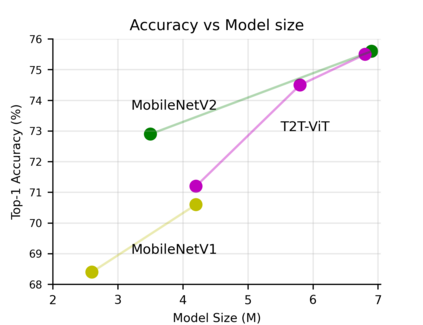
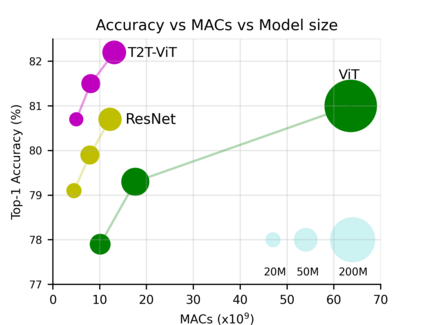
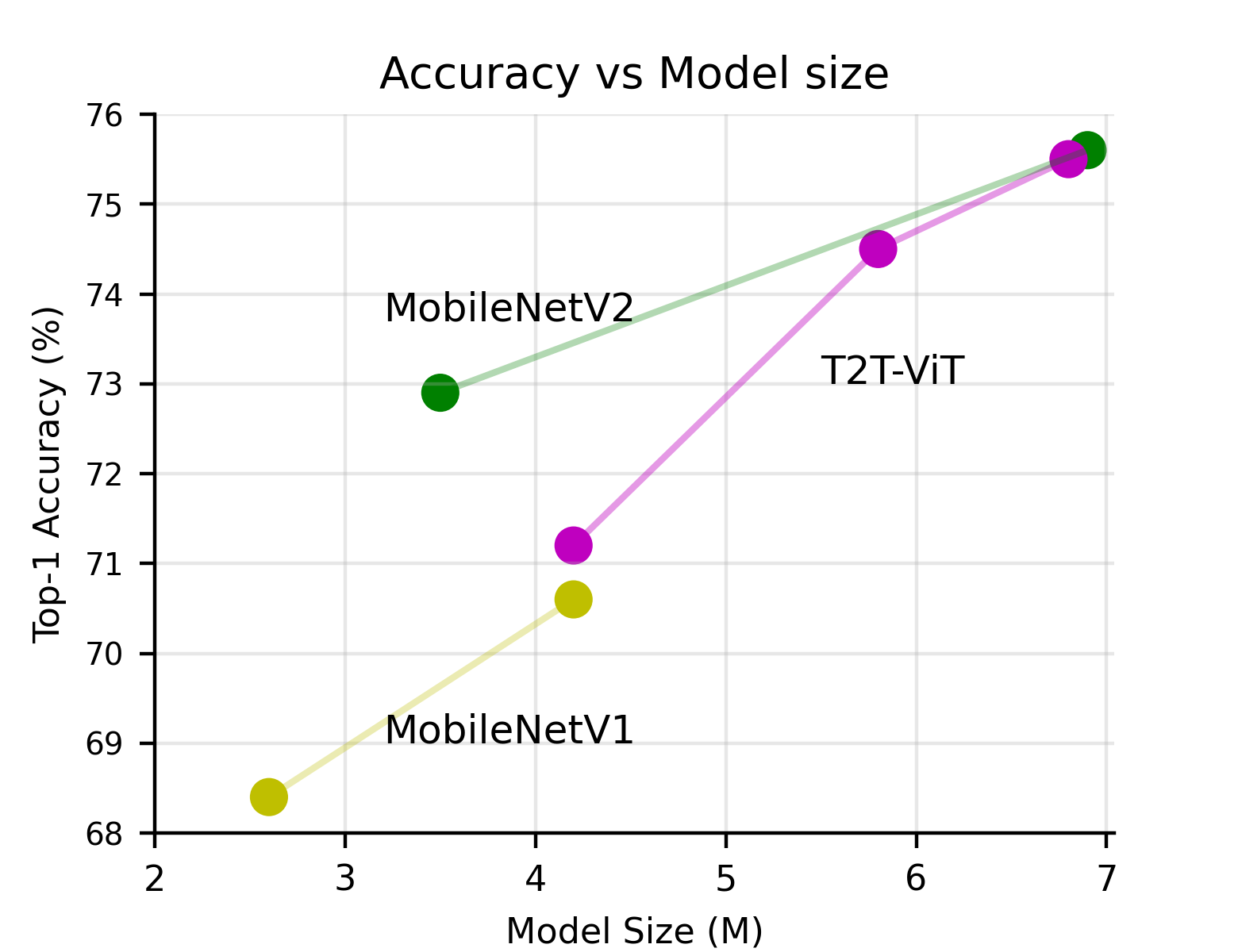
Transformers, which are popular for language modeling, have been explored for solving vision tasks recently, e.g., the Vision Transformers (ViT) for image classification. The ViT model splits each image into a sequence of tokens with fixed length and then applies multiple Transformer layers to model their global relation for classification. However, ViT achieves inferior performance compared with CNNs when trained from scratch on a midsize dataset (e.g., ImageNet). We find it is because: 1) the simple tokenization of input images fails to model the important local structure (e.g., edges, lines) among neighboring pixels, leading to its low training sample efficiency; 2) the redundant attention backbone design of ViT leads to limited feature richness in fixed computation budgets and limited training samples. To overcome such limitations, we propose a new Tokens-To-Token Vision Transformers (T2T-ViT), which introduces 1) a layer-wise Tokens-to-Token (T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure presented by surrounding tokens can be modeled and tokens length can be reduced; 2) an efficient backbone with a deep-narrow structure for vision transformers motivated by CNN architecture design after extensive study. Notably, T2T-ViT reduces the parameter counts and MACs of vanilla ViT by 200\%, while achieving more than 2.5\% improvement when trained from scratch on ImageNet. It also outperforms ResNets and achieves comparable performance with MobileNets when directly training on ImageNet. For example, T2T-ViT with ResNet50 comparable size can achieve 80.7\% top-1 accuracy on ImageNet. (Code: https://github.com/yitu-opensource/T2T-ViT)
翻译:用于语言建模的变异器最近被探索用于解决视觉任务。 例如, View 变异器( Vit) 用于图像分类。 ViT 模型将每个图像分割成固定长度的象征品序列, 然后将多个变异器层用于模拟其全球分类关系。 然而, ViT 与CNN 相比,在中度数据集( 如图像Net) 上从零开始训练时,其性能比CNN低。 我们发现这是因为:1) 输入图像的简单标记无法模拟相邻像素间的重要本地结构( 例如, 边缘, 线性( 线) 导致其低培训样本效率; 2 ViT 的冗余关注主干设计导致固定计算预算中的特性丰富度和有限的培训样本。 为了克服这些限制, 我们提议一个新的 Tokens- Tokent View 变异像器( T2T), 它可以引入1 层向Tokens- token (T) 的变异端变异器- t) 变异的变现, 变异的变异变变变异服务器的精精精的精精精精精精精精精精精精图, 也可以的变精精精的变精精精精精精精精精精精精精精精精精精精精精的图, 的变精精制的图制的图制的变精制的图制的变精制的图, 的变精制的变精制的图制的变精制的图制的图制的变精制的图制的图制的图制的图制的图制的图, 。