点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
前言
近期 CVer 会陆续更新 CVPR 2020 论文开源项目系列,此系列的重点是:CVPR 2020 + 开源。上次分享了两篇文章,分别是目标检测和语义分割两大方向,详见:
这7篇CVPR 2020 目标检测论文项目都开源了!EfficientDet/ATSS/Hit-Detector/HTCN等
这7篇CVPR 2020 语义分割论文项目都开源了!SPNet/HANet/ContextPrior等
本文篇幅较长,推荐直接拉到文末,一键收藏,然后再看!
大家反映很喜欢这个系列,经常催更,这次终于整理好CV另一大方向:目标跟踪的part。喜欢的同学可以给个在看,也欢迎向文末CVer小助手催更你想要方向。
这里的论文开源项目,其实是指提供了代码链接的论文。也就是含coming soon的情况,因为没法深究这类论文究竟什么时候开源。
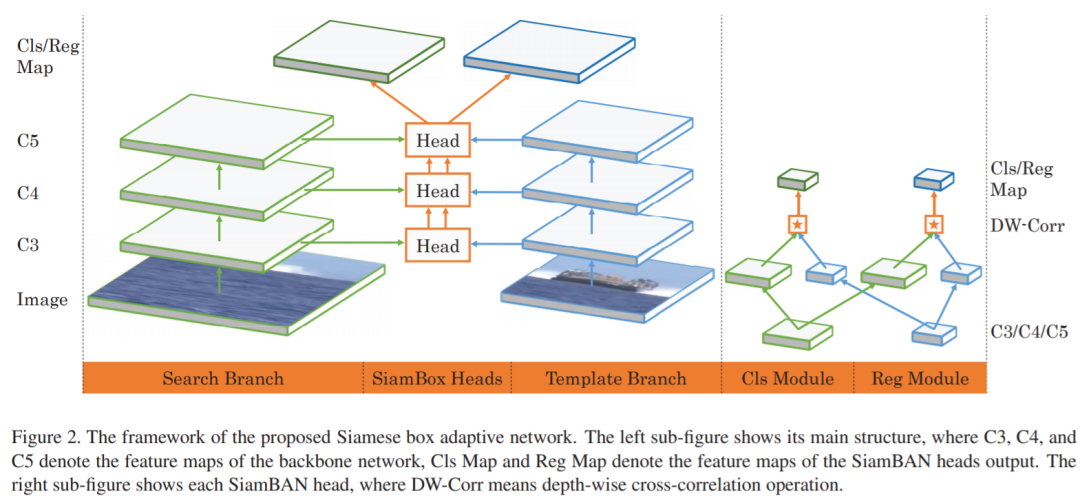
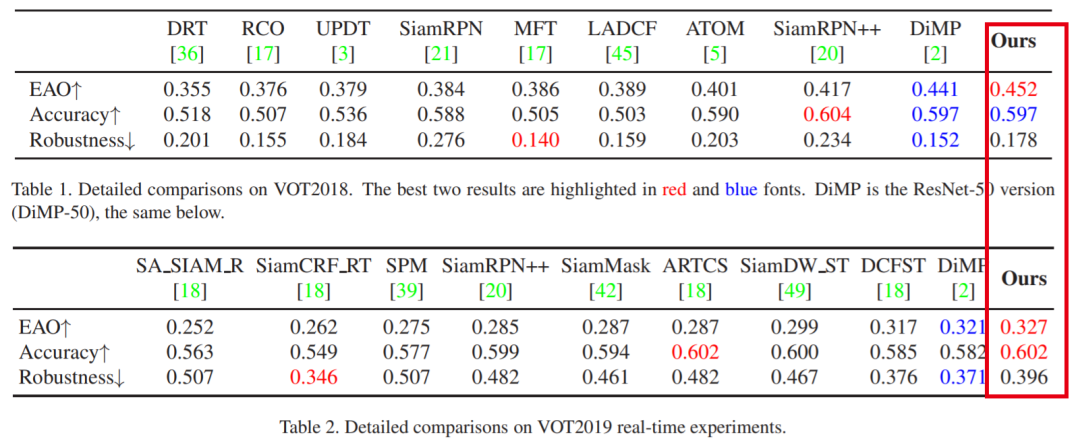
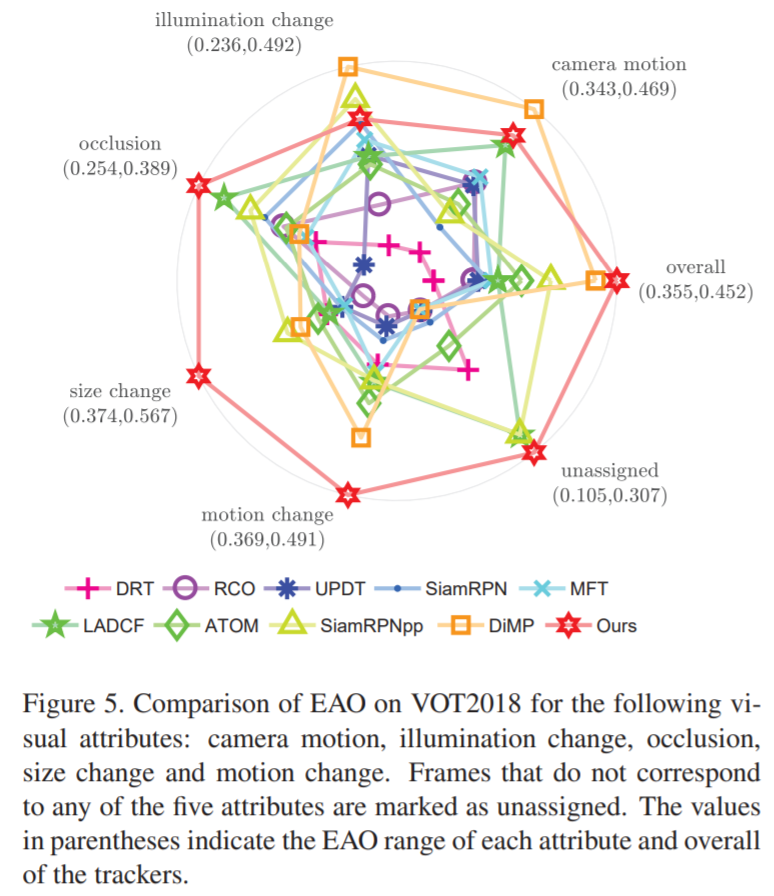
1. SiamBAN:面向目标跟踪的Siamese Box自适应网络
![]()
作者团队:华侨大学&中科院&哈工大&鹏城实验室&厦门大学等
论文链接:
https://arxiv.org/abs/2003.06761
代码链接:
https://github.com/hqucv/siamban
注:表现SOTA!速度高达40 FPS!性能优于DiMP、SiamRPN++和ATOM等网络。
大多数现有的跟踪器通常依赖于多尺度搜索方案或预定义的anchor boxes来准确估计目标的尺度和长宽比。不幸的是,它们通常要求启发式的配置。为解决此问题,我们通过利用全卷积网络(FCN)的表征能力,提出了一个简单而有效的视觉跟踪框架(名为Siamese Box Adaptive Network,SiamBAN)。SiamBAN将视觉跟踪问题视为并行分类和回归问题,因此可以直接对对象进行分类,并在统一的FCN中对它们的边界框进行回归。无先验box 设计避免了与候选box 相关的超参数,从而使SiamBAN更加灵活和通用。在包括VOT2018,VOT2019,OTB100,NFS,UAV123和LaSOT在内的视觉跟踪基准上进行的大量实验表明,SiamBAN具有最先进的性能并以40 FPS的速度运行,证实了其有效性和效率。
![]()
![]()
这个图很有意思!
