刷新WIDER Face多项记录!创新奇智提出高性能精确人脸检测算法
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | 胡孟
本文转载自公众号CVer
原文 | https://zhuanlan.zhihu.com/p/66793697
《Accurate Face Detection for High Performance》

arXiv: https://arxiv.org/abs/1905.01585
作者团队:创新奇智
本笔记记录人脸检测算法 AFD_HP,来自AInnovation Technology Ltd, beijing(创新奇智),和PyramidBox++、VIM-FD、Improved SRN有点类似,都是性能小怪兽,在wider face上排名靠前,引入了现有人脸检测中很优秀的子模块,所有子模块都能对结果有积极影响(不过文中并没有消融实验评估各个子模块的贡献率),最终性能在wider face上就sota了;
反正我是觉得蛮厉害的,现在大家被优质的论文把眼界调高了,希望算法不仅有足够的创新性,还要有强悍的性能,但二者能做到其一也是很难的,特别是这种融合多种现有方案的算法,不仅要靠自己去实现 + 融合,还得各种试错和调参,以找到最佳的性能点,而且论文里展示的都是作者尝试后有积极效果的方案,背后不知道有多少试错的工作量呢,恩恩,respect~~~
名词定义
1 AFD_HP:本文提出的人脸检测算法Accurate Face Detection for High Performance,基于1-stage RetinaNet + IoU loss的bbox reg + SRN的 2-step bbox cls、reg策略 + PyramidBox训练阶段的 DAS 数据增强策略 + S3FD的max-out label + multi-scale inference;为了笔记记录的方便,我做了个简写:AFD_HP;
Abstract
1 现有人脸检测算法在处理小尺度人脸时,所采用的方案如:新的网络结构、新的loss function等;
2 本文提出AFD_HP,基于1-stage RetinaNet + IoU loss的bbox reg + SRN的 2-step bbox cls、reg策略 + PyramidBox训练阶段的 DAS 数据增强策略 + S3FD的max-out label + multi-scale inference,最终在wider face上sota;
1 Introduction
人脸检测任务:找出图像中所包含的人脸,并给出bbox的位置信息;为解决自然场景下的人脸检测问题,CNN-based方案有很多,如cascade-based的Cascade CNN、MTCNN、FaceCraft等,联合人脸区域附近上下文信息的HR、SSH、CMS-CNN等,全新网络结构设计的MSCNN、SRN、FANet等,基于通用目标检测模型,并结合进一步人脸优化策略的Face R-CNN、Face-R-FCN、S3FD、ZCC等,训练阶段采用全新数据增强策略的DSFD、Pyramidbox、Improved SRN等,结合feature map上 attention 机制的FAN、VIM-FD等;
2 Related Work
2.1 Traditional Method
传统的Adaboost方案:Haar-Like features + cascade face / non-face分类器,当然也有更牛逼特征 + 分类器的改进;然后各种DPM-based方案用于人脸 / 目标检测,不过速度比较慢,并且训练阶段可能需要引入其他额外的标注信息;
整体上就是,不够鲁棒的hand-crafted特征,及性能比较弱鸡的分类器,以及无法做到全局end2end优化的问题;
2.2 Deep Learning Method
基本上囊括了现阶段所有人脸检测算法,篇幅颇大:
Cascade CNN、FaceCraft的cascade CNN-based方案;
MTCNN、PCN做人脸landmarks / angles的multi-task + 进阶人脸检测方案(coarse-to-fine manner + cascade-style structure);
Faceness:将整个人脸分解成多个人脸器官(5个CNN模型:hair、eyes、nose、mouth、beard),在每个器官上分别训练一个attribute-aware CNN,再融合score map,对遮挡人脸、大姿态变化人脸检测效果良好;缺点:需要额外标定人脸属性;
LDCF+:比较老干部,使用boosted决策树的分类器来检测人脸;
UnitBox:介绍了IoU损失函数,来直接最小化pred bbox与gt bbox间的IoU,以期更精准的bbox定位;
ScaleFace:整体上和SSD有点类似,多层预测face bbox,而且相邻feature map间还做了融合,在不同feature map上预定义了不同大小的anchor尺度(低层小尺度、高层大尺度);但整体上架构还是走frcnn的路子,有rpn、fast rcnn模块;
