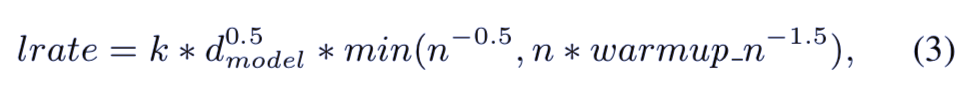语音识别技术在各种工业应用中获得了极大的普及。但是,建立一个好的语音识别系统通常需要大量的转录数据,而这些数据收集起来成本高昂。为了解决这个问题,来自滴滴出行人工智能实验室的研究者提出了一种新颖的无监督预训练方法,他们称之为 masked 预测编码(masked predictive coding,MPC)。这种方法可以应用于基于 Transformer 模型的无监督预训练。
![]()
当前的工业端到端自动语音识别(automatic speech recognition,ASR)系统高度依赖于大量高质量的转录音频数据。但是,转录后的数据需要大量的努力才能在工业应用中获得,同时在线系统中还保留着大量未转录的数据,这些数据收集起来成本较低。因此,当标记数据有限时,如何有效地使用未转录数据来提升语音识别系统的性能就很值得研究了。
最近,无监督预训练已在一些领域显示出较好的结果。在这些无监督预训练方法中,比较突出的一项研究是基于 Transformer 的编码器表征(BERT),它使用了 masked 语言模型(Masked Language Model,MLM)的预训练目标,并在 11 个自然语言处理(NLP)基准上取得了新的 SOTA 结果。
基于 Transformer 的模型具有很多优点,包括更快的训练速度、更好地利用相关语境信息以及在诸多语音识别基准上优于 RNN 的性能。在本文中,研究者从 BERT 那里获得了灵感,提出了一种简单有效的预训练方法,即 masked 预测编码(MPC)。
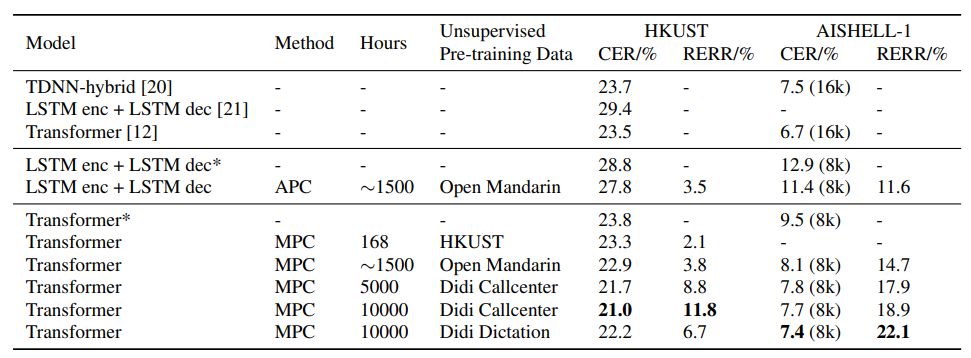
论文结果显示,通过简单的无监督预训练,中文语音识别任务能得到10%以上的性能提升。在数据集 HKUST 上,当仅使用 HKUST 数据库数据做预训练时,字错误率能达到23.3%(目前文献中最好的端到端模型的性能是字错误率为 23.5%);当使用更大无监督数据库做预训练时,字错误率能进一步降低到 21.0%。
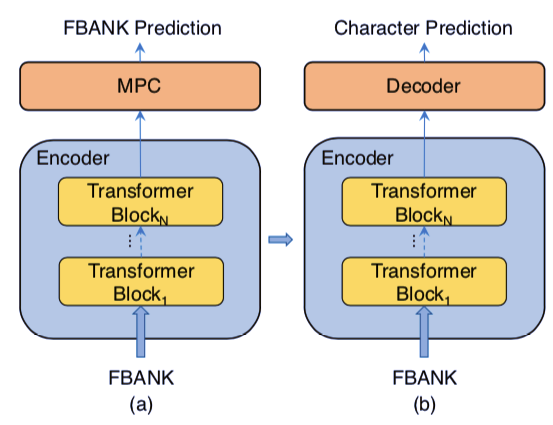