![]()
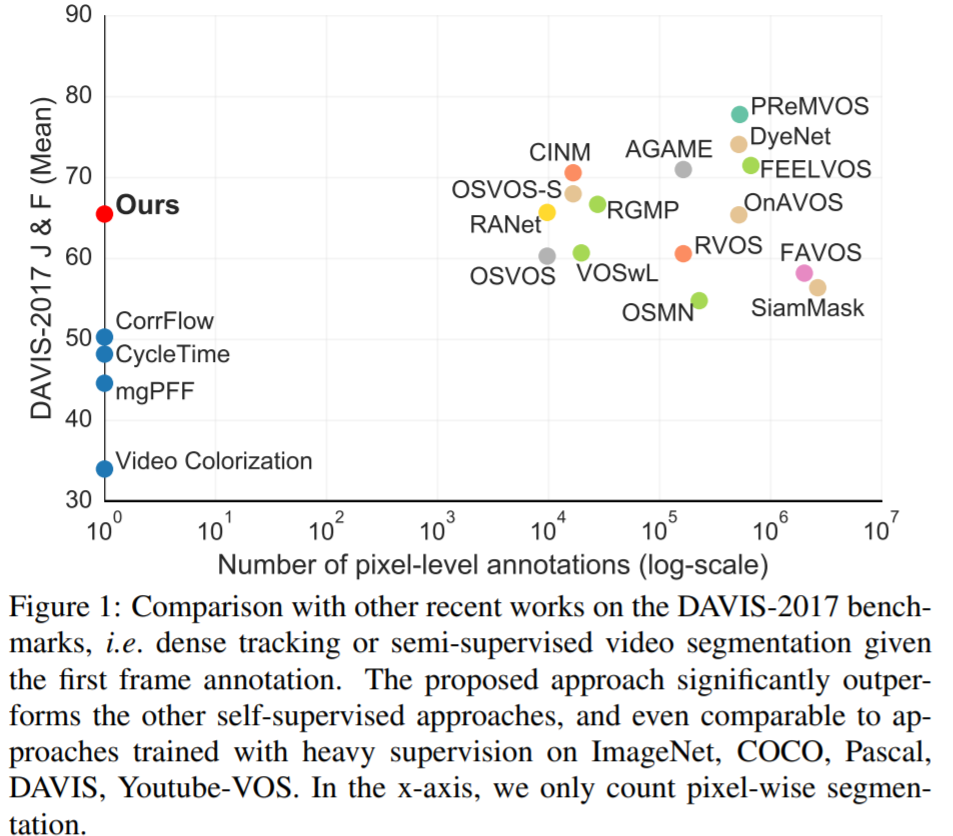
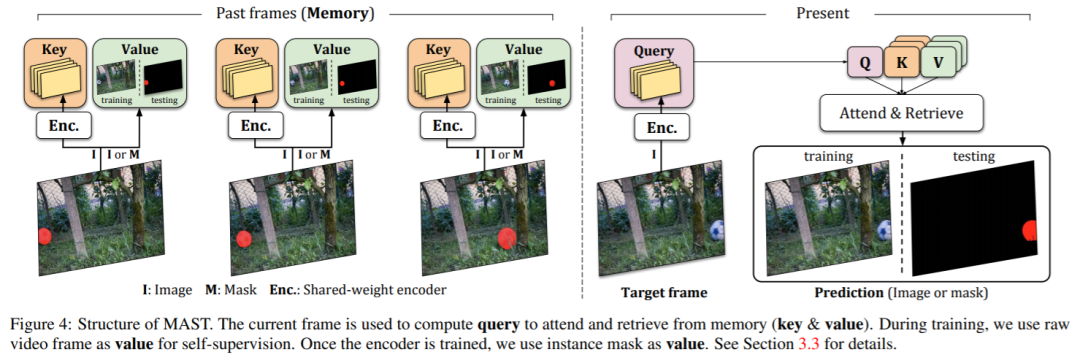
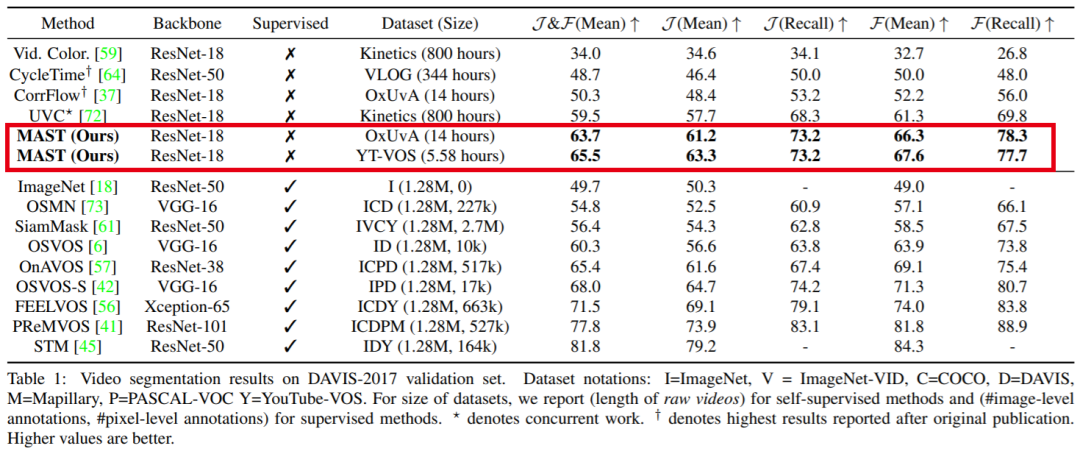
2. MAST:具有记忆增强功能的自监督目标跟踪器
![]()
论文链接:
https://arxiv.org/abs/2002.07793
代码链接:
https://github.com/zlai0/MAST
注:自监督目标跟踪新网络,表现SOTA!性能优于UVC、CorrFlow和CycleTime等网络,且接近监督类跟踪网络。
最近自监督密集跟踪的工作已取得了快速的进展,但是性能仍然远远达不到监督方法。我们提出了一种在视频上训练的密集跟踪模型,该视频模型没有任何标注,可以在现有基准上大大超过以前的自监督方法(+15%),并且可以达到与监督方法相当的性能。