CVPR2020 | 用有噪声的学生网络进行自我训练提高ImageNet分类
点击蓝字关注我们
疫情还在继续,但是我们学术一直没有进入冰冻期,而且一些都会好起来!最近,我们一直致力于给大家带来CVPR2020最新最有意义的算法框架分享,有兴趣的同学,可以加入我们一起学习探讨,有能力的同学,我们可以自组实践小队,一起来复现!
在此,感谢大家对“计算机视觉战队”的支持与关注,之后我们会一直给大家带来更好的分享。

今天我们给大家带来关于分类的新技术,主要在ImageNet分类中有一定的提升。有兴趣的可以进行如下操作获取源码及论文下载链接。


扫描二维码
回复:Imagenet
获取论文及源码下载链接

背景及问题引出
近年来,深度学习在图像识别方面取得了显著的成功。然而,最先进的视觉模型仍然是用监督学习来训练的,这就需要大量的标记图像才能很好地工作。 通过只显示标记图像的模型,我们限制了我们自己使用更大数量的未标记图像来提高最先进模型的准确性和鲁棒性。
在这里,作者使用未标记的图像来提高最先进的图像网络精度,并表明精度增益对鲁棒性有着巨大的影响。为此,作者使用了一个更大的未标记图像语料库,其中很大一部分图像不属于ImageNet训练集分布(即它们不属于ImageNet中的任何类别)。

作者使用自我训练框架来训练新提出的模型框架,该框架主要有三个步骤:1)在标记图像上训练老师模型;2)使用老师在未标记图像上生成伪标签;3)在标记图像和伪标记图像的组合上训练学生模型。 最后把这个算法反复迭代了几次,把学生当作老师来重新标记未标记的数据并训练一个新学生。
新框架

上述的算法概述了用Noisy Student(或Noisy Student简称为Noisy)的自我训练。该算法的输入既有标记图像,也有未标记图像。使用标记图像训练老师模型使用标准交叉熵损失。然后使用老师模型在未标记的图像上生成伪标签。伪标签可以是soft(连续分布)或hard(one-hot分布)。然后,训练了一个学生模型,它最小化了标记图像和未标记图像上的交叉熵损失。最后迭代这个过程,把学生放回老师的位置,生成新的伪标签,并训练一个新的学生。该算法也如下图所示。
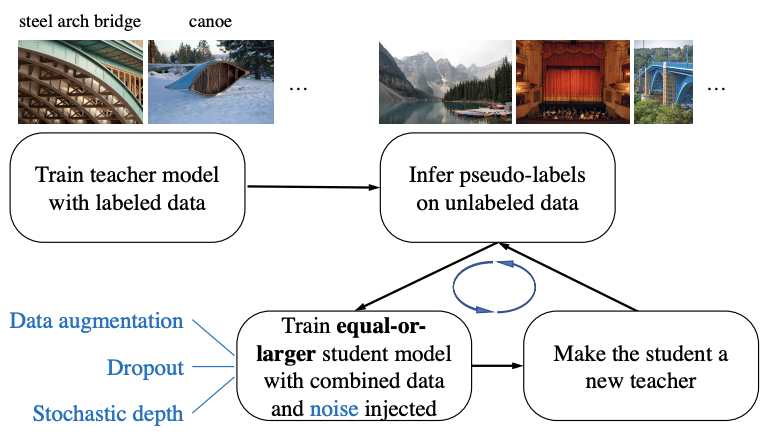
该算法从根本上说是自我训练,是半监督学习中的一种标准方法。关于新提出的方法如何与以前的工作相关的更多讨论我们慢慢来说,主要区别在于给学生增加更多的噪声源,并使用与老师一样大的学生模型。
这使得新提出的方法不同于知识蒸馏,其中添加噪声不是核心问题,小模型经常被作为学生,其比老师更快。作者可以把新提出的方法看作是知识扩展,在这种方法中,希望学生比老师更好,给学生模型更多的容量和困难的环境,在噪音方面学习。
Noising Student
当学生被故意通知时,它实际上被训练成与更强大的老师一致,当它生成伪标签时,它不会被通知。在实验中,使用了两种类型的噪声:输入噪声和模型噪声。对于输入噪声,作者使用RandAugment的数据增强。对于模型噪声,使用dropout和随机深度。
当应用于未标记数据时,噪声具有在标记数据和未标记数据上强制决策函数中局部平滑的复合好处。不同种类的噪声有不同的影响。对于数据增强噪声,学生必须确保图像,当转换为example,应该具有与非转换图像相同的类别。这种不变量鼓励学生模型学习超越老师,用更困难的图像进行预测。当dropout和随机深度函数作为噪声时,老师在推理时的行为就像一个集合(在此期间它生成伪标签),而学生的行为就像一个单一的模型。换句话说,学生被迫模仿一个更强大的集合模型。

