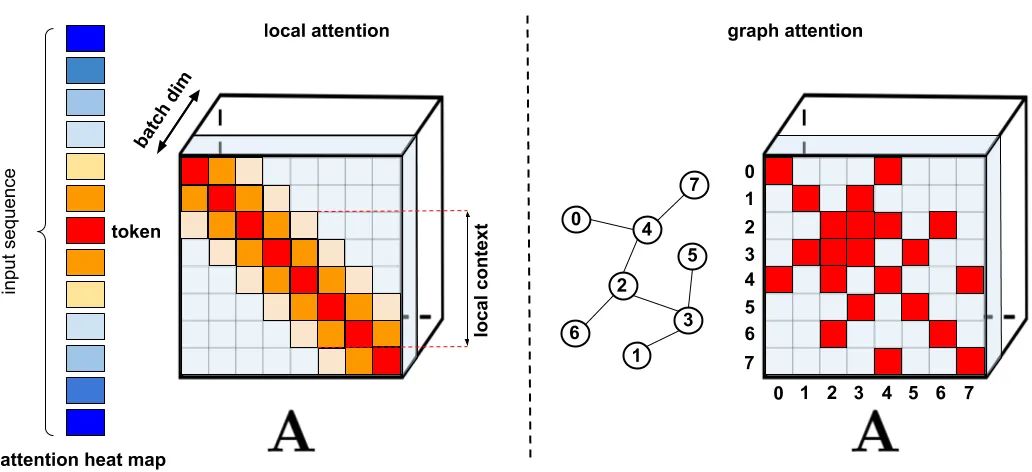

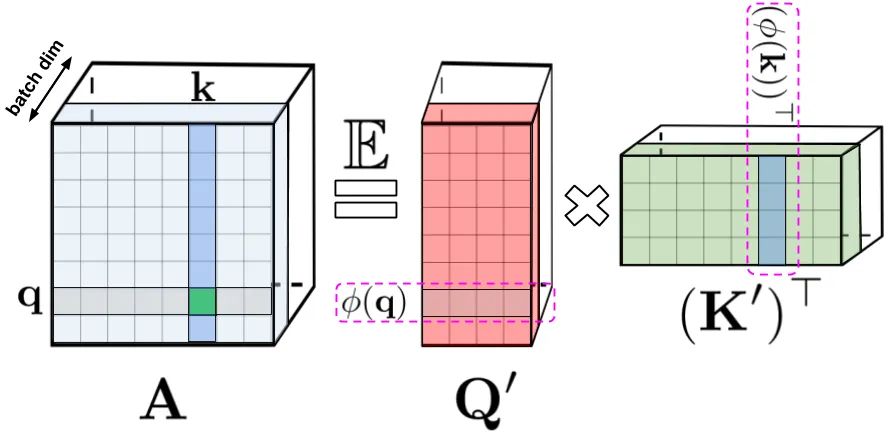
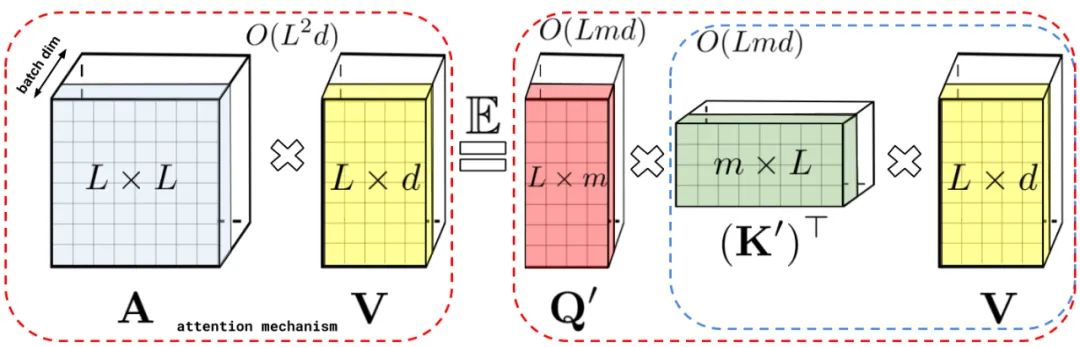
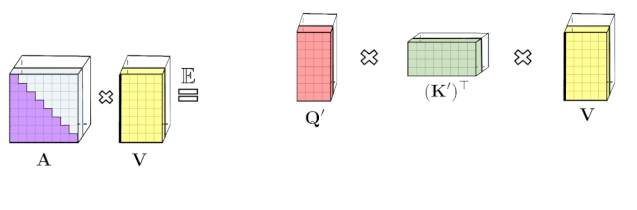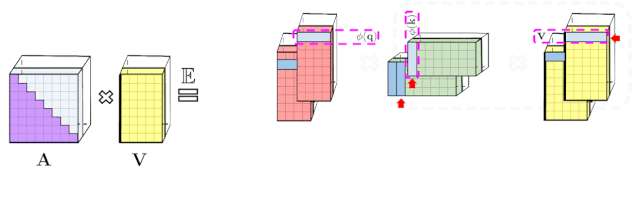