在本文中,我们首先通过进行彻底的实验,最终阐明最佳选择,来重新评估用于自监督训练和重建损失的传统选择。其次,我们通过使用关键的内存组件扩展我们的体系结构,进一步改进了现有方法。第三,我们以大规模的半监督视频对象分割(也称为密集跟踪)为基准,并提出了一个新的度量标准:generalizability。
![]()
![]()
![]()
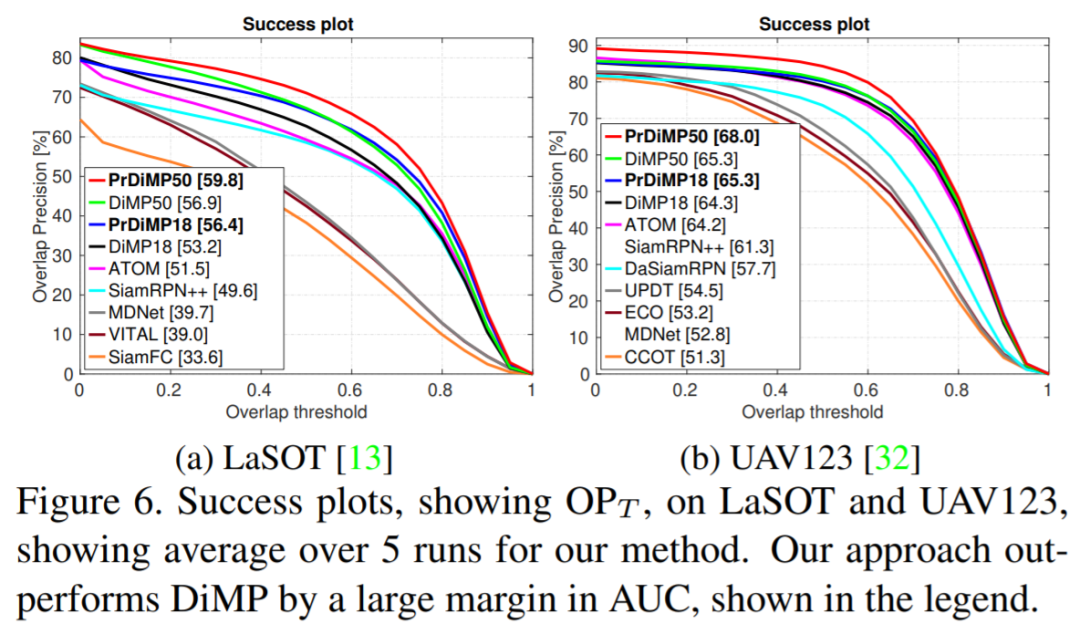
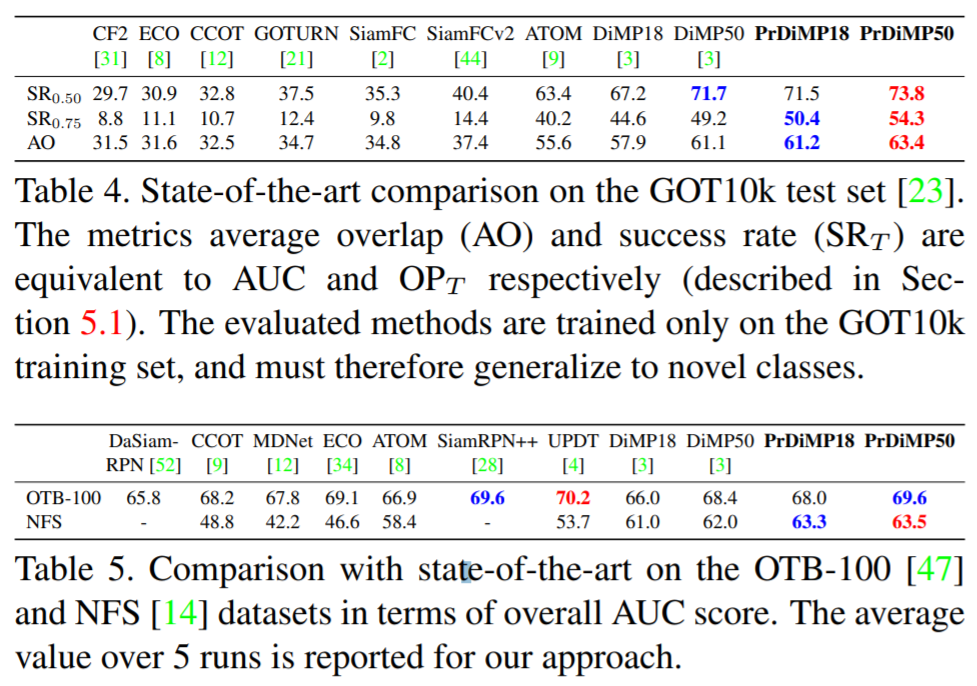
3. PrDiMP:目标跟踪的概率回归
![]()
论文链接:
https://arxiv.org/abs/2003.12565
代码链接:
https://github.com/visionml/pytracking
注:在六大数据集上,表现SOTA!性能优于DiMP、ATOM和SiamRPN++等网络,代码现已开源!
