学界 | 世界权威评测冠军:百度人脸检测算法PyramidBox
选自arXiv
机器之心编译
近日,百度凭借全新的人脸检测深度学习算法 PyramidBox,在世界最权威的人脸检测公开评测集 WIDER FACE 的「Easy」、「Medium」和「Hard」三项评测子集中均荣膺榜首,刷新业内最好成绩。本文将通过论文简要介绍这一算法背后的技术。
1 引言
人脸检测是各种人脸应用中的一项基本任务。Viola - Jones [1] 的开创性研究利用具有类哈尔特征的 AdaBoost 算法来训练级联的人脸与非人脸分类器。此后不断有人进行深入研究 [ 2,3,4,5,6,7 ] 来改进级联检测器。之后,[ 8,9,10 ] 通过对可变形面部关系的建模,将可变形部件模型 ( DPM ) 引入到人脸检测任务中。这些方法主要是基于设计的特征,这些特征不具有很好的可表示性,而且是通过分离的步骤训练出的。
近年来,卷积神经网络 ( CNN ) 取得了巨大突破,基于 CNN 的现代目标检测技术在人脸检测方面取得了很大进展,包括 R - CNN [ 11、12、13、14]、SSD [15]、YOLO [16]、FocalLoss [17] 及其延伸产物。得益于强大的深度学习方法和端到端的优化,基于 CNN 的人脸检测器性能显著增强,为以后的方法划定了一个新的基线。
当下基于 anchor 的检测框架旨在检测不受控制的环境中的非常规面部,例如 WIDER FACE[ 18 ]。SSH [ 19 ] 和 S3FD [ 20 ] 开发了尺度不变网络,以在单个神经网络中检测来自不同层的尺度各异的人脸。人脸 R - FCN [ 21 ] 利用位置敏感的平均池,对分数图上嵌入的响应进行重新加权,并消除人脸每个部位中非均匀分布的影响。FAN [ 22 ] 提出 anchor 级别的注意机制,通过突出面部区域的特征来检测被遮挡的面部。
虽然这些工作为设计 anchor 和相关网络来检测不同尺度的人脸提供了一种有效的方法,但如何利用语境信息进行人脸检测还没有引起足够的重视,这一问题应该在非常规人脸检测中发挥重要作用。显然,人脸从不单独出现在现实世界中,肩部或身体通常也一起出现,它们提供了可兹利用的丰富的语境关联资源,尤其是在分辨率低、模糊和外部遮挡导致面部纹理不可区分的情况下。针对这一问题,我们提出了一种新的语境辅助网络框架,以充分利用语境信号,具体步骤如下:
首先,网络不仅要能学习人脸特征,还要能学习头部和身体等语境部分的特征。为了实现这一目标,我们需要额外的标签,并设计与之匹配的 anchor。在本任务中,我们使用半监督解决方案来生成与面部相关的语境部分的近似标签,并且发明了一系列名为 PyramidAnchors 的 anchor,以便将其添加到基于 anchor 的一般架构中。
其次,高层次的语境特征应与低层次的语境特征充分结合。常规人脸和非常规人脸的外观可能存在很大差别,这意味着并非所有高级语义特征都有助于识别较小的人脸。我们研究了 Feature Pyramid Networks( FPN ) [ 23 ] 的性能,并将其修改为较低级别的 Feature Pyramid Network( LFPN ),以将对彼此有帮助的特征连接在一起。
第三,预测分支网络应充分利用联合特征。为了将目标人脸周围的语境信息与更广更深的网络相结合,我们引入了语境敏感预测模块 ( CPM )。同时,为了进一步提高分类网络的性能,我们提出了一种可以预测模块的最大输入输出层。
此外,我们还提出了一种名为「数据-anchor-抽样」的训练策略,对训练数据集的分布进行调整。为了学习更具代表性的特征,非常规人脸样本的多样性非常重要,可以通过跨样本的数据扩充来获得。
为表述清晰,本研究可以概括为以下五点:
1. 本文提出了一种基于 anchor 的语境辅助方法,即 PyramidAnchors,从而引入有监督的信息来学习较小的、模糊的和部分遮挡的人脸的语境特征。
2. 我们设计了低层次特征金字塔网络 ( LFPN ) 来更好地融合语境特征和面部特征。同时,该方法可以在单次拍摄中较好地处理不同尺度的人脸。
3. 我们提出了一种语境敏感的预测模型,该模型由混合网络结构和最大输入输出层组成,从融合特征中学习准确的定位和分类;
4. 我们提出了可以感知尺度的数据-anchor-抽样策略,改变训练样本的分布,重点关注较小的人脸。
5. 在通用人脸检测基准 FDDB 和 WIDER FACE 上,我们达到了当前最佳水平。
