通过简单代码理解卷积模块:含Inception/ResNet/DenseNet/NASNet
点击上方“CVer”,选择"星标"和“置顶”
重磅干货,第一时间送达

本文经机器之心(almosthuman2014)
授权转载,禁止二次转载
作者:Paul-Louis Pröve 参与:Panda
比起晦涩复杂的数学或文本描述,也许代码能帮助我们更好地理解各种卷积模块。计算机科学家 Paul-Louis Pröve 用 Keras 对瓶颈模块、Inception 模块、残差模块等进行了介绍和代码说明,并在最后留下了 AmoebaNet Normal Cell 代码实现的练习题。你能够解答吗?不妨在评论区留下答案!
我会尽力定期阅读与机器学习和人工智能相关的论文。这是紧跟最新进展的唯一方法。作为一位计算机科学家,当阅读科研文本或公式的数学概念时,我常常碰壁。我发现直接用平实的代码来理解要容易得多。所以在这篇文章中,我希望带你了解一些精选的用 Keras 实现的最新架构中的重要卷积模块。
如果你在 GitHub 上寻找常用架构的实现,你会找到多得让人吃惊的代码。在实践中,包含足够多的注释并用额外的参数来提升模型的能力是很好的做法,但这也会干扰我们对架构本质的理解。为了简化和缩短代码片段,我将会使用一些别名函数:
def conv(x, f, k=3, s=1, p='same', d=1, a='relu'):
return Conv2D(filters=f, kernel_size=k, strides=s,
padding=p, dilation_rate=d, activation=a)(x)
def dense(x, f, a='relu'):
return Dense(f, activation=a)(x)
def maxpool(x, k=2, s=2, p='same'):
return MaxPooling2D(pool_size=k, strides=s, padding=p)(x)
def avgpool(x, k=2, s=2, p='same'):
return AveragePooling2D(pool_size=k, strides=s, padding=p)(x)
def gavgpool(x):
return GlobalAveragePooling2D()(x)
def sepconv(x, f, k=3, s=1, p='same', d=1, a='relu'):
return SeparableConv2D(filters=f, kernel_size=k, strides=s,
padding=p, dilation_rate=d, activation=a)(x)
我发现,去掉这些模板代码能有好得多的可读性。当然,只有你理解我的单字母缩写时才有效。那就开始吧。
瓶颈模块
一个卷积层的参数数量取决于卷积核(kernel)的大小、输入过滤器的数量以及输出过滤器的数量。你的网络越宽,则 3×3 卷积的成本就会越高。
def bottleneck(x, f=32, r=4):
x = conv(x, f//r, k=1)
x = conv(x, f//r, k=3)
return conv(x, f, k=1)瓶颈模块背后的思想是使用成本较低的 1×1 卷积以特定速率 r 来降低通道的数量,从而使后续的 3×3 卷积的参数更少。最后,我们再使用另一个 1×1 卷积来拓宽网络。
Inception 模块
Inception 模块引入的思想是:并行地使用不同操作然后融合结果。通过这种方式,网络可以学习不同类型的过滤器。
def naive_inception_module(x, f=32):
a = conv(x, f, k=1)
b = conv(x, f, k=3)
c = conv(x, f, k=5)
d = maxpool(x, k=3, s=1)
return concatenate([a, b, c, d])这里我们使用一个最大池化层融合了卷积核大小分别为 1、3、5 的卷积层。这段代码是 Inception 模块的最简单初级的实现。在实践中,还会将其与上述的瓶颈思想结合起来,代码也就会稍微更复杂一些。
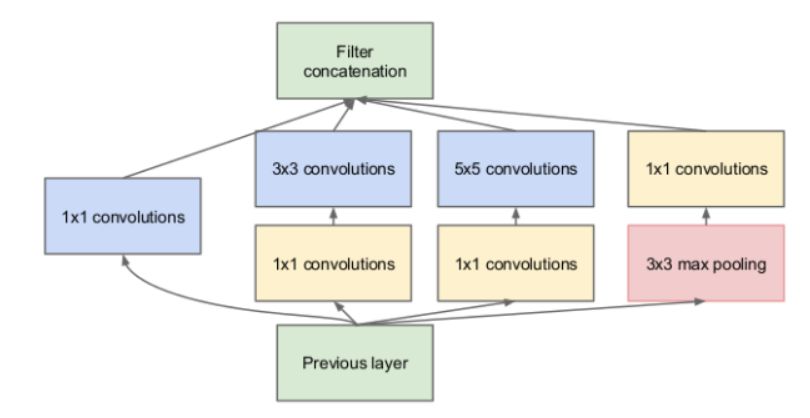
Inception 模块
def inception_module(x, f=32, r=4):
a = conv(x, f, k=1)
b = conv(x, f//3, k=1)
b = conv(b, f, k=3)
c = conv(x, f//r, k=1)
c = conv(c, f, k=5)
d = maxpool(x, k=3, s=1)
d = conv(d, f, k=1)
return concatenate([a, b, c, d])残差模块
ResNet(残差网络)是微软的研究者提出的一种架构,能让神经网络拥有他们想要的任何层数,同时还能提升模型的准确度。现在你可能已经很熟悉这一方法了,但在 ResNet 诞生前情况则很不一样。