研究者提出的训练方法分为两步,包括无监督预训练和有监督微调过程。为了避免对模型架构进行大幅度的修改,研究者将预测编码的方法直接应用于 FBANK(即 Filter Bank,即一种音频数据的特征表示)输入和编码器的输出上。在所有实验中,编码器输出和 FBANK 输入的映射有着一样的维度。在无监督训练后,研究者将预测编码的层去掉,将 Transformer 解码器添加到模型之后,用于下游 ASR 任务的微调。在语音识别模型中不会引入任何额外的参数,所有的参数都是端到端在微调阶段训练的。
![]()
图 1:研究者提出的训练流程。(a)预训练:编码器预测被 mask 的位置,从而预测 FBANK。(b)微调:Transformer 解码器在编码器之后加入,然后模型微调用于预测字符。
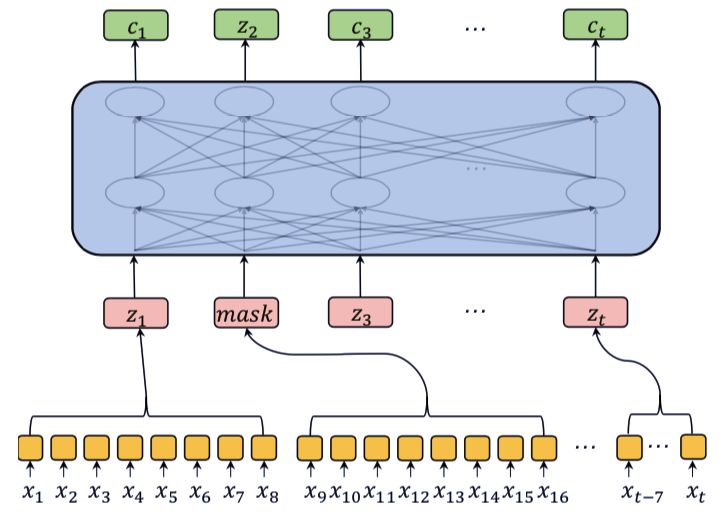
MPC 使用的是类似于 Masked-LM(MLM)的架构。和 BERT 相似,研究者对每段语音的 15% 的帧也进行了 mask 操作。被选中的帧,在 80% 的情况下被替换为零向量,10% 的情况下替换为随机帧,剩下的则保持不变。动态掩码操作也在研究中被使用,即在每次一个序列被输入进模型的时候对其进行掩码。
![]()
在预训练时,降采样在输入特征被输入到编码器进行预训练之前使用。而降采样在微调过程中是在模型内部进行的。
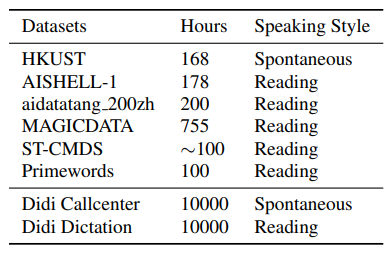
研究者使用的语料有:HKUST 普通话电话语音语料(HKUST/MTS)、AISHELL-1、aidatatang 200zh、MAGICDATA 普通话中文阅读语音语料、免费 ST 中文普通话语料(ST-CMDS)和 Primewords 中文语料。其中,HKUST 和 AISHELL-1 数据集不参与预训练过程。
为了理解预训练数据的大小和说话方式对下游任务的影响,研究者也使用了滴滴命令和滴滴呼叫中心的语音数据。滴滴命令包含从内部移动命令应用中收集的大约一万小时的语音。滴滴呼叫中心的语音数据也有一万小时,来自用户和客服中心的通话记录。这些数据都进行了脱敏处理,可用于研究。
![]()
表 2:所有使用的数据集细节。ST-CMDS 包括了 100 小时的语音数据。