SAFD:使用CNN处理人脸尺度的变化,预先根据图像利用CNN算出图像要缩放的尺度,也即SAFD根据检测出的人脸尺度,仅需resize若干尺度图像,在稀疏采样的图像金字塔上检测人脸目标即可,相当于SAFD中的SPN提供了图像中人脸尺度的先验,可以有针对性的对图像做缩放;
HR:在特征金字塔上为不同尺度人脸独立地训练检测器,对小尺度人脸结合了上下文信息的辅助,设置了大尺度感受野的模板;
S2AP:融合了SAFD的思想,SAFD做了尺度分支的预测,以加速人脸的检测速度,S2AP在SAFD上更进一步,做了空间位置分支的预测,更进一步地提升了人脸检测速度,也即在尺度、空间两个维度上减少对人脸检测的搜索空间,达到提速目的:
ZCC:提出EMO(Expected Max Overlapping score)概念,来评估anchor与gt bbox的匹配质量;ZCC基于frcnn、ssd的anchor机制,作者认为小尺度人脸检测不到的主要原因是因为anchor bbox与小尺度人脸的IoU过低,现有基于anchor的人脸检测器处理尺度不变性并不给力;作者提出了EMO得分来解释IoU低的原因,并提出了ASR、ESA、FSJ、HFC等策略提升人脸检测性能;
FaceGANs:通过GANs对小尺度、模糊人脸图像生成清晰地超分辨率图像,再结合MB-FCN检测小尺度人脸;
PCN:cascade-style结构,渐进式校准网络来进行旋转不变的人脸检测,PCN包含三个阶段(in a coarse-to-fine manner),每个阶段做三件事:face/non-face分类、人脸bbox回归、人脸偏转角度计算(stage1、2只做离散分类的角度粗估计、stage3做连续回归的角度细估计,对人脸方向校准(stage1、2旋转人脸180°、90°操作等)属于后操作,不在校准网络里面做),使之渐进地校准为一个朝上的人脸;
作者也提到,人脸检测也受到了通目标检测算法的启发,如frcnn、 R-FCN、SSD、FPN、RetinaNet、RefineDet等;
Face RCNN:在frcnn基础上,从人脸识别引入center loss至人脸检测、OHEM、多尺度训练;
Face R-FCN:在R-FCN基础上,引入OHEM、空洞卷积、小尺度的anchor、多尺度的训练与测试策略,并在PSRoI Pooling之后添加了一个PSAverage Pooling;
FaceBoxes:基于SSD、通过anchor密集采样策略,对浅层feature map检测的小尺度目标,其对应anchor做更加密集的anchor采样,使得特征金字塔不同feature map层的anchor有相同的采样密度,在CPU端实时;
FANet:提出特征的层次化聚集网络,在层次特征金字塔上都联合了Hierarchical Loss;FANet确实是独立预测结果的,而且还有feature map间的进阶学习、;
S3FD:基于SSD,使用等比例间隔策略 + 基于尺度补偿的anchor匹配策略、max-in-out label策略检测小尺度人脸;
SSH:通过context module,使用叠层conv的思路,通过增大感受野以达到增加上下文信息目的;
FAN:基于RetinaNet,通过anchor-level的attention机制,突出图像中人脸区域的特征以检出遮挡人脸;
PyramidBox:基于SSD,提出DAS、LFPN、CPM、PyramidAnchors,联合人脸、人头、头肩的上下文信息,辅助人脸检测;
SRN:single-shot人脸检测算法,基于RefineDet,在anchor-based人脸检测器中引入了two-step的cls + reg任务,并引入了RetinaNet中的focal loss;
VIM-FD、Improved SRN:性能小钢炮,各种tricks的融合,可参照专栏里对应的论文;
3 Method
来看看AFD_HP如何一步一步走向sota巅峰的;
3.1 RetinaNet Baseline
介绍了下RetinaNet:
RetinaNet是1-stage的目标检测算法,没有RPN阶段,直接在feature map上做密集的anchor采样(over a regular, dense sampling of possible object locations),速度快;此外,为了解决SSD等1-stage目标检测算法中,训练阶段的正负样本不均衡问题(毕竟RPN还有过滤海量负样本的作用呀,虽然frcnn中RPN通过粗暴的控制正负样本比例为1:3做了负样本过滤),RetinaNet就通过focal loss进一步控制训练阶段的正负样本比例,效果好,如公式(1)、(2):
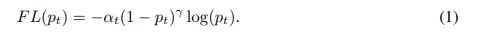
及

y ∈ { +1,-1 }:gt label;