def residual_block(x, f=32, r=4):
m = conv(x, f//r, k=1)
m = conv(m, f//r, k=3)
m = conv(m, f, k=1)
return add([x, m])残差模块的思想是在卷积模块的输出上添加初始激活。通过这种方式,网络可以通过学习过程决定为输出使用多少新卷积。注意,Inception 模块是连接输出,而残差模块是添加它们。
ResNeXt 模块
从名字上也看得出,ResNeXt 与 ResNet 紧密相关。研究者为卷积模块引入了基数(cardinality)项,以作为类似于宽度(通道数量)和深度(层数)的又一维度。
基数是指出现在模块中的并行路径的数量。这听起来与 Inception 模块(有 4 个并行的操作)类似。但是,不同于并行地使用不同类型的操作,当基数为 4 时,并行使用的 4 个操作是相同的。
如果它们做的事情一样,为什么还要并行呢?这是个好问题。这个概念也被称为分组卷积(grouped convolution),可追溯到最早的 AlexNet 论文。但是,那时候这种方法主要被用于将训练过程划分到多个 GPU 上,而 ResNeXt 则将它们用于提升参数效率。
def resnext_block(x, f=32, r=2, c=4):
l = []
for i in range(c):
m = conv(x, f//(c*r), k=1)
m = conv(m, f//(c*r), k=3)
m = conv(m, f, k=1)
l.append(m)
m = add(l)
return add([x, m])其思想是将所有输入通道划分为不同的组别。卷积仅在它们指定的通道组内操作,不能跨组进行。研究发现,每个组都会学习到不同类型的特征,同时也能提升权重的效率。
假设有一个瓶颈模块,首先使用 4 的压缩率将 256 的输入通道降低到 64,然后再将它们返回到 256 个通道作为输出。如果我们想引入一个 32 的基数和 2 的压缩率,那么我们就会有并行的 32 个 1×1 卷积层,其中每个卷积层有 4 个输出通道(256 / (32*2))。之后,我们会使用 32 个带有 4 个输出通道的 3×3 卷积层,后面跟着 32 个带有 256 个输出通道的 1×1 层。最后一步涉及到叠加这 32 个并行路径,这能在添加初始输入构建残差连接之前提供一个输出。
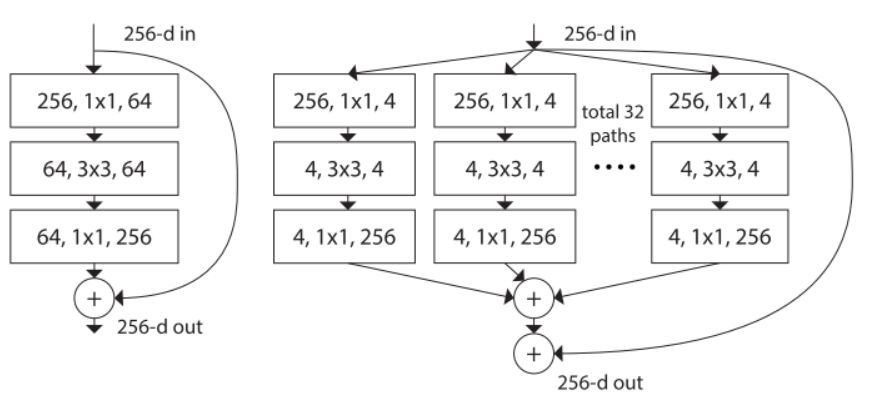
左图:ResNet 模块;右图:有大致一样的参数复杂度的 RexNeXt 模块
这方面有很多知识需要了解。上图是其工作过程的图示,也许你可以复制这段代码,用 Keras 亲自动手构建一个小网络试试看。这么复杂的描述可以总结成如此简单的 9 行代码,是不是很神奇?