从根本上说,视觉跟踪是在每个视频帧中使目标状态回归的问题。尽管已经取得了重大进展,但跟踪器仍然容易出现故障和不准确之处。因此,至关重要的是在目标估算中表示不确定性。尽管当前的主要范式依赖于估计与状态有关的置信度得分,但是该值缺乏明确的概率解释,使它的使用变得复杂。因此,在这项工作中,我们提出了概率回归(probabilistic regression)公式,并将其应用于跟踪。我们的网络会根据输入图像预测目标状态的条件概率密度。至关重要的是,我们的方法能够对由于任务中不正确的标注和歧义而产生的标签噪声进行建模。通过最小化Kullback-Leibler散度来训练回归网络。当应用于跟踪时,我们的公式不仅允许输出的概率表示,而且还可以显著提高性能。我们的跟踪器在六个数据集上设置了最新的技术,在LaSOT上实现了59.8%的AUC,在TrackingNet上实现了75.8%的成功。
![]()
![]()
4. AutoTrack:通过自动时空正则化实现无人机目标跟踪
![]()
论文链接:
https://arxiv.org/abs/2003.12949
https://github.com/vision4robotics/AutoTrack
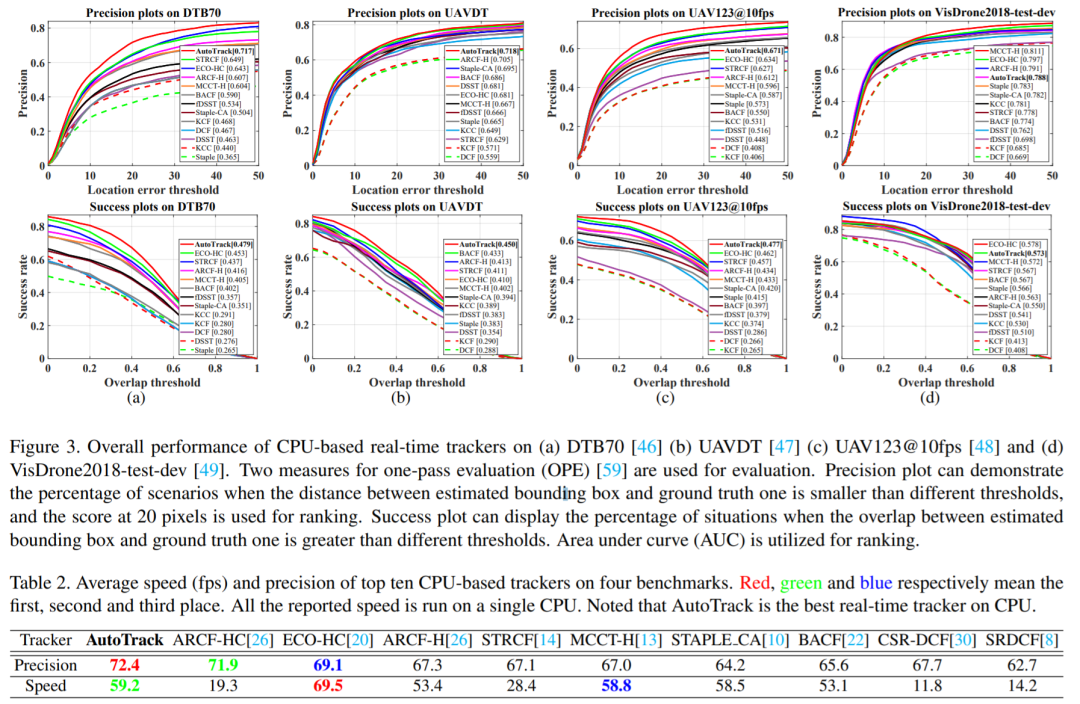
注:无人机目标跟踪新网络,在CPU上高达 60 FPS!性能优于ECO-HC、ARCF-HC等网络
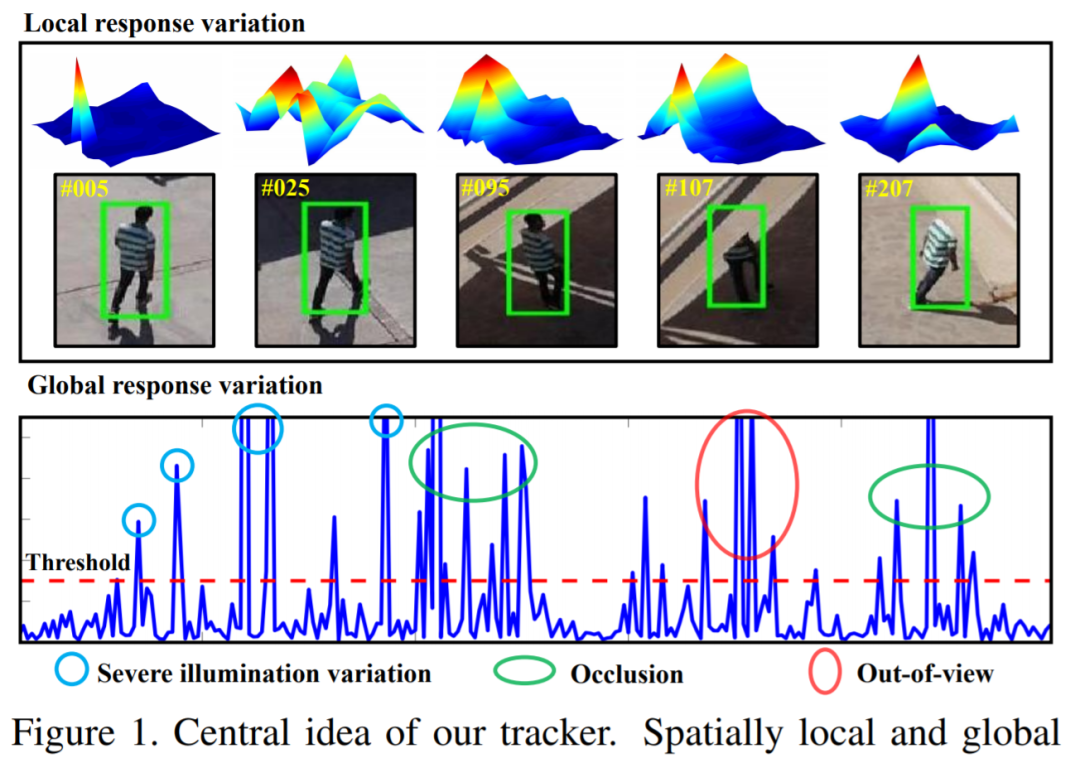
现有的大多数基于判别相关滤波器(DCF)的跟踪器试图引入预定义的正则化项以改善目标对象的学习,例如,通过抑制背景学习或通过限制相关滤波器的变化率。但是,预定义的参数在调整它们时会花费很多精力,并且它们仍然无法适应设计人员没有想到的新情况。在这项工作中,提出了一种新颖的方法来自动在线自适应地学习时空正则项。