噪声学生还有一个额外的技巧:数据过滤和平衡。具体来说,我们过滤的图像,老师模型有较低的信任,因为他们通常是领域外的图像。由于ImageNet中的所有类都有相似数量的标记图像,我们还需要平衡每个类的未标记图像的数量。为此,我们在没有足够图像的类中复制图像。对于有太多图像的类,我们以最高自信度为主的图像。
最后,在上面我们说伪标签可以是soft,也可以是hard。我们观察到soft和hard伪标签在我们的实验中都能很好地工作。特别是,软伪标签对域外未标记数据的工作效果略好。
实验及可视化
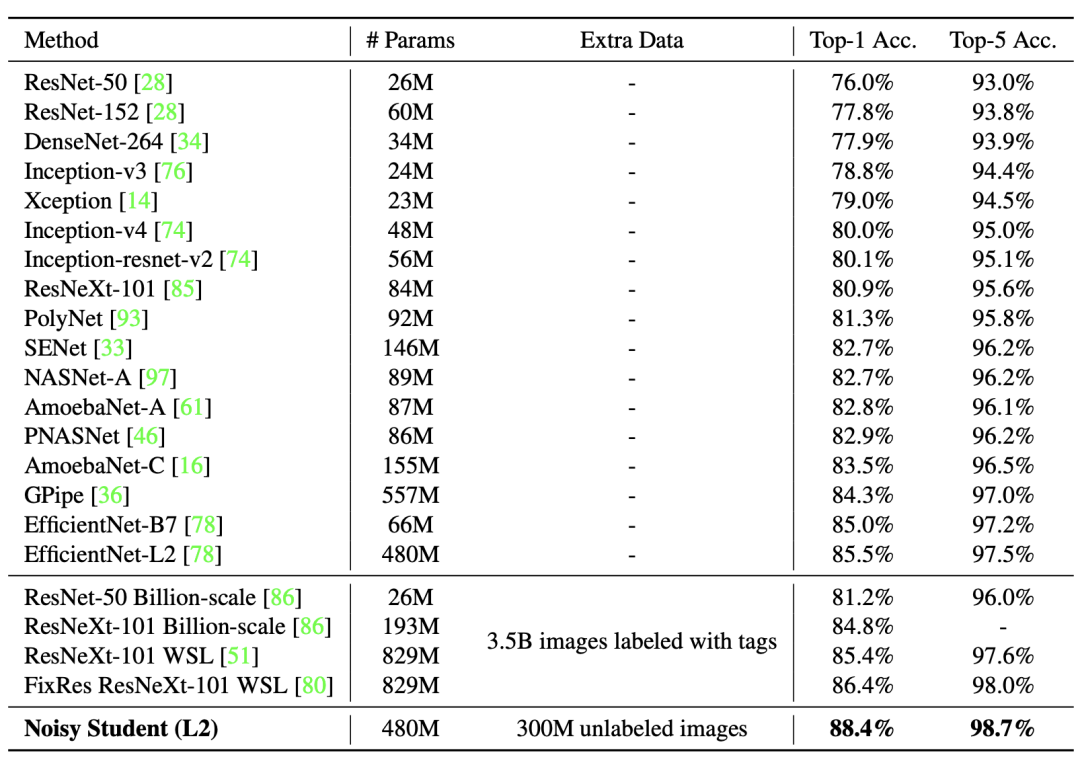
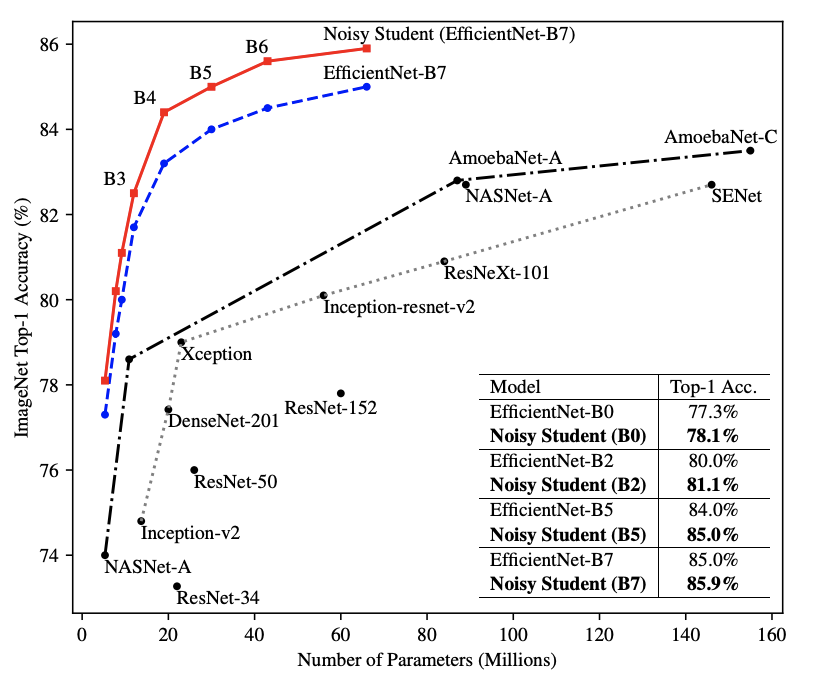
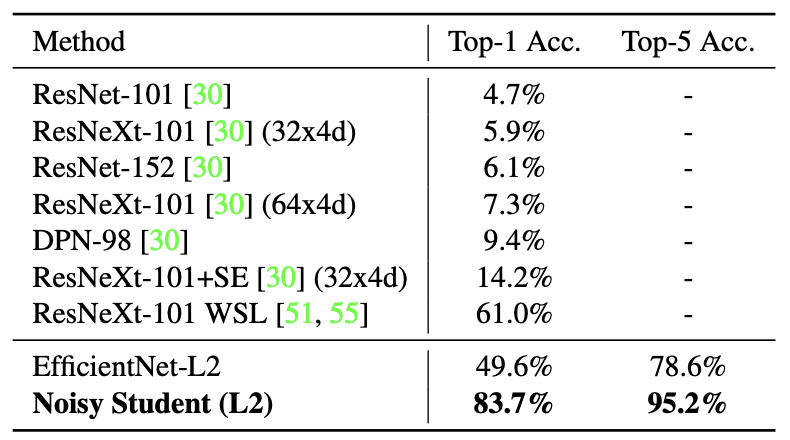
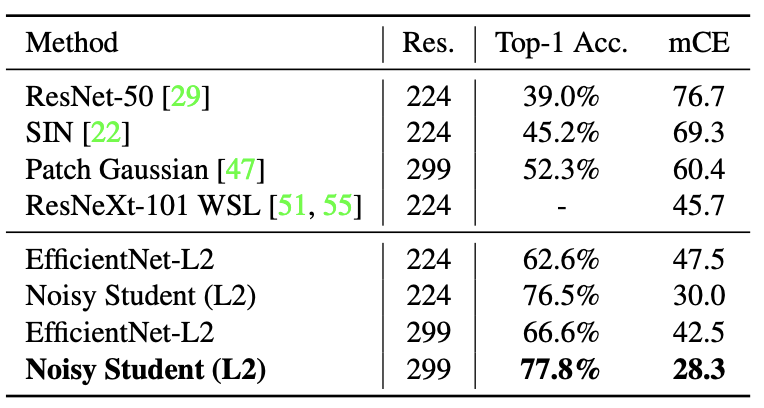
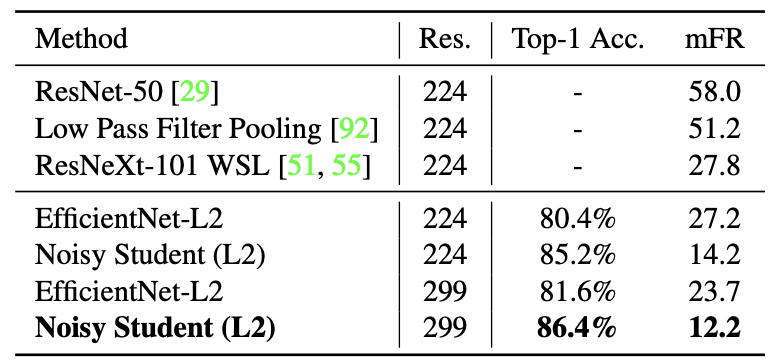

