Google AI再出大杀器!自监督学习ImageNet识别率历史新高87.4%,Jeff Dean点赞Quoc Le新论文
【导读】今天Google AI大神Quoc Le在Twitter发布他们最新研究成果,使用自训练噪声student模型使得经典ImageNet分类准确率取得Top-1 87.4%和Top-5 98.2%的历史新高,充分证明自监督学习的威力!谷歌大脑负责人 Jeff Dean点赞!
论文地址:
https://www.zhuanzhi.ai/paper/1bf282a0a1d4a67799b524c8c4eca406
后台回复“STI” 就可以获取《Self-training with Noisy Student improves ImageNet classification》下载链接~

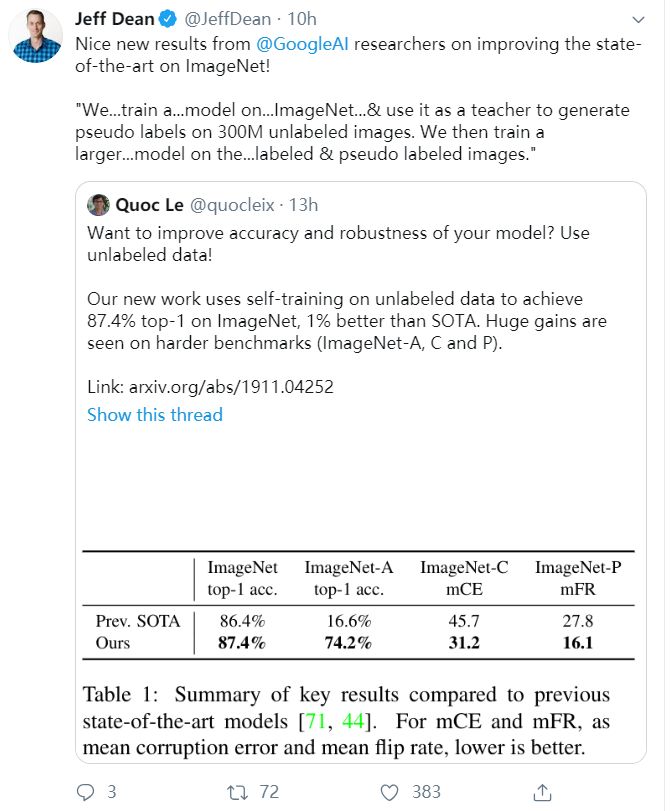
摘要:我们提出了一个简单的自训练方法,该方法能够在ImageNet数据集上达到84.7%的准确率,与原先最好的模型相比,性能提高了1.0%。在健壮的测试集上,该方法把ImageNet-A top-1的准确率从16.6%提升到74.2%,ImageNet-C的平均损坏误差(mCE)从45.7下降到31.2,Image-P 的平均翻转率(mFR)从27.8下降到16.1.
为了实现这个结果,我们首先在标记好的ImageNet 图片集上训练了一个EfficientNet模型,并且将它作为’teacher’在300M的未标记图片上生成伪标签。然后,我们在有标签和伪标签数据集上训练了一个更大的EfficientNet模型作为’student’。我们通过把‘student’放回’teacher’位置来重复这个过程。在生成伪标签的过程中,’teacher’模型没有掺杂噪声以便于生成的伪标签尽可能的接近真实情况。但是在’student’模型的学习过程中,我们注入了噪声,比如数据增强,dropout,给’student’模型设置随机深度,这样使得添加了噪声的’student’模型不得不更加努力地学习这些伪标签数据。
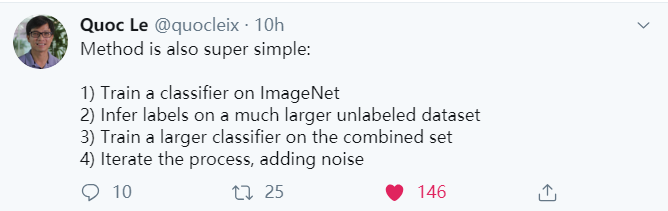
方法非常simple!