引入空间局部响应图变化作为空间正则化,以使DCF专注于对象的可信赖部分的学习,而全局响应图变化确定滤波器的更新率。与基于CPU和GPU的最新跟踪器相比,在四个UAV基准上进行的广泛实验证明了我们方法的优越性,在单个CPU上每秒可运行约60帧。我们的跟踪器还被建议用于无人机定位。在室内实际场景中进行的大量测试证明了我们的定位方法的有效性和多功能性。
![]()
![]()
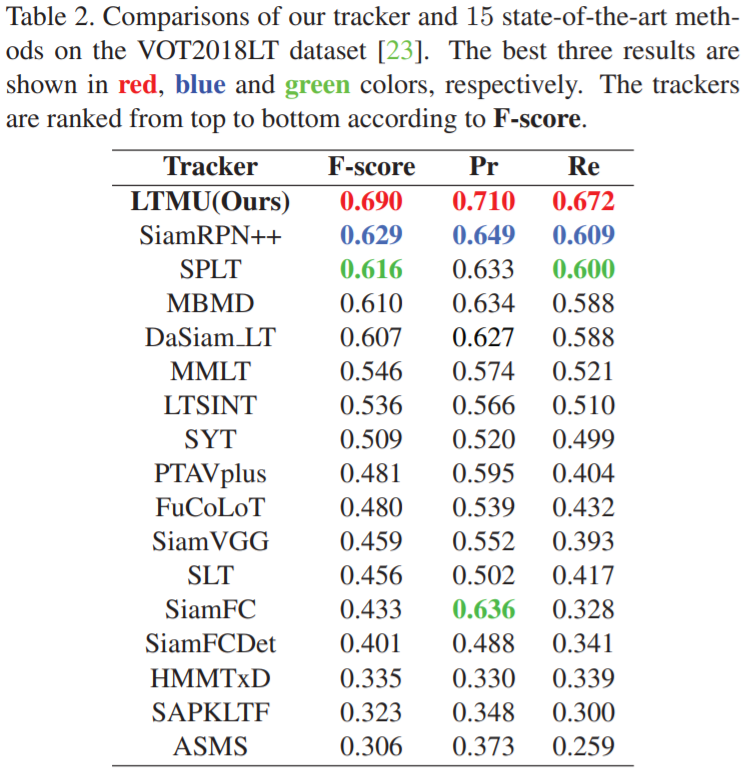
5. LTMU:使用Meta-Updater进行高性能的长时跟踪
![]()
论文链接:
https://arxiv.org/abs/2004.00305
代码链接:
https://github.com/Daikenan/LTMU
注:表现SOTA!性能优于SiamRPN++、SPLT和MBMD等网络
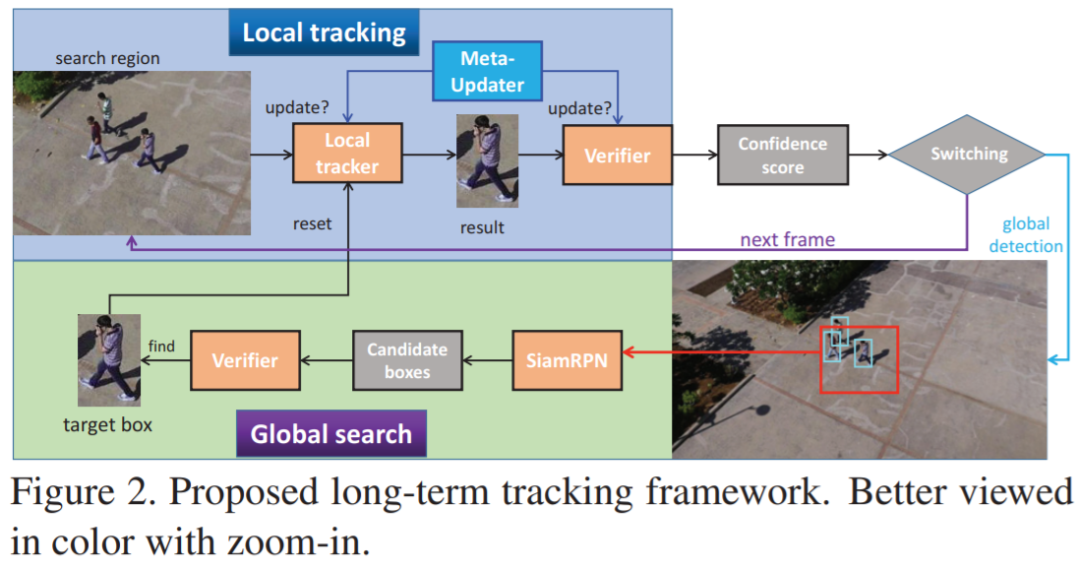
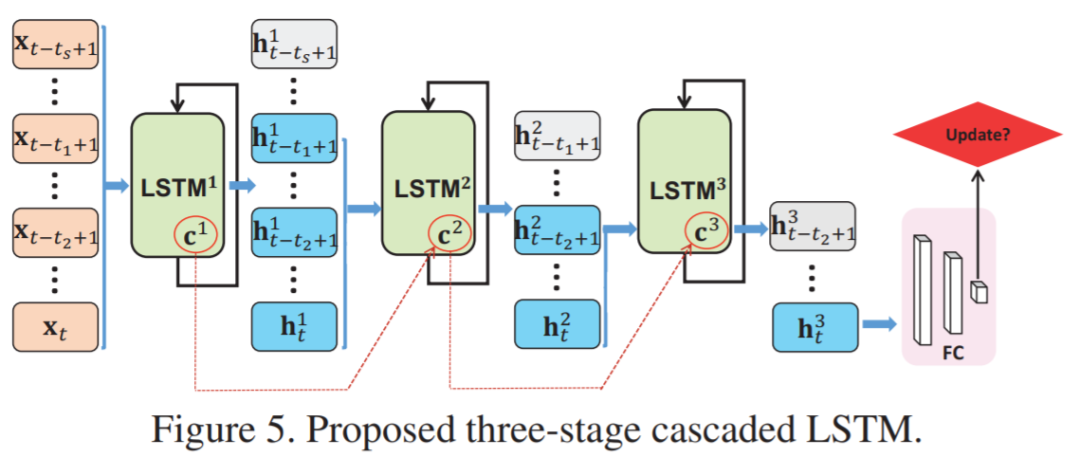
长时(Long-term)视觉跟踪引起了越来越多的关注,因为它比短时跟踪更接近实际应用。大多数排名靠前的长时跟踪器采用离线训练的Siamese 体系结构,因此,他们无法从在线更新的短时跟踪器的巨大进步中受益。但是,由于长时的不确定性和嘈杂的观察,直接引入基于在线更新的跟踪器来解决长时问题是非常冒险的。在这项工作中,我们提出了一种新颖的离线训练型Meta-Updater,以解决一个重要但尚未解决的问题:跟踪器是否准备好在当前框架中进行更新?提出的Meta-Updater可以按顺序有效地集成几何,判别和外观提示,然后使用设计的级联LSTM模块挖掘顺序信息。我们的Meta-Updater学习二进制输出以指导跟踪器的更新,并且可以轻松地嵌入到不同的跟踪器中。