p ∈ [ -1,+1 ]:模型预测的label y = 1情形下样本的概率(model’s estimated probability for the class with label y = 1);
α_t: balanced factor;
γ:可调节的focusing parameter,可参照论文;
focal loss是对传统cross entropy loss的改进,在训练阶段降低了well-classified examples的loss权重,使得模型更专注于学习少量的难分样本,避免模型的训练被海量的易分样本给主导了;
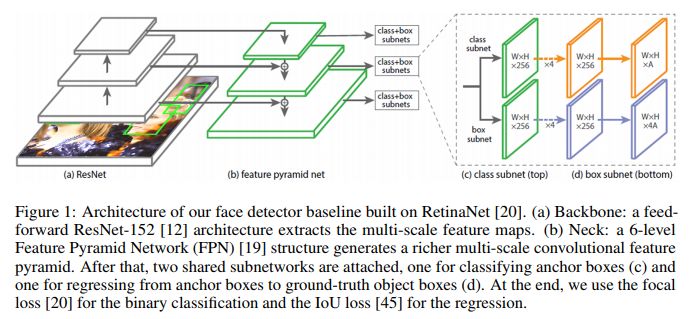
AFD_HP整体结构入fig 1,
(a):ResNet-101主干网提特征,生成multi-scale的feature map;
(b):FPN-style生成多尺度特征金字塔,6层(P2 - P7);
(c):分类子网络,A = 2,结合focal loss;
(d):bbox回归子网络,使用IoU loss;
3.2 IoU Regression Loss
常规的bbox就是smooth L1 loss啦,该目标函数用于最小化pred bbox + gt bbox间的差距,一般使用IoU作为二者的评估标准;不过IoU loss中提到了,smooth L1 loss和IoU二者其实是“貌神合离”的,二者的优化目标并不一致,smooth L1 loss仅仅是为了让pred bbox尽量靠近gt bbox,而并非把二者IoU最大作为目标(there is a gap between optimizing the commonly used smooth L1 distance losses for regressing the parameters of a bbox and maximizing this IoU metric value,可以参照G-IoU、IoU-Net),然后一句话很值得玩味:optimal objective for a metric should be the metric itself,很经典,总结就是:做事的目标和行为应该要保持一致,既然最终评估指标是IoU,那我们就直接优化pred / gt bbox间的IoU,然后就引入了UnitBox中的IoU reg loss,具体可以看看UnitBox论文:
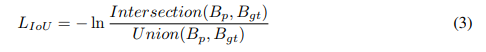
B_p = (x1、y1、x2、y2) : pred bbox;
B_gt = (x*1、y*1、x*2、y*2):gt bbox;
3.3 Selective Refinement Network
SRN中提到,直接使用RetinaNet用于人脸检测,会有两个问题:
1 low recall efficiency:召回率低,为了保持高召回率,检准效果又不佳了;
2 low location accuracy:bbox定位不准,IoU阈值太高的话,mAP急剧下降;
SRN就引入了STC + STR的操作:
STC:在浅层feature map上做2-step cls操作,以过滤海量simple negatives,以减少subsequent classifier的搜索空间;---- subsequent classifier指的是STC中的第二个classifier;
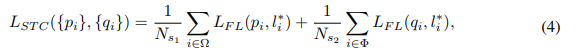
STR:在高层feature map上做2-step reg,对anchor先做一步调整,使得subsequent regressor能获得更好的初始化位置信息;---- subsequent regressorr指的是STR中的第二个regressor;
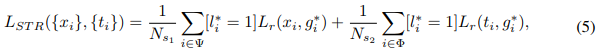
i:anchor index;
pi / qi、xi / ti:1 / 2-step中bbox对应的pred cls、reg结果;
l*i、g*i:cls、reg对应的gt label;
N_s1 / N_s2:1 / 2-step中的positive anchors的数量;
Ω / Ψ:1-step中,参与cls / reg的样本集合;
Φ:2-step中,经过1st-step筛选后,输入2nd-step的anchor集合;
L_FL:sigmoid focal loss;
[l*i = 1]L_r:指示器,表示IoU regression loss仅在positive anchors上操作;
以下引用自Improved SRN:
2.1. Selective Two-step Classification
RefineDet中引入了2-step分类操作,可以理解为基于cascade的2-step分类结构:
1st-step:通过预定义的objectness阈值过滤大部分易分负样本,减少2nd-step分类器所需处理的样本量;---- 使用这个操作的出发点为:anchor-based检测器为检出小尺度人脸,都会在特征金字塔的浅层feature map上做anchor的密集采样,小尺度人脸是保持高召回了,却带来了海量false positives,进一步导致了正负样本数量不均衡;---- 从这点上看,STC就是作用于浅层feature map上的咯;
作者举了个栗子:在1024 x 1024 pix输入的SRN中,如果feature map的每个位置上预定义两个尺度的anchor,最终生成的anchor数量超过300k,但其中正anchor仅有数十个,因此采用2-step的分类操作就很有必要,1st-step先干掉大部分易分负样本,2nd-step再进一步解决剩余的样本;
但作者也提到,没必要在所有检测分支上都使用2-step分类操作,因为P5、P6、P7等高层feature map上anchor的占比比较小(占总anchor数量的11.1%),正负样本数量不均衡的问题会比较轻,且这些层上的特征更利于检测大尺度人脸;但P2、P3、P4等浅层feature map不同,anchor数量特别多(占总anchor数量的88.9%),且特征的表达能力本身又比较弱,context信息也不够,语义信息又缺乏,因此在这些浅层feature map上使用2-step的分类操作,就会有很好的效果;
因此SRN选择在C2、C3、C4(1st-step)、P2、P3、P4(2nd-step)上部署STC;从SRN论文的table 1(a)中也可知,STC提升了正负样本比例,从1/15441提升至1/404,提升了38倍;
此外,SRN在两阶段中都引入了focal loss操作,可以更全面地利用所有样本,且STC中,两阶段的分类器共享了大部分参数(仅预测的分类分支参数不一样),因为二者任务相同:都是从 bg 中判别出前景的人脸区域;最终实验结果如SRN论文中的table 2,可知STC应用于浅层feature map上的性能优于应用于高层feature map上;
STC的loss包含1st-step、2nd-step两部分:
1st-step的损失函数,关注输入1st-step前,生成的所有anchor;2nd-step的损失函数,关注经过1st-step筛选后,输入2nd-step的anchor;最终STC损失函数如下:
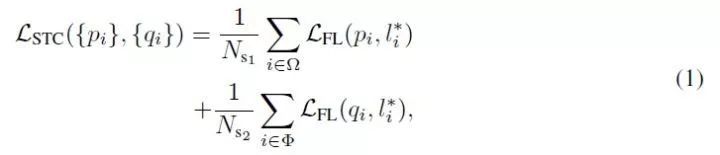
i:mini-batch内的anchor索引;
pi、qi:1st-step、2nd-step两阶段预测anchor i为人脸的置信度得分;
l*i:anchor i对应的gt label;
N_s1、N_s2:1st-step、2nd-step中对应的正anchor数量;
Ω:输入1st-step前生成的anchor集合;
Φ:经过1st-step筛选后,输入2nd-step的anchor集合;
L_FL:基于sigmoid focal loss的二分类损失函数(face vs. bg);
2.2. Selective Two-step Regression
1-stage的目标检测算法一般仅对bbox做一次边框调整,作者认为不够,但cascade rcnn里又说了,盲目地迭代做multi-step的bbox reg,并不能进一步提升bbox的定位精准度,SRN论文中的table 4中证实了,在浅层feature map上操作两次bbox reg,精度竟然还下降了,作者认为原因有二:
1 三个浅层featue map本职工作是通过密集采样的anchor检测小尺度人脸,这些feature map上特征本身的表达能力也不够,因此要其进一步完成bbox回归,精准度就显得不够了;
2 训练阶段,若让浅层feature map也参与其不擅长的bbox回归任务中,有点没发挥其特长,导致模型过于关注其产生的reg loss,忽略了其本职工作的cls loss;
基于以上分析,SRN选择仅在高层P5、P6、P7上使用STR操作,出发点很简单:低层feature map专注于分类任务,高层feature map充分利用大尺度人脸的高语义信息,训练出更适于bbox精准定位的分支;这种divide-and-conquer策略让整个模型的效率非常之高;---- 那么整体上,STC、STR就是RefineDet中ARM、ODM的进一步深入探索,非常有利于小尺度人脸的检测,并过滤海量负样本anchors;
STR的损失函数也包含了两部分:
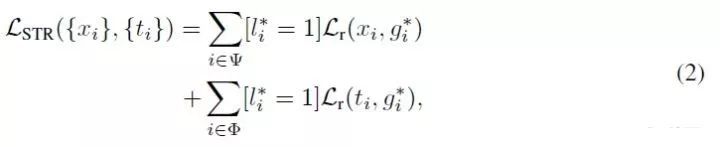
g*i:anchor i 对应的gt bbox;
xi:anchor i 经过1st-step操作,refine后得到的bbox坐标结果;
ti:xi 经过2nd-step操作,refine后得到的bbox坐标结果;
ψ:参数1st-step anchor预测的anchor集合;
l*i、Φ:与STC定义相同,不再赘述;
L_r:Smooth L1 loss,与Fast RCNN一致;
[l*i = 1]:正样本才参与bbox reg loss,负样本直接忽略;
思考:
那么STC、STR的分工是怎么样的?
