Rocket Training: 一种提升轻量网络性能的训练方法
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:周国睿
来源:https://zhuanlan.zhihu.com/p/28625922
已获作者授权,请勿二次转载
Motivation
工业界,一些在线模型,对响应时间提出非常严苛的要求,从而一定程度上限制了模型的复杂程度。模型复杂程度的受限可能会导致模型学习能力的降低从而带来效果的下降。
目前有2种思路来解决这个问题:一方面,可以在固定模型结构和参数的情况下,用计算数值压缩来降低inference时间,同时也有设计更精简的模型以及更改模型计算方式的工作,如Mobile Net和ShuffleNet等工作;另一方面,利用复杂的模型来辅助一个精简模型的训练,测试阶段,利用学习好的小模型来进行推断。这两种方案并不冲突,在大多数情况下第二种方案可以通过第一种方案进一步降低inference时间,同时,考虑到相对于严苛的在线响应时间,我们有更自由的训练时间,有能力训练一个复杂的模型,所以我们采用第二种思路,来设计了我们的方法。
Our Approach
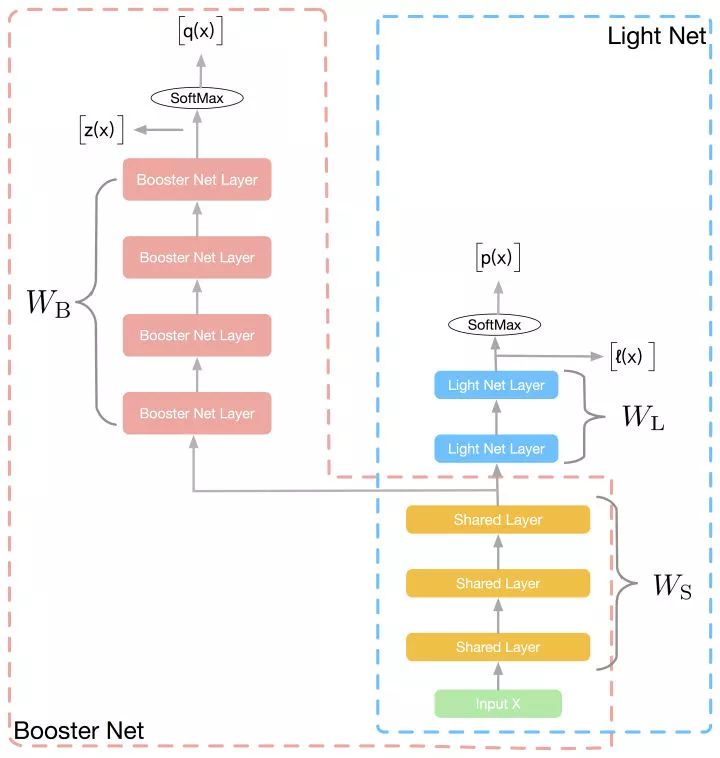
如图所示,训练阶段,我们同时学习两个网络:Light Net 和Booster Net, 两个网络共享部分信息。我们把大部分的模型理解为表示层学习和判别层学习,表示层学习的是对输入信息做一些高阶处理,而判别层则是和当前子task目标相关的学习,我们认为表示层的学习是可以共享的,如multi task learning中的思路。所以在我们的方法里,共享的信息为底层参数(如图像领域的前几个卷积层,NLP中的embedding), 这些底层参数能一定程度上反应了对输入信息的基本刻画。
![]()
整个训练过程,网络的loss如下:
Loss包含三部分:第一项,为light net对ground truth的学习,第二项,为booster net对ground truth的学习,第三项,为两个网络softmax之前的logits的均方误差(MSE),该项作为hint loss, 用来使两个网络学习得到的logits尽量相似。
Co-Training
两个网络一起训练,从而booster net的
会全程监督小网络
的学习,一定程度上,booster net指导了light net整个求解过程,这与一般的teacher-student 范式下,学习好大模型,仅用大模型固定的输出作为soft target来监督小网络的学习有着明显区别,因为booster net的每一次迭代输出
虽然不能保证对应一个和label非常接近的预测值,但是到达这个解之后一定能找到最终收敛的解
。
Hint Loss
Hint Loss这一项在SNN-MIMIC中采用的是和我们一致的对softmax之前的logits做L2 Loss:
Hinton的KD方法是在softmax之后做KL散度,同时加入了一个RL领域常用的超参temperature T:
也有一个半监督的工作再softmax之后接L2 Loss:
大家都没有给出一个合理的解释为什么要用这个Loss,而是仅仅给出实验结果说明这个Loss在他们的方法中表现得好。KD的paper中提出在T足够大的情况下,KD的Loss
是等价于
的。我们在论文里做了一个稍微细致的推导,发现这个假设T足够大使得
成立的情况下,梯度也是一个无穷小,没有意义了。同时我们在paper的appendix里 在一些假设下 我们从最大似然的角度证明了
的合理性。
Gradient Block