这项工作还介绍了一个长时跟踪框架,该框架由在线本地跟踪器,在线验证器,基于SiamRPN的重新检测器和我们的元更新器组成。在VOT2018LT,VOT2019LT,OxUvALT,TLP和LaSOT基准测试中的大量实验结果表明,我们的跟踪器的性能明显优于其他竞争算法。
![]()
![]()
![]()
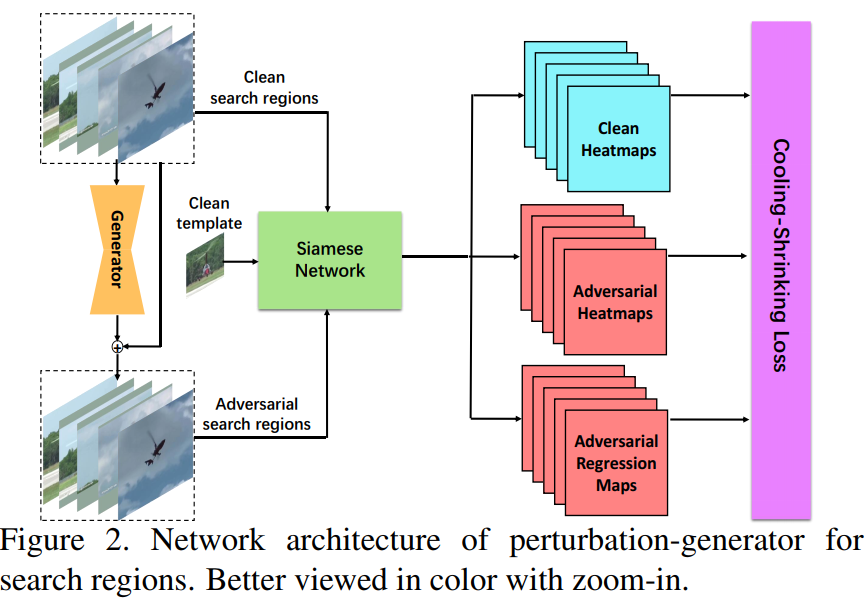
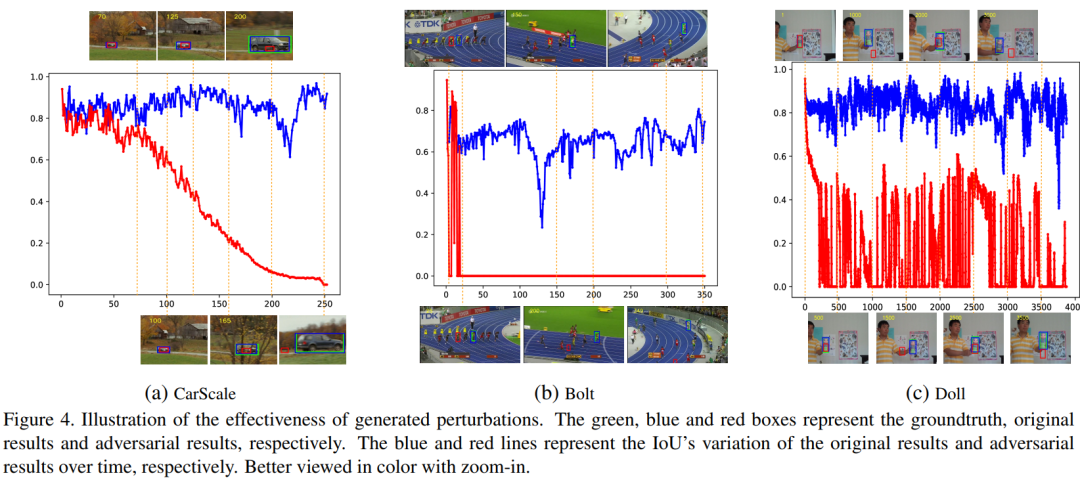
6. Cooling-Shrinking Attack: Blinding the Tracker with Imperceptible Noises
![]()
论文链接:
https://arxiv.org/abs/2003.09595
代码链接:
https://github.com/MasterBin-IIAU/CSA
注:本文提出一种针对 SiamRPN++ 的对抗攻击算法,可以
使SiamRPN++跟踪器的性能大幅度下降。
![]()
![]()
这攻击的酸爽
![]()
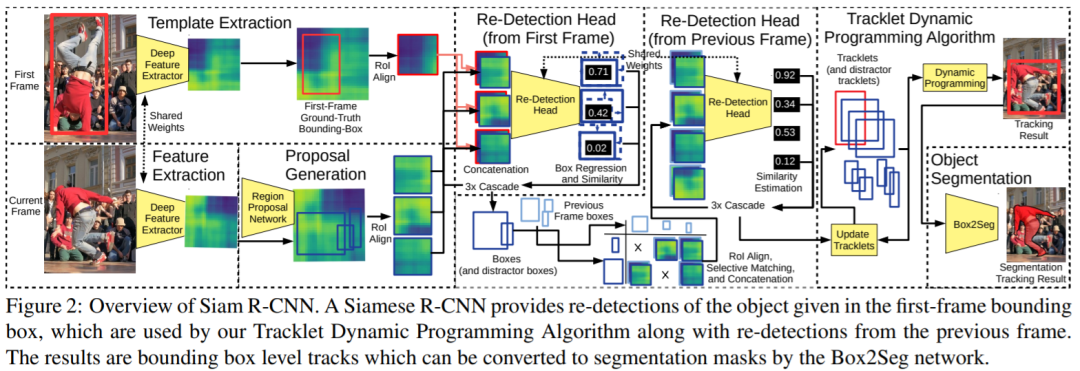
7. Siam R-CNN:通过重新检测进行视觉跟踪
![]()
https://www.vision.rwth-aachen.de/page/siamrcnn
论文链接:
https://arxiv.org/abs/1911.12836
https://github.com/VisualComputingInstitute/SiamR-CNN
注:
Siam R-CNN性能优于 SiamRPN++、DiMP和SiamFC等网络
![]()
![]()
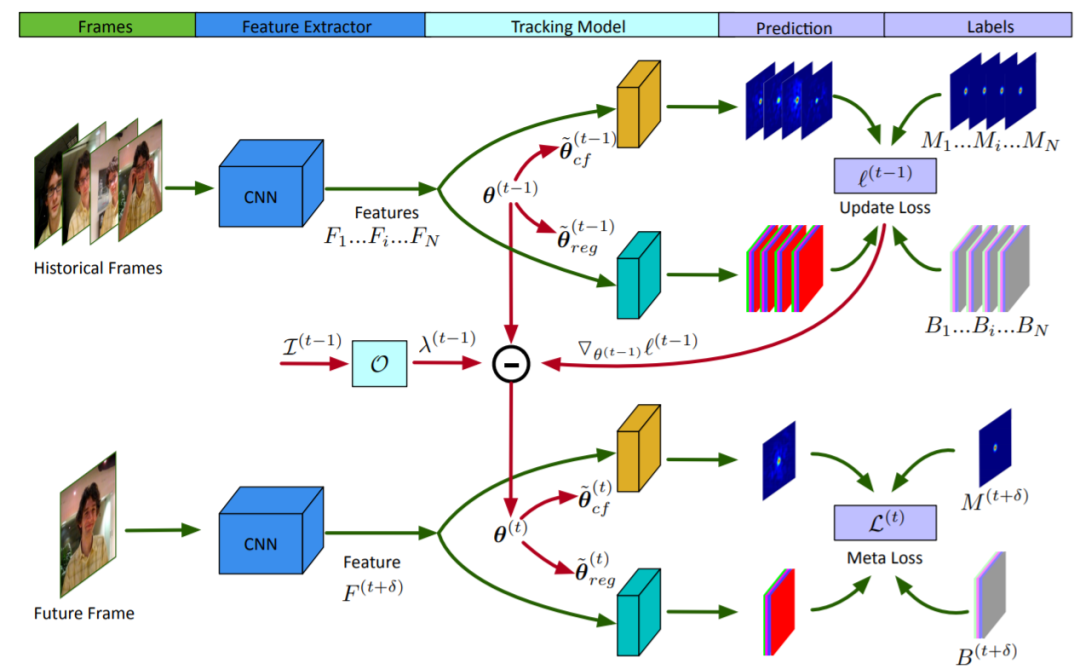
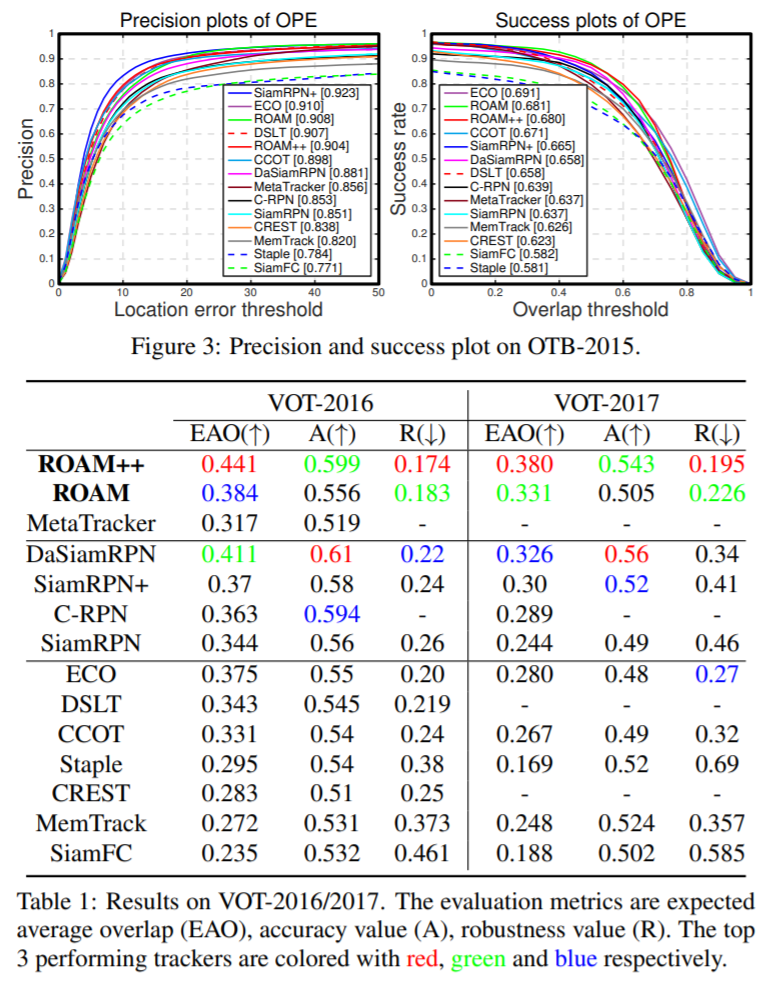