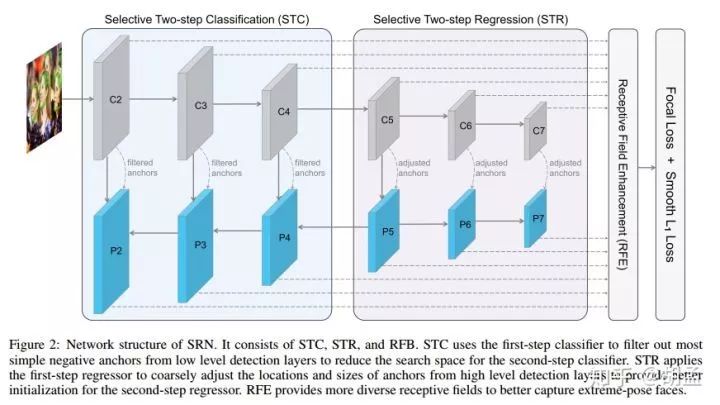
结合fig 2,简单点说就是,fig 2上半部分箭头流程,就是1st-step的操作,流程上和SSD的预测操作是类似的;作者提到了,这种只对bbox做一次调整的1-stage检测算法,性能弱于对bbox做两次调整的2-stage检测算法,因此就联合STC、STR引入了对bbox的第二次调整;---- 这就对应fig 2下半部分箭头流程,就是2nd-step的操作;
但STC、STR将bbox的cls、reg分开做的,STC是对bbox做了第二次分类调整,但STC仅作用于浅层feature map的anchor上,但其主要作用是为了过滤浅层feature map上的海量易分负样本,不是为了将分类结果调整地更精准;同理,STR是对bbox做了第二次定位调整,但STC仅作用于高层feature map的anchor上,其主要作用是为了让高层feature map上的anchor定位更精准;
总结:1st-step操作对应于fig 2上半部分箭头流程,其中包含了对anchor的第一次cls + reg,2nd-step操作对应于fig 2下半部分箭头流程,其中包含了对anchor的第二次cls + reg,但这次的cls + reg不是一把梭哈,而是分开梭的:第二次的cls用STC来梭,且只在浅层feature map上梭、第二次的reg用STR来梭,且只在高层feature map上梭;
如果从anchor的角度来观察,P2、P3、P4上的anchor,其生命周期内,要经历一次bbox reg(1st-step),两次bbox cls(1st-step + 2nd-step,也即STC);P5、P6、P7上的anchor,其生命周期内,要经历一次bbox cls(1st-step),两次bbox reg(1st-step + 2nd-step,也即STR);
3.4 Data Augmentation
在小尺度人脸的检测中,数据增强的作用还是很重要的,50%概率如SSD中常规的原始尺度图像的randomly expand + crop + flip + photometric distortion,剩余50%概率使用PyramidBox中的DAS,来丰富训练样本的尺度:
1 从训练图像中随机选择一个尺度S_face的人脸bbox_x,就是下面的step 1,那么PyramidBox中预定义的anchor尺度分别为:s_i = 2^(4+i),i = 0,1,...,5
2 公式
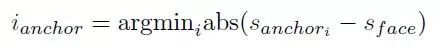
表示与bbox_x最匹配的anchor尺度的索引,就是step 2;
3 从目标缩放尺度集中随机选择一个尺度的索引 i_target:{0,1,...,max(5,i_anchor + 1)},就是step 3;
4 将尺度S_face的人脸bbox_x resize至:S_target = random(Si_target / 2; Si_target * 2) ---- 其实就是step 3中尺度索引对应的anchor尺度,那么得到的目标尺度:s* = S_target / S_face,就是step 3的后半部分;
5 通过对原图img1做scale = s* 的缩放img2(step 4),再从img2随机选择包含人脸的600 x 600子区域图像img3,就得到anchor-sampled训练数据,就是step 5;
举个栗子,一看就懂:
step 1 随机选择一个人脸,假设其尺度为140 pix,预定义anchor尺度为{16、32、64、128、256} pixel;
step 2 找到与之最匹配的预定义anchor尺度,128 pix;
step 3 从{16、32、64、128、256} pixel中随机选择一个目标尺度,如32 pix;
step 4 将包含140 pix人脸的原图img1,做scale = 32 / 140 = 0.2285的resize,得到img2;---- 这里我是拿了32 pixel作为目标缩放尺度的基准,但其实不一定,结合步骤4,可以发现其实是random(Si_target / 2; Si_target * 2)中随机挑选的一个尺度;
step 5 从img2中crop出包含该人脸的640 x 640子图像(上面写的600 x 600,PyramidBox论文中自我矛盾。。。),即为所求的重采样训练图像;