1)在标注图像上训练一个教师模型;
2)利用该教师模型在未标注图像上生成伪标签(pseudo label);
3)在标注和伪标注混合图像上训练一个学生模型。
4)最后,通过将学生模型当做教师模型,研究者对算法进行了几次迭代,以生成新的伪标签和训练新的学生模型。
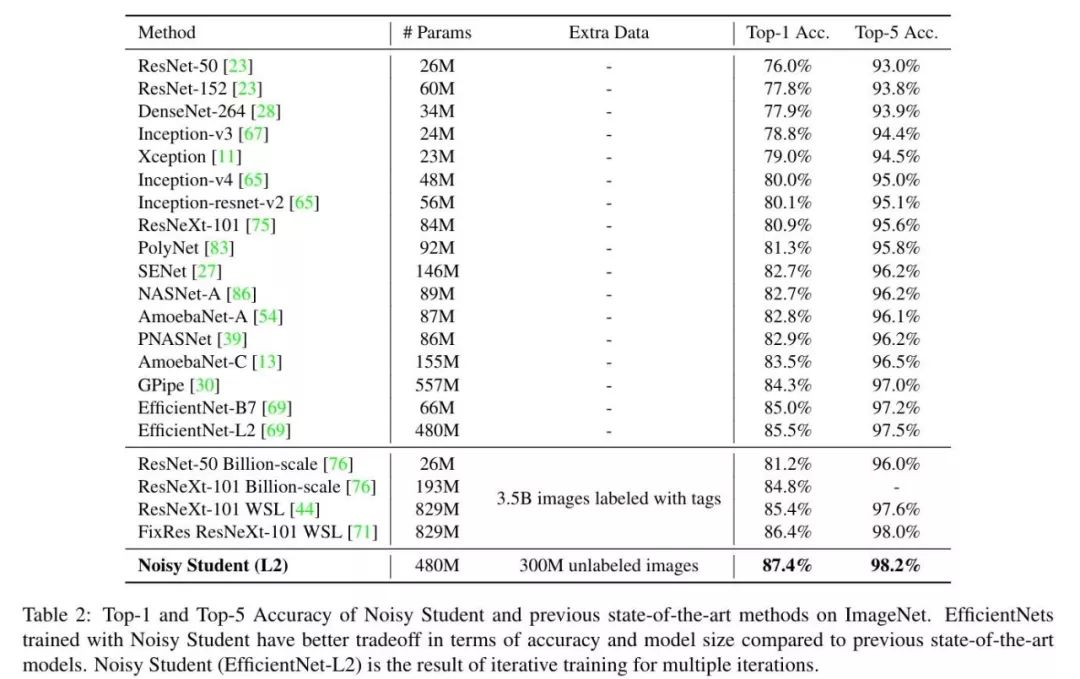
完全与最先进的ImageNet方法比较。Noisy student是我们的方法。Noisy Student+ EfficientNet 11%比你最喜欢ResNet-50😉
以 EfficientNet-L2 为主要架构的 Noisy Student 实现了 87.4% 的 Top-1 准确率,它显著超越了之前采用 EfficientNet 的准确率。其中 2.4% 的性能增益主要有两个来源:更大的模型(+0.5%)和 Noisy Student(+1.9%)。也就是说,Noisy Student 对准确率的贡献要大于架构的加深。

结论
https://www.youtube.com/watch?v=Y8YaU9mv_us
参考链接:
https://mp.weixin.qq.com/s/mwvOFOmC9CoAIGO1bf6Riw
https://www.youtube.com/watch?v=Y8YaU9mv_us
更多关于“ImageNet”的论文知识资料,请登录专知网站www.zhuanzhi.ai,查看:
https://www.zhuanzhi.ai/topic/2001583921558500/paper