


【深度学习基础】3. Convolutional Neural Network
如今深度学习如火如荼,各种工具和平台都已经非常完善。各大训练平台比如 TensorFlow 让我们可以更多的聚焦在网络定义部分,而不需要纠结求导和 Layer 的内部组成。本系列我们来回顾一下深度学习的各个基础环节,包括线性回归,BP 算法的推导,卷积核和 Pooling,循环神经网络,LSTM 的 Memory Block 组成等,全文五篇,前三篇是斯坦福深度学习 wiki 整理,第四第五两篇是 Alex Graves 的论文读书笔记,图片来自网络和论文,有版权问题请联系我们。

通过之前的文章,一种构建神经网络的方案是将输入层到隐藏层每个节点都设置一个参数权重,构建一个“全连接”的网络。但是这种设计有个问题,在输入层节点,比如 28*28 的小图片上还可行,但是如果图片变大到 96*96 ,那么输入层节点数量接近 1 万了,如果你再制作 100 组 feature ,那么从输入层到隐藏层需要训练的参数是 100 万个,计算量随着输入层大小急剧变大。
当然也可以用“局部连接”的概念来减少需要训练的参数。比如在输入层节点上设置一个滑动窗口,隐藏层只跟窗口内部的少数输入层节点有连接边。比如语音就可以在输入层上面加时间窗来构建“局部连接”网络。
对于图片数据,有个特性就是整个图片不同区域在统计特性上是一致的,针对一个区域设计的特征提取机制,放到其他区域也是可以用的。举个例子:从一个大图上面截取一个 8*8 的小区域,针对这一块数据设计了一系列特征提取算法(也就是 8*8 区域的参数),理论上这个特征提取算法是可以应用在这个大图片上的任何区域的。然后把这个滑动窗口从大图片的左上角到右下角整个的过一遍,每一处都执行卷积操作(矩阵按位乘并全局求和),把原始图片转换到一个新的特征空间。
下面的图片是一个例子,对于一个 5*5 的图像使用一个 3*3 的小窗口进行卷积。需要注意的是:黄色区域内的参数是通过训练过程中学出来的,不是手工编的。然后如果一共开发了比如 N 组这样的小窗口( N 组特征提取器,大小各异),通过卷积操作后,会得到 N 组的卷积特征结果集。
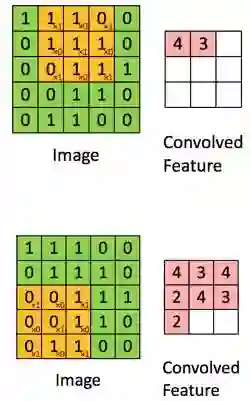
上面的例子泛化一点,假设图片大小是 r*c ,卷积窗口是 a*b 覆盖一个 
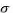
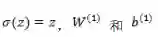
泛化一点,如果我们不认为这是一个图像,而只是一个数据的矩阵,那么数据来源就可以不限定为图像像素了。比如词向量( word2vec )或者各种具有局部 context 关系的 embedding 数据,都应该是可以用卷积层来操作的。比如短文本句子,卷积窗口的宽度等于词向量的维度( 因为词向量被截断后意义不大 ),高度等于窗口要覆盖的上下文词数量( 比如5个词 ),那么卷积操作是可以处理文本数据上下文关系的。窗口在短文本句子上滑动,就是在处理一个个的局部语义片段。
通过上面的卷积操作,理论上已经提取到了很多特征可以直接训练分类器了。但是由于简单算一下,如果对 96*96 的图片通过 8*8 的窗口进行卷积并得到了 400 组特征,那么最后产生的卷积特征是 400*(96-8+1)*(96-8+1)=300 万维。
直接对 300 万维特征进行训练,不但训练计算量非常大,而且很容易过拟合。
回到之前提到的图像不同区域之间的统计特性一致性,那么理论上对一个图像的不同区域再做一次相同的统计汇总,得到的特性应该仍然是一致的。比如对不同区域分块后求平均,或者求最大值。通过这种对不同区域进行统计汇总,可以显著降低特征数据的维度,因此也可以改善过拟合问题。这个过程叫做“池化”,或者 “mean pooling” , “max pooling” 。下图是一个池化过程的示意图:
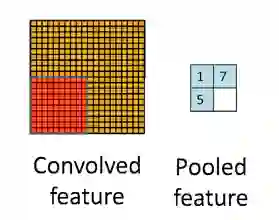
选择m*n大小的窗口进行卷积特征的池化,那么直接把卷积特征划分到不连续的m*n分块,直接在分块上进行求平均或者最大值的操作,就可以完成池化的过程了。需要注意的是,不同的卷积特征(特征提取器输出的结果)需要独立的进行池化,池化之后的数据才进入全连接的操作输入到下一层。
根据上面的 pooling 的内容讲解,如果我们是在相同的 filter 所产生的特征中进行相邻连续区域的 pooling ,那么所得到的 pooling 结果具有平移不变性。举个简单的例子:用 max pooling 对一个卷积层结果进行池化,那么原始的图像进行了小范围的移动,实际上得到的 pooling 层结果应该是一样的。这种平移不变性在图像处理的时候非常有用,比如手写体识别,label 是一样的,但是如果图像稍微平移了一点,识别程序应该足够 robust ,仍然能识别它。
在最优化方法中,有一类方法是全局求最优的梯度方向,比如 L-BFGS(limited memory BFGS),但是这类方案在数据量和模型都大到不能装进内存的时候,单机无法完成。而且这类方法是对整体训练数据进行最优化求解,因此无法对新的数据进行训练,也就是 online-learning 。随机梯度下降(StochasticGradient Descent,SGD)可以解决此类问题。
SGD 用在神经网络的训练上,不但可以避免计算全量数据的 BP 运算复杂度,而且仍然可以快速收敛。
SGD 的公式之前在线性回归的时候已经介绍过了: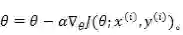