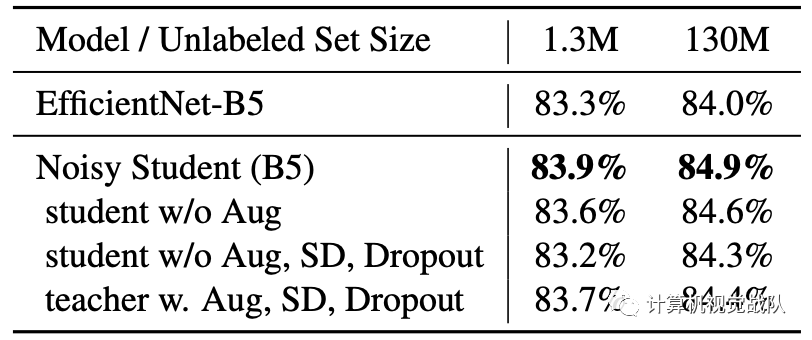
使用EfficientNet-B5作为老师模型,研究了两个不同数量的未标记图像和不同的增强的案例。

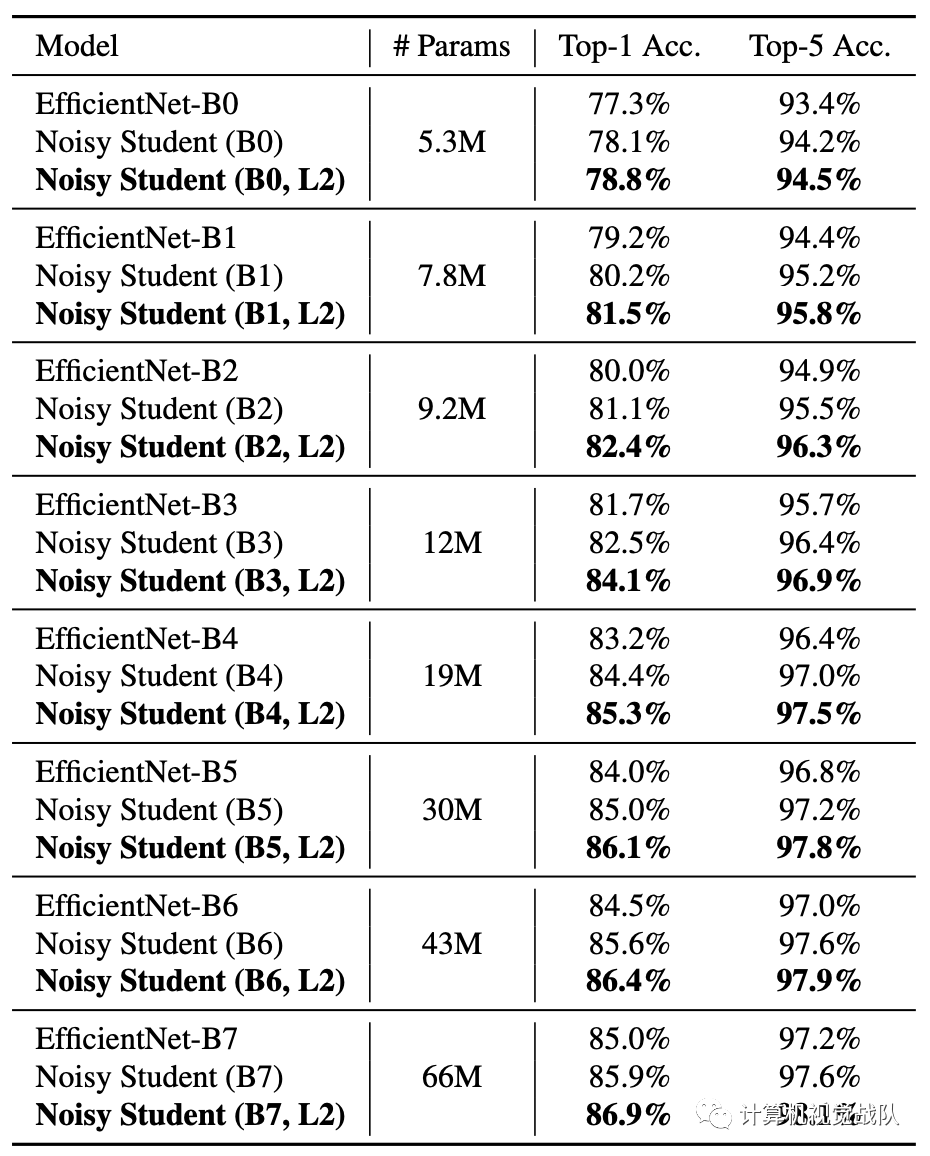
感谢(Qizhe Xie, Minh-Thang Luong, Eduard Hovy, Quoc V. Le)的Self-training with Noisy Student improves ImageNet classification
扫描二维码
回复:Imagenet
获取论文及源码下载链接