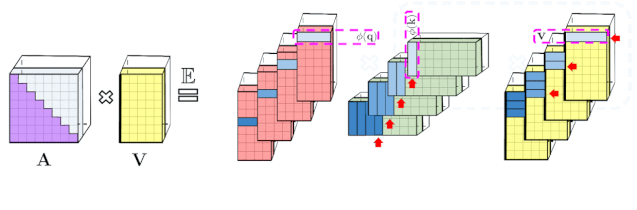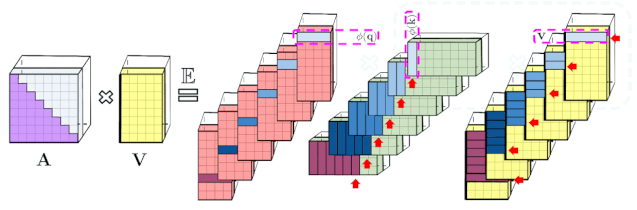
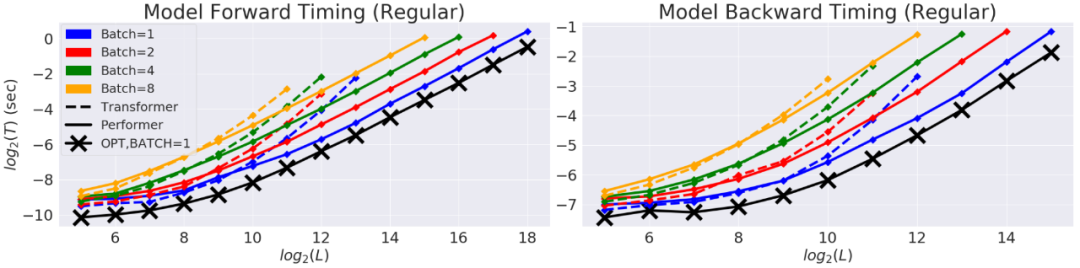
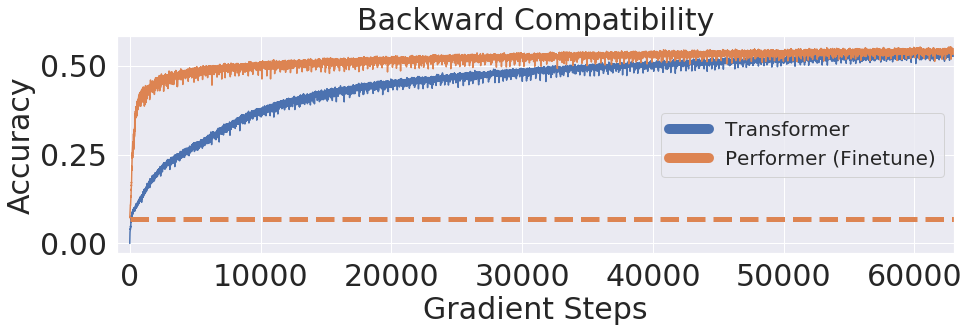
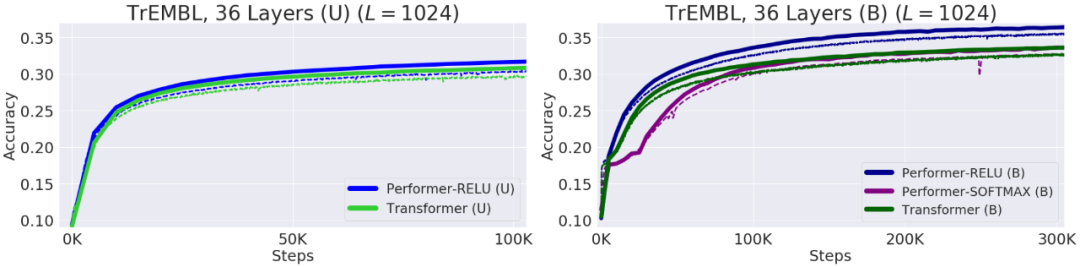
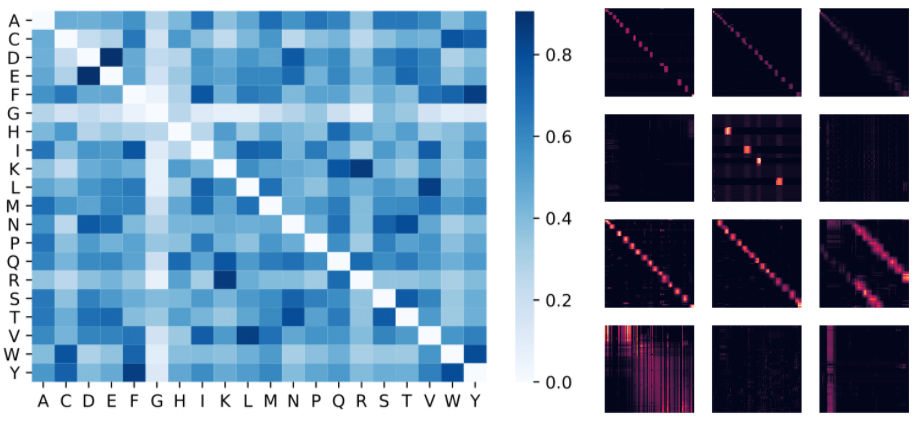