模型的微调是在 HKUST 和 AISHELL-1 数据集上进行的。对于 HKUST 而言,研究者分别使用了 0.9、1.0 和 1.1 的速度扰动,用于训练数据和每个说话者的 FBANK 特征正则化过程。对于 AISHELL 数据集而言,0.9、1.0 和 1.1 的速度扰动也用在了训练数据上。所有的语音数据都使用了 8kHz 的降采样率,尽管 AISHELL-1 经常使用的是 16kHz。
实验时,研究者设计了和 BERT 论文一样的超参数:(e = 12、d = 6、d_model = 256、d_ff = 2048 以及 d_head = 4)。降采样是在每三个 Transformer 编码器之间使用,最终形成了 8 个折叠的降采样。在预训练时,模型都使用 4 个 GPU 进行训练,总的批大小是 256,共训练了 500k 次。研究者使用了 Adam 优化器,学习率则是可变的,预热公式如下:
![]()
在微调阶段,总的批大小则是 128,学习率和训练时一致,除非 5 个批之后验证集损失依然不下降,则将其除以 10。预定义的采样率是 0.1,以便减少曝光偏见(exposure bias)。研究者还使用了 L2 正则。
![]()
表 1:之前的工作和无监督预训练方法下,HKUST 和 AISHELL-1 测试数据集上的字错误率。
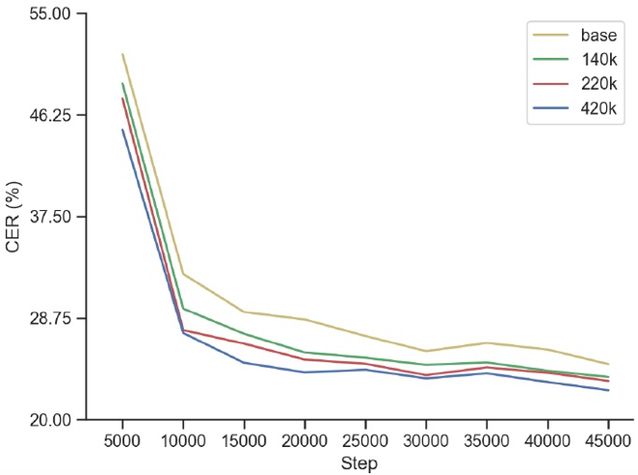
图 3:不同步数的无监督预训练模型下微调模型的收敛曲线
![]()
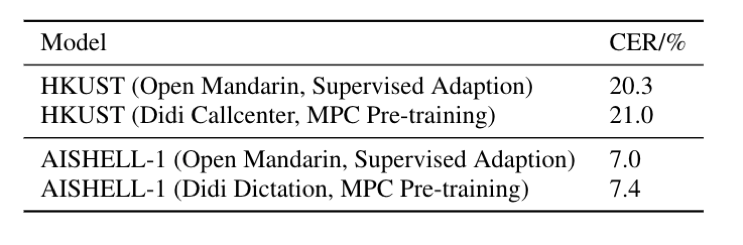
表 3:HKUST和AISHELL-1数据集上对比无监督预训练和有监督自适应方法的字错误率。
研究者最后对比了无监督预训练和有监督自适应两种方法。
实验结果表明,有监督自适应方法结果还是略好于无监督预训练方法。
然而,无监督预训练方式不需要任何的标注,这种方式可以有效的降低构建高质量语音识别系统的成本。
接下来,滴滴团队表示,他们将会尝试将这一模型应用于工业领域,减少搭建高质量语音识别系统时需要的标注数据量。此外,他们会继续扩大无监督数据量(如十万小时、百万小时),探索这样做是否可以进一步提升语音识别的精确度。最后,团队表示,他们会探索无监督数据的特定领域及风格对模型鲁棒性的影响。
华为云近期推出精编实战公开课,涵盖机器学习、大数据、运维实战等多项系列课程,由华为云资深工程师倾情讲授,完成理论学习+实践内容还有精美礼品相赠。点击
阅读原文,选择课程,免费报名。
![]()