8. ROAM:循环优化目标跟踪模型
![]()
作者团队:腾讯AI Lab&香港城市大学&滴滴出行
论文链接:
https://arxiv.org/abs/1907.12006
代码链接:
https://github.com/skyoung/ROAM
注:
在OTB、VOT等数据集上,表现SOTA!性能优于MetaTracker、DaSiamRPN和MDNet等网络
在本文中,我们设计了一个由响应生成和边界框回归组成的跟踪模型,其中第一个组件产生一个热图,以指示物体在不同位置的存在,第二部分将相对边界框位移回归到在其上的anchor滑动窗口位置。由于两个组件都使用了可调整大小的卷积filter来适应对象的形状变化,因此我们的跟踪模型无需枚举大小不同的anchor,从而节省了模型参数。为了有效地使模型适应外观变化,我们建议离线训练循环神经优化器以在元学习设置中更新跟踪模型,这可以在几个梯度步骤中使模型收敛。这提高了更新跟踪模型的收敛速度,同时获得了更好的性能。我们在OTB,VOT,LaSOT,GOT-10K和TrackingNet基准测试中对我们的跟踪器ROAM和ROAM++进行了广泛的评估,并且我们的方法相对于最新的算法表现良好。
![]()
![]()
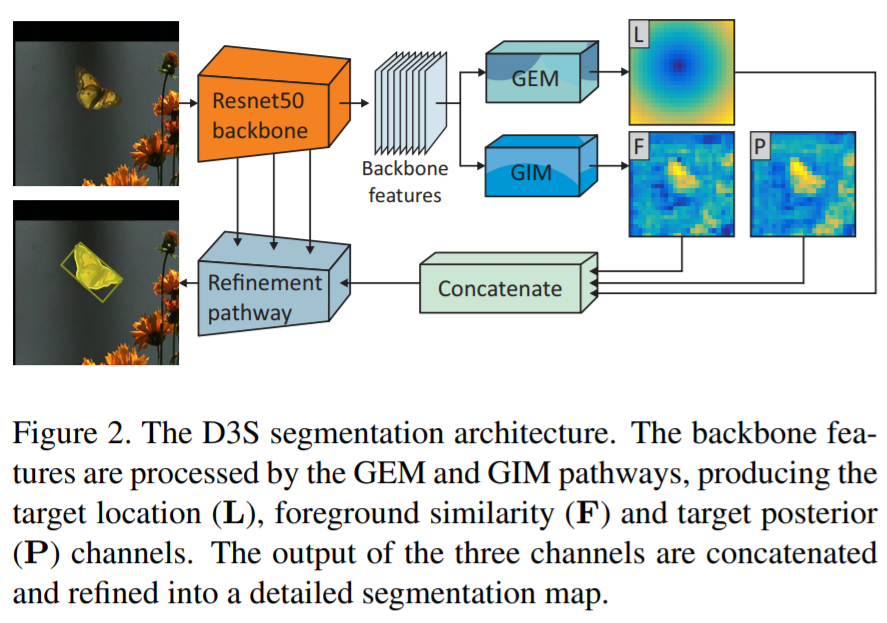
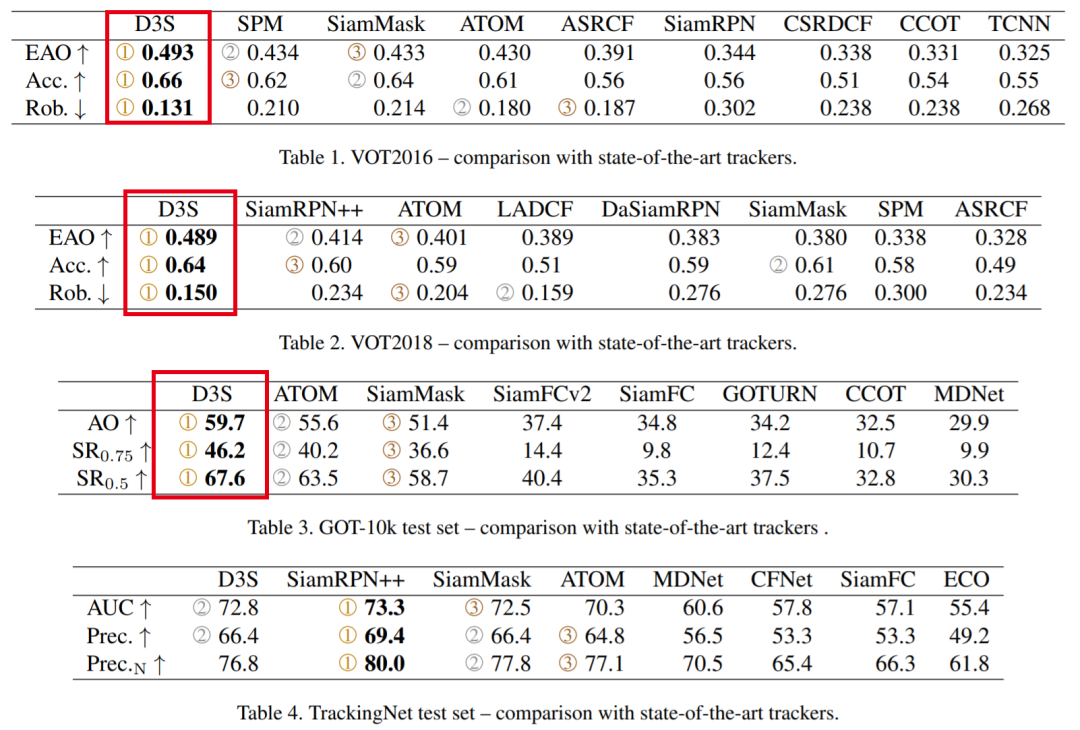
9. D3S:判别式Single Shot分割目标跟踪器
![]()
论文链接:
https://arxiv.org/abs/1911.08862
代码链接:
https://github.com/alanlukezic/d3s
注:
性能优于SiamRPN++、ATOM和SiamMask等网络,速度可达25 FPS!