3.5 Max-out Label
max-out label策略起源于ICCV2017_S3FD,作用于S3FD的浅层feature map,以降低为召回小尺度人脸,所做的anchor密集采样造成的海量负样本的误检(reduce the tiny false positives from bg regions, max-out operation for the bg class),pyramidbox更进一步,将max-out ops操作应用于fg + bg上;AFD_HP也在分类子网络中引入了max-out ops,不仅可以召回更多小尺度人脸,也用于减少false positives;具体地,分类子网络为每个anchor输出cp + cn维scores,再选择max{cp}、max{cn}作为正、负人脸的最终score输出,文中设置cp = cn = 3;---- 可能是多增加了一层线性分类器,能提升模型的分类性能吧;
3.6 Multi-scale Testing
multi-scale testing操作的出发点很直观:图像中小尺度人脸很多,单个尺度可能无法cover所有情况;
操作细节可以查阅github上S3FD_caffe、pyramidbox_pytorch代码,讲得蛮清楚的,将多尺度图像依次过模型,得到detected bbox后,再做bbox vote得到最终结果;
4 Experiment
4.1 Experimental Dataset
WIDER FACE:32203张图像,393703个标注人脸bbox,小尺度人脸、遮挡、大尺度表情变化等情况特别多;train / val / test:40% / 10% / 50%的比例,并根据检测难度将 val / test 划分为easy、medium、hard三个子集(基于EdgeBox的检测结果划分的),三个子集逐步包含(后面子集包含前面子集的所有图像),train / val 提供 gt 标签,test未提供;
AFD_HP在train上训练,并在val / test上评估性能;wider face展示如fig 2:

4.2 Anchor Detail
与SRN一致,预定义的anchor,一个长宽比:1:1.25,两个尺度:2S + 2√ 2S(S为对应feature map的下采样尺度),最终feature map上每个位置两个anchor(A = 2),覆盖8 - 362 pixels的人脸(1024 × 1024 pixel图像输入);
正样本:IoU > θp = 0.7 / 0.5;---- 分别对应SRN中的STC / STR;
负样本:IoU < θn = 0.3 / 0.4;---- 不在此区间段的anchor直接忽略;
4.3 Optimization Detail
pytorch实现,主干网ResNet-101在ImageNet上预训练一波,新增conv层xavier初始化,SGD + momentum,流行的lr warmup strategy,可参照pyramidbox_pytorch代码;
4.4 Evaluation Result
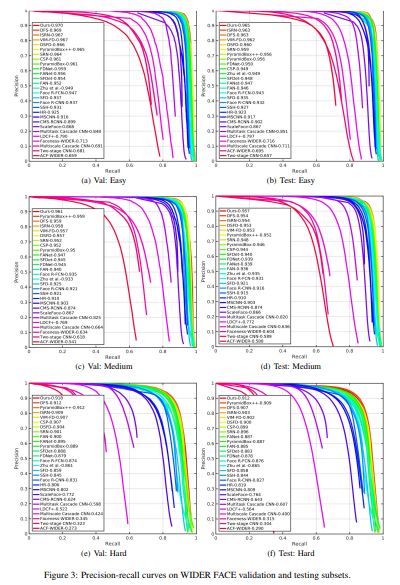
wider face上的结果如fig 3,AFD_HP有点厉害的啦,除了test:hard上稍弱于PyramidBox++,其他的都是sota;
消融实验没做的啦,没能评估各个子模块的贡献率;
5 Conclusion
1 本文提出了人脸检测算法AFD_HP,融合了 1-stage的RetinaNet + IoU loss的bbox reg + SRN的 2-step bbox cls、reg策略 + PyramidBox训练阶段的 DAS 数据增强策略 + S3FD的max-out label + multi-scale inference 等优秀的设计,在wider face上 sota;
论文参考
arxiv2019_AFD_HP_Accurate Face Detection for High Performance
https://arxiv.org/abs/1905.01585
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个看啦~