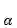
SGD 一个需要注意的问题是训练数据应该在每轮迭代的时候进行随机打乱,如果训练数据是按照某种规则进行排列的,一般训练过程的收敛性也无法保障。
SGD 训练过程中另外一个需要注意的问题是如果目标函数在最优解附近有抖动,而且具有局部很陡的峰值,那么常规 SGD 会在局部峰值的位置震荡。很不幸 DNN 就具有这样的特点。一个解决办法是在梯度更新的时候增加动量:
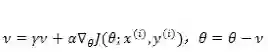
上式中 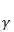
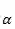
卷积神经网络(CNN)
了解了卷积和池化的概念后,我们可以定义卷积神经网络:通过一个或者多个卷积层,同时配合池化操作,然后将结果通过全连接隐藏层构建的多层神经网络。
卷积神经网络的好处是通过局部连接和池化可以对二维的图像进行空间建模,同时显著减少网络参数。
关于 CNN 的实现细节描述如下:
假设一个图片宽和高都是 m ,有 r 个通道(比如 RGB 就是 3 通道),那么输入层(图片像素)到卷积层的输入维度是 m*m*r (为了方便起见我们可以先不管 r ,可以理解为把一个通道的卷积做 r 次)。然后我们定义一个 n*n 大小的卷积窗口,制作 k 个卷积核,这样可以将图像转化到 k 组 m-n+1 长宽的矩形区域 
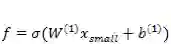
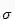
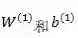
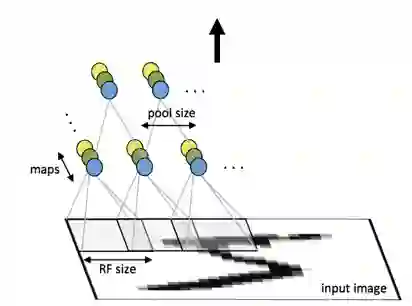
下图是一个 CNN 的示意图,不同颜色的节点代表不同的 channel 和 feature 。
卷积神经网络的BP算法求解
假设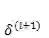
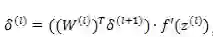
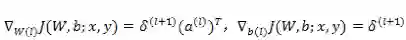
如果第 l 层是卷积和池化层,此时的误差传递要稍微变更一下:
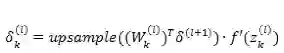
式中 k 是卷积核(filter)的下标,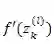
最后是计算 filter 的梯度更新。Filter 权值的梯度通过对误差项矩阵和图片数据进行卷积来计算,然后把所有结果累计求和,就是卷积函数的梯度更新项。对于 bias 的梯度更新更简单,filter 误差项直接求和就是对应的 bias 更新。梯度公式如下所示:
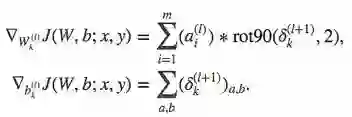
看上面的公式,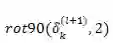
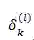
这部分的具体代码,可以看 caffe 或者 mxnet 的源代码来理解,斯坦福的 deep learning 教程上有 matlab 代码。
需要注意的是:如果在计算最后的代价函数的时候,考虑了对训练数据样例大小做平均的话,在进行梯度反馈的时候,也需要进行求平均操作。
卷积核的编程实现
通过上面的讲解,我们知道卷积过程其实是对图像(泛化一点理解,应该是一个矩阵,不限里面的数据是什么类型)中的某一块单独提取出来进行一个特定的计算把他映射到另外一个矩阵,或者使用数字信号处理的概念,我们是对这一小块矩阵进行了一个滤波操作留下我们想要的内容。这也是为什么有些地方把这个过程叫做 filter 。
那么理论上不同的卷积操作应该是预先定义了很多不同的卷积核或者滤波器,通过在原始矩阵上面滑动进行局部滤波,得到新的矩阵数据。但是我们在一些深度学习编程框架,比如 MXNet 上只看到需要配置 filter 的数量,并没有说可以指定使用何种方式的滤波操作。这是怎么回事呢?
这一块的内部实现是这样的:如果我指定当前是一个卷积层,并把 filter 设置为 20 ,实际上窗口大小和卷积函数的操作是一模一样的,只不过卷积函数的参数(W和b)的初始化值不一样。因为卷积和池化之后的全连接层,每次做 BP 计算的时候得到的传递回来的误差是一个全局误差,并不会因为 filter 不同而由不同,所以各个初始化不一样的filter在使用一个相同的全局梯度值进行更新,可以保证其最后训练得到的模型中filter的最终权重也是不一样的。
上面这一点可以借助 word2vec 的 CBOW 模型加强理解,CBOW 的投影层得到的梯度值是一个全局的,把他更新到 context 窗口上各个 word ,得到的效果也是不一样的。

 微信ID:WeChatAI
微信ID:WeChatAI
 长按左侧二维码关注
长按左侧二维码关注
登录查看更多
相关内容

专知会员服务
14+阅读 · 2020年1月1日
Arxiv
4+阅读 · 2018年12月28日

相关VIP内容
专知会员服务
14+阅读 · 2020年1月1日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年12月28日