基于模板的判别式跟踪器由于其健壮性目前是主要的跟踪范例,但仅限于边界框跟踪和有限范围的转换模型,这降低了其定位精度。我们提出了一种判别式的single-shot分割跟踪器-D3S,它缩小了视觉对象跟踪和视频对象分割之间的差距。Single-shot网络应用两个具有互补几何特性的目标模型,一个对广泛的变换(包括非刚性变形)保持不变,另一个模型则假定为刚性对象,以同时实现高鲁棒性和在线目标分割。D3S无需按数据集进行微调,并且仅针对分割进行训练作为主要输出,因此在VOT2016,VOT2018和GOT-10k基准测试中,其性能均优于所有跟踪器,并且在TrackingNet上的性能接近最先进的跟踪器。D3S在视频对象分割基准上胜过领先的分割跟踪器SiamMask,并且与顶级视频对象分割算法表现相当,同时运行速度快了一个数量级,接近实时。
![]()
![]()
上述9篇论文的PDF和代码链接已经打包好,在CVer公众号后台回复:0510,即可下载。另外想第一时间知道更多论文的开源动态,欢迎加文末的CVer小助手微信,其朋友圈每天会推送最新论文和开源项目。整理不易,欢迎在文末点个
在看
,支持一下!
重磅!CVer-目标跟踪 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标跟踪 微信交流群,目前已汇集1400人!涵盖单目标跟踪、多目标跟踪等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、TensorFlow和PyTorch等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标跟踪+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
整理不易,请给CVer一个在看!![]()