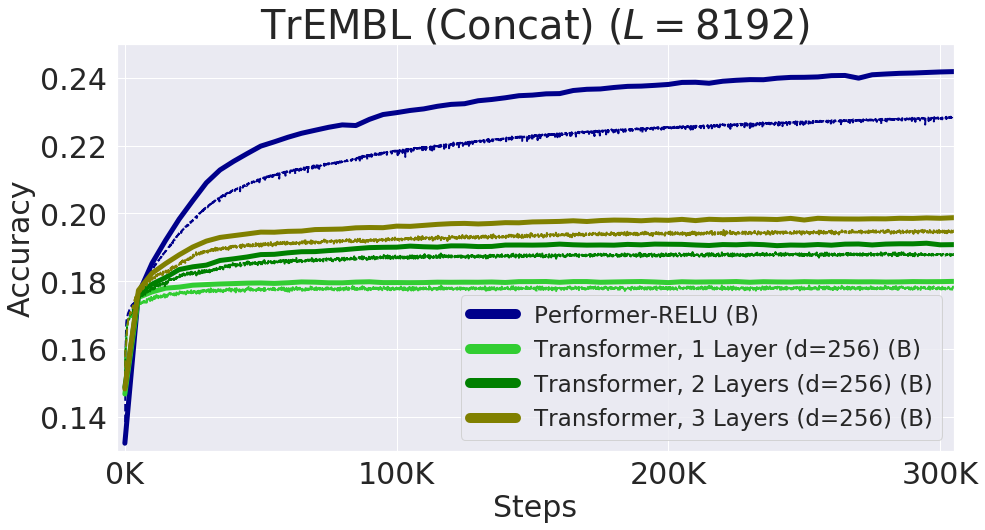
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“Performer” 可以获取《替换Transformer!谷歌提出 Performer 模型,全面提升注意力机制!》专知下载链接索引



登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文