3 PyramidBox
3.1 网络架构
基于 anchor 的拥有复杂 anchor 设计的目标检测框架已被证明在不同层级的特征图上执行预测时,可以有效地处理可变尺度的人脸。同时,FPN 结构表明将高层级特征和低层级特征融合能带来很大的优势。PyramidBox(图 1)的架构使用了于 S3FD[20] 相同的扩展 VGG16 主干架构和 anchor 尺度设计,可以生成不同层级的特征图和等比例的 anchor。低层级 FPN 被添加到这个主干架构上,并且使用一个语境敏感的预测模块作为每个 Pyramid 检测层的分支网络来获得最终的输出。该方法的关键在于我们设计了一种新型的 Pyramid anchor 方法,它可以在不同层级为每一张人脸生成一系列的 anchor。架构中每个组件的细节如下:
Scale-equitable 的主干网络层。我们使用了 S3FD 中的基础层和额外卷积层作为我们的主干网络层,其中保留了 VGG16 中的 conv 1_1 层到 pool 5 层,然后将 fc 6 层和 fc 7 层转换为 conv fc 层,再添加更多的卷积层使其变得更深。
低层级特征金字塔层。为了提高人脸检测器处理不同尺度的人脸的能力,高分辨率的低层级特征扮演着关键角色。因此,很多当前最佳的研究 [25,20,22,19] 在相同的框架内构建了不同的结构来检测可变尺寸的人脸,其中高层级特征被用于检测尺寸较大的人脸,而低层级特征被用于检测尺寸较小的人脸。为了将高层级特征整合到高分辨率的低层级特征上,FPN[23] 提出了一种自顶向下的架构来利用所有尺度的高层级语义特征图。最近的研究表明,FPN 类型的框架在目标检测和人脸检测上都得到了相当不错的性能。
通过从中间层开始自上而下的结构,我们构建了低层级的特征金字塔网络 (LFPN),其感受野接近于输入尺寸而不是顶层的一半。此外,每个 LFPN 块的结构和 FPN [23] 一样,更多信息详见图 2(a)。
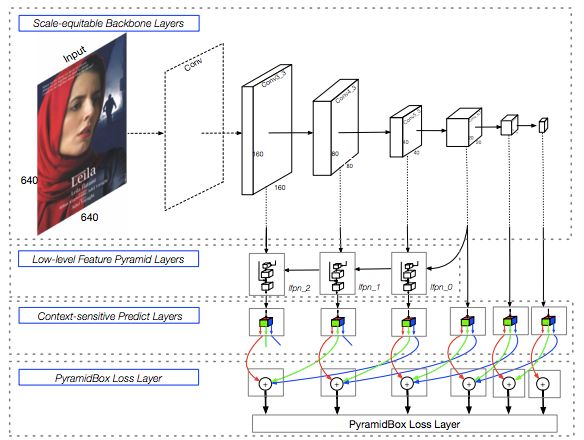
图 1:PyramidBox 架构。它包含 Scale-equitable 主层、低层级特征金字塔层 (LFPN)、语境敏感的预测层和 PyramidBox 损失层。
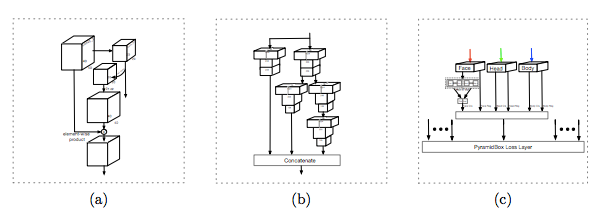
图 2:(a) 特征金字塔网络。(b) 语境敏感的预测模块。(c)PyramidBox 损失。
4 实验
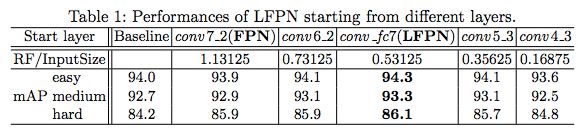
表 1:从不同层开始的 LFPN 的表现。
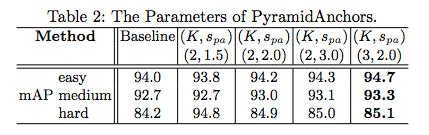
表 2:PyramidAnchors 的参数。
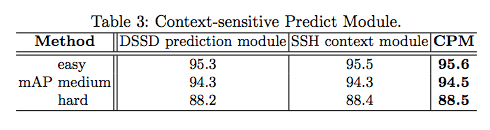
表 3:语境敏感的预测模块。
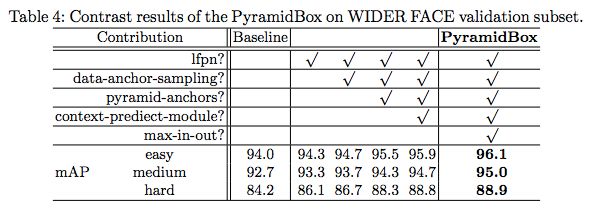
表 4:PyramidBox 在 WIDER FACE 验证子集上的对比结果。
论文:PyramidBox: A Context-assisted Single Shot Face Detector

论文链接:https://arxiv.org/pdf/1803.07737.pdf
人脸检测研究从多年前就已开始,然而,在不受控制的环境中检测小的、模糊的及部分遮挡的人脸仍旧是一个有待解决的难题。针对棘手的人脸检测问题,本文提出了一种语境辅助的单次人脸检测新方法——PyramidBox。考虑到语境的重要性,我们从以下三个方面改进语境信息的利用。首先,我们设计了一种全新的语境 anchor,通过半监督的方法来监督高层级语境特征学习,我们称之为 PyramidAnchors。其次,我们提出了一种低层次级特征金字塔网络,将充分的高层级语境语义特征和低层级面部特征结合在一起,使 PyramidBox 能够一次性预测所有尺寸的人脸。再次,我们引入了语境敏感结构,扩大预测网络的容量,以提高最终的输出准确率。此外,我们还采用「数据-anchor-采样」的方法对不同尺寸的训练样本进行扩充,增加了较小人脸训练数据的多样性。PyramidBox 充分利用了语境的价值,在两个常用人脸检测基准——FDDB 和 WIDER FACE 上表现非凡,取得当前最优水平。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