由于booster net有更多的参数,有更强的拟合能力,我们需要给他更大的自由度来学习,尽量减少小网络对他的拖累,我们提出了gradient block的技术,该技术的目的是,在第三项hint loss进行梯度回传时,我们固定booster net独有的参数
不更新,让该时刻,大网络前向传递得到的
,来监督小网络的学习,从而使得小网络向大网络靠近。
在预测阶段,抛弃booster net独有的部分,剩下的light net独自用于推断。整个过程就像火箭发射,在开始阶段,助推器(booster)载着卫星(light net)共同前进,助推器(booster)提供动力,推进卫星(light net)的前行,第二阶段,助推器(booster)被丢弃,只剩轻巧的卫星(light net)独自前行。所以,我们把我们的方法叫做Rocket Launching。
Experiments
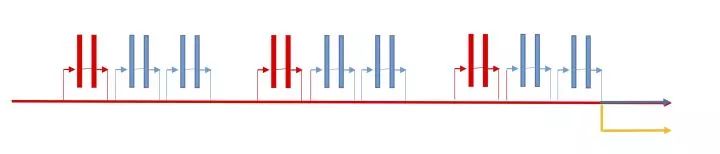
实验方面,我们验证了方法中各个子部分的必要性。同时在公开数据集上,我们还与几个teacher-student方法进行对比,包括Knowledge Distillation(KD), Attention Transfer(AT)。 为了与目前效果出色的AT进行公平比较,我们采用了和他们一致的网络结构宽残差网络(WRN)。 实验网络结构如下:
![]()
(a) bottom rocket net on wide residual net
![]()
(b) interval rocket net on wide residual net
红色+黄色表示light net, 蓝色+红色表示booster net。(a)表示两个网络共享最底层的block,符合我们一般的共享结构的设计。(b)表示两网络共享每个group最底层的block,该种共享方式和AT在每个group之后进行attention transfer的概念一致。
我们通过各种对比实验,验证了参数共享和梯度固定都能带来效果的提升:
![]()
通过可视化实验,我们观察到,通过我们的方法,light net能学到booster net的底层group的特征表示。
![]()
除了自身方法效果的验证,在公开数据集上,我们也进行了几组实验。
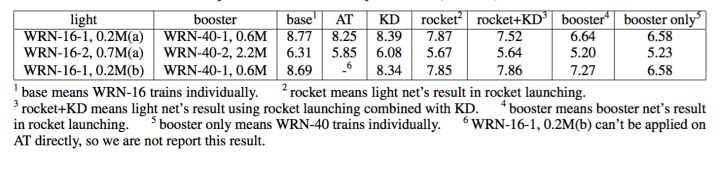
在CIFAR-10上, 我们尝试不同的网络结构和参数共享方式,我们的方法均显著优于已有的teacher-student的方法。在多数实验设置下,我们的方法叠加KD,效果会进一步提升。
![]()
这里WRN-16-1,0.2M 表示wide residual net, 深度为16,宽度为1,参数量为0.2M.
同时在CIFAR-100和SVHN上,取得了同样优异的表现:
![]()
真实应用
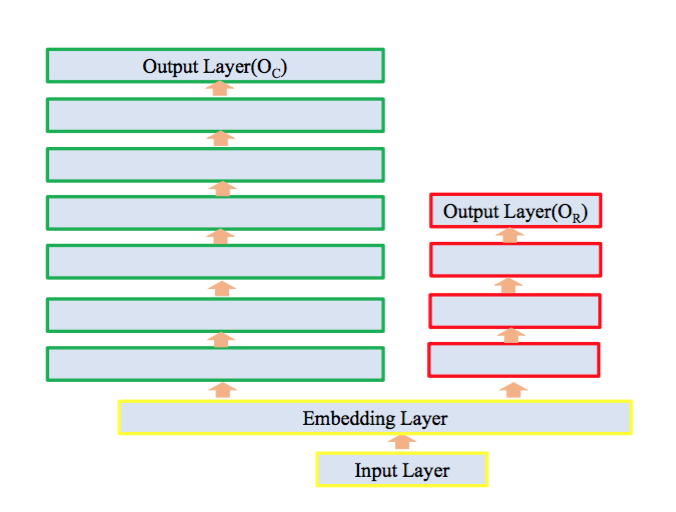
同时,在阿里展示广告数据集上,我们的方法,相比单纯跑light net, 可以将GAUC提升0.3%.
如图:
我们的线上模型在后面的全连接层只要把参数量和深度同时调大,就能有一个提高,但是在线的时候有很大一部分的计算耗时消耗在全连接层(embedding 只是一个取操作耗时随参数量增加并不明显),所以后端一个深而宽的模型直接上线压力会比较大。表格里列出了我们的模型参数对比以及离线的效果对比:
![]()
最后附上我们的paper 和code地址:
paper: https://arxiv.org/abs/1708.04106
code: https://github.com/zhougr1993/Rocket-Launching
















*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~