随带一提,如果基数等于通道的数量,那就会得到所谓的深度可分离卷积(depthwise separable convolution)。自从 Xception 架构出现后,这种方法得到了很多人的使用。
Dense 模块
密集(dense)模块是残差模块的一个极端版本,其中每个卷积层都会获得该模块中所有之前的卷积层的输出。首先,我们将输入激活添加到一个列表中,之后进入一个在模块的深度上迭代的循环。每个卷积输出也都连接到该列表,这样后续的迭代会得到越来越多的输入特征图。这个方案会继续,直到达到所需的深度。
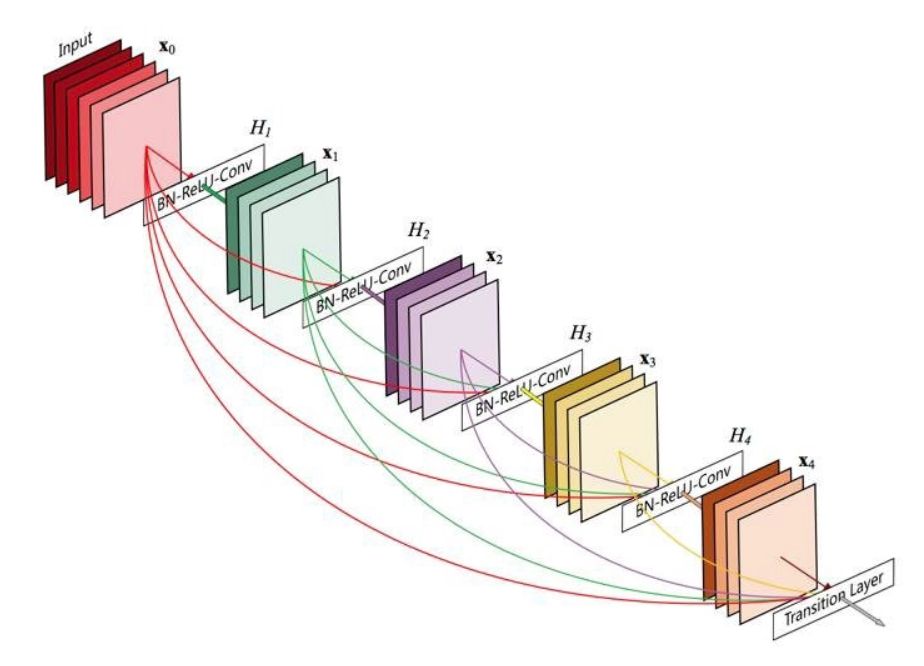
def dense_block(x, f=32, d=5):
l = x
for i in range(d):
x = conv(l, f)
l = concatenate([l, x])
return l
尽管要得到表现像 DenseNet 一样优秀的架构需要耗费几个月的研究时间,但其实际的基本构建模块就这么简单。很神奇吧。
Squeeze-and-Excitation 模块
SENet 曾短暂地在 ImageNet 上达到过最佳表现。它基于 ResNeXt,并且重在建模网络的通道方面的信息。在一个常规的卷积层中,每个通道的点积计算内的叠加操作都有同等的权重。
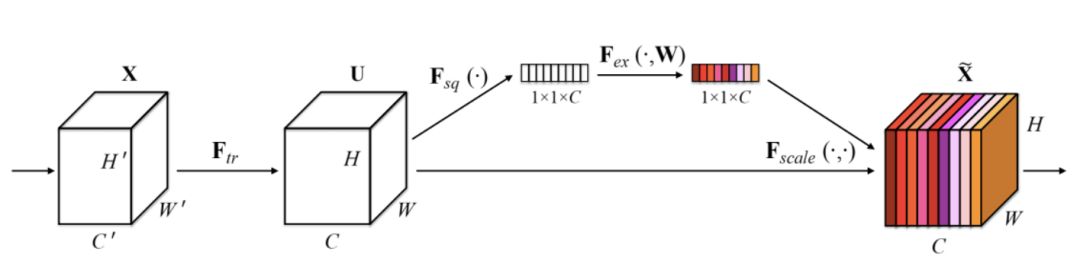
Squeeze-and-Excitation 模块
SENet 引入了一种非常简单的模块,可以添加到任何已有的架构中。它会创建一个小型神经网络,该网络能学习如何根据输入情况为每个过滤器加权。可以看到,它本身并不是卷积模块,但可以添加到任何卷积模块上并有望提升其性能。我想将其添加到混合模块中。
def se_block(x, f, rate=16):
m = gavgpool(x)
m = dense(m, f // rate)
m = dense(m, f, a='sigmoid')
return multiply([x, m])
每个通道都被压缩成单个值,并被馈送给一个两层神经网络。根据通道的分布情况,该网络会学习基于它们的重要性为这些通道加权。最后,这些权重会与卷积激活相乘。
SENet 会有少量额外的计算开销,但有改善任何卷积模型的潜力。在我看来,这种模块得到的研究关注还不够多。
NASNet Normal Cell
难点来了。之前介绍的都是一些简单但有效的设计,现在我们进入设计神经网络架构的算法世界。NASNet 的设计方式让人称奇,但实际的架构却又相对复杂。但我们知道,它在 ImageNet 上的表现真的非常好。
NASNet 的提出者通过人工方式定义了一个包含不同类型的卷积和池化层的搜索空间,其中包含不同的可能设置。他们还定义了这些层可以并行或顺序排布的方式以及添加或连接的方式。定义完成之后,他们基于一个循环神经网络构建了一个强化学习(RL)算法,其奖励是提出了在 CIFAR-10 数据集上表现优良的特定设计。

所得到的架构不仅在 CIFAR-10 上表现优良,而且还在 ImageNet 上取得了当前最佳。NASNet 由 Normal Cell 和 Reduction Cell 构成,它们在彼此之后重复。
def normal_cell(x1, x2, f=32):
a1 = sepconv(x1, f, k=3)
a2 = sepconv(x1, f, k=5)
a = add([a1, a2])
b1 = avgpool(x1, k=3, s=1)
b2 = avgpool(x1, k=3, s=1)
b = add([b1, b2])
c2 = avgpool(x2, k=3, s=1)
c = add([x1, c2])
d1 = sepconv(x2, f, k=5)
d2 = sepconv(x1, f, k=3)
d = add([d1, d2])
e2 = sepconv(x2, f, k=3)
e = add([x2, e2])
return concatenate([a, b, c, d, e])
你可以这样用 Keras 实现 Normal Cell。其中没什么新东西,但这种特定的层的组合方式和设定效果就是很好。
倒置残差模块
现在你已经了解了瓶颈模块和可分离卷积。让我们将它们放到一起吧。如果进行一些测试,你会发现:由于可分离卷积已能降低参数数量,所以压缩它们可能有损性能,而不会提升性能。

研究者想出了一个做法,做瓶颈残差模块相反的事。他们增多了使用低成本 1×1 卷积的通道的数量,因为后续的可分离卷积层能够极大降低参数数量。它会在关闭这些通道之后再添加到初始激活。
def inv_residual_block(x, f=32, r=4):
m = conv(x, f*r, k=1)
m = sepconv(m, f, a='linear')
return add([m, x])
最后还有一点:这个可分离卷积之后没有激活函数。相反,它是直接被加到了输入上。研究表明,在纳入某个架构之后,这一模块是非常有效的。
AmoebaNet Normal Cell

AmoebaNet 的 Normal Cell
AmoebaNet 是当前在 ImageNet 上表现最好的,甚至在广义的图像识别任务上可能也最好。类似于 NASNet,它是由一个算法使用前述的同样的搜索空间设计的。唯一的区别是他们没使用强化学习算法,而是采用了一种常被称为「进化(Evolution)」的通用算法。该算法工作方式的细节超出了本文范围。最终,相比于 NASNet,研究者通过进化算法用更少的计算成本找到了一种更好的方案。它在 ImageNet 上达到了 97.87% 的 Top-5 准确度——单个架构所达到的新高度。
看看其代码,该模块没有添加任何你还没看过的新东西。你可以试试看根据上面的图片实现这种新的 Normal Cell,从而测试一下自己究竟掌握了没有。
总结
希望这篇文章能帮助你理解重要的卷积模块,并帮助你认识到实现它们并没有想象中那么困难。有关这些架构的细节请参考它们各自所属的论文。你会认识到,一旦你理解了一篇论文的核心思想,理解其它部分就会容易得多。请注意,在实际的实现中往往还会添加批归一化,而且激活函数的应用位置也各有不同。

原文链接:https://towardsdatascience.com/history-of-convolutional-blocks-in-simple-code-96a7ddceac0c
想要了解最新最快最好的计算机视觉论文速递、开源项目和干货资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。

扫码进群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!