赛尔原创@ACL 2021 | BERT也能做生成?利用多个BERT模型分离对话生成和对话理解
论文名称:BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data 论文作者:宋皓宇,王琰,张开颜,张伟男,刘挺 原创作者:宋皓宇 论文链接:https://aclanthology.org/2021.acl-long.14/ 代码链接:https://github.com/songhaoyu/BoB 转载须标注出处:哈工大SCIR
1. 摘要
开放域对话系统需要在对话过程中尽可能地保持一致的人物角色特征。尽管在最近几年基于角色的对话生成已经取得了巨大的进步,但是在应用上这些方法仍然受限于人物角色对话数据的有限规模。在这项工作中,为了解决数据资源不足带来的挑战,我们提出了全新的BERT-over-BERT(BoB)模型将基于角色的对话生成分解为了两个子任务。具体来说,该模型由一个基于BERT的编码器和两个基于BERT的解码器组成,其中一个解码器用于对话回复生成,另一个则用于角色一致性的理解。特别地,我们利用大规模的无标注文本和非对话推理数据训练模型以缓解数据资源不足带来的影响。我们在中英文两个角色化的对话数据集上进行了实验。在不同的低数据资源场景下,客观指标和人工评价的结果均表明我们的模型在回复质量和人物角色一致性方面显著优于强基线模型。
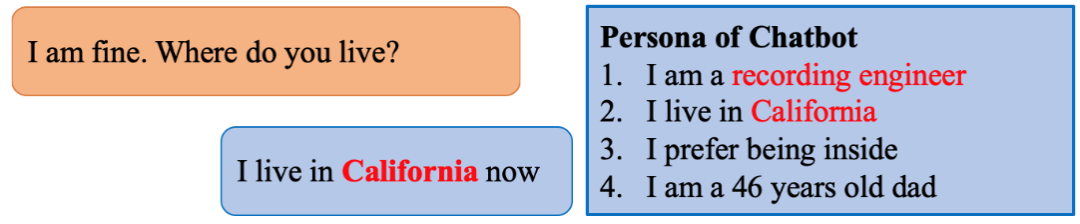
图1 引入角色信息的开放域对话
2. 背景
开放域对话系统旨在根据对话历史给出合适的对话回复。在现阶段下,无论是开放域对话生成模型还是开放域对话系统,面临的最大挑战之一就是对话回复的前后不一致。相比于其他类型的缺点,比如缺乏常识、不具备感情等,用户对不一致现象的容忍度往往更低:说话过程中极少量的前后不一致就很容易导致用户脱离当前的对话语境,失去进一步对话的兴趣。当对话系统之前回答过自己是一名工程师后,如果在后续对话中又继续说自己还在初中上学,就会让用户感到十分困惑。这就是不一致现象。已有的研究工作表明,仅靠大规模的对话数据很难根除这类不一致的现象[1,2]。
针对这一问题,相关的研究工作开始在对话中明确地引入角色信息[3,4]。图1所示的就是这样一个例子。角色信息的引入极大地简化了对话过程一致性的建模,也使得评价过程更容易。然而,这些工作都依赖于带有角色信息的对话数据。通常来说,这类数据有两种获取形式:一是通过人工标注(通常是众包)的方式,来获取基于预设角色信息的人人对话数据[3]。这种方式获得的数据质量很高,并且对话中角色信息稠密(persona dense),但是标注成本高昂,难以获得大规模的数据。二是从社交媒体(比如微博和Twitter)上收集用户的帖子和评论,并将公开的用户信息作为相应的角色信息[4]。这种方式的优点是能够以较低的成本收集到大量的数据;但缺点也很明显,那就是对话数据中角色信息高度稀疏(persona sparse),因为绝大多数用户都不会经常性地公开讨论自己信息。这两种构建角色化对话数据资源的方式带来了共同的资源稀缺问题:角色信息丰富则数据量少;而数据量充足则角色信息稀疏。
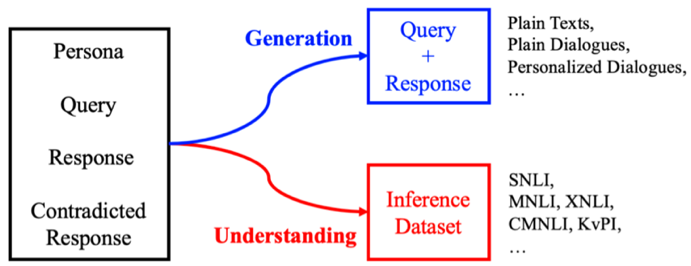
图2 分离角色化对话所需要的数据资源
在重新思考了角色化对话生成任务的关键点,我们发现此类模型需要具备两种能力:首先需要能够理解对话回复和角色信息的一致性关系,比如理解“我在北京”和“我想去北京”的区别;然后需要能够生成带有角色信息的回复。传统的方法往往都试图直接从角色稠密的数据集学到上述两种能力。然而,有限的数据资源使得模型难以真正同时学到两种能力,尤其是第一种理解能力。
为了缓解这一问题,我们设计了一个全新的基于BERT的模型,包含了一个BERT编码器和两个BERT解码器,将理解能力和生成能力的获取分离开来。一旦我们将二者拆分开,无论是一致性理解还是对话生成,我们都能够找到充足的数据资源来进行训练。如图2所示,对于一致性理解,我们可以使用大规模的文本蕴含数据集,比如MNLI和SNLI;对于对话生成,我们已经有足够多的大规模对话语料了。
3. BoB模型
受上述动机的启发,在这项工作中,我们探索在大规模非对话推理数据的帮助下,从有限的角色化对话中学习基于人物角色的对话模型。具体而言,该模型由编码器E、用于响应对话回复的自回归解码器 和用于一致性理解的双向解码器 组成。给定角色信息 和对话输入 ,E和 共同以经典的编码器-解码器模式中工作,以学习典型从输入到回复的映射 ,并生成初步的对话回复表示 。然后 和人物角色 被馈送到双向解码器 以将 映射到最终响应表示 。由于学习一致性理解的部分 独立于对话输入 ,因此该部分可以在非对话推理数据集上学习。在这里,我们参考前人的工作[2],在 引入了Unlikelihood目标函数,用于减少推理数据中矛盾数据出现的可能性,使得 能够获得一致性理解的能力。我们使用预训练的BERT模型来初始化所有模块,并将该模型命名为BERT-over-BERT (BoB)。BoB模型的整体结构及相应的训练方式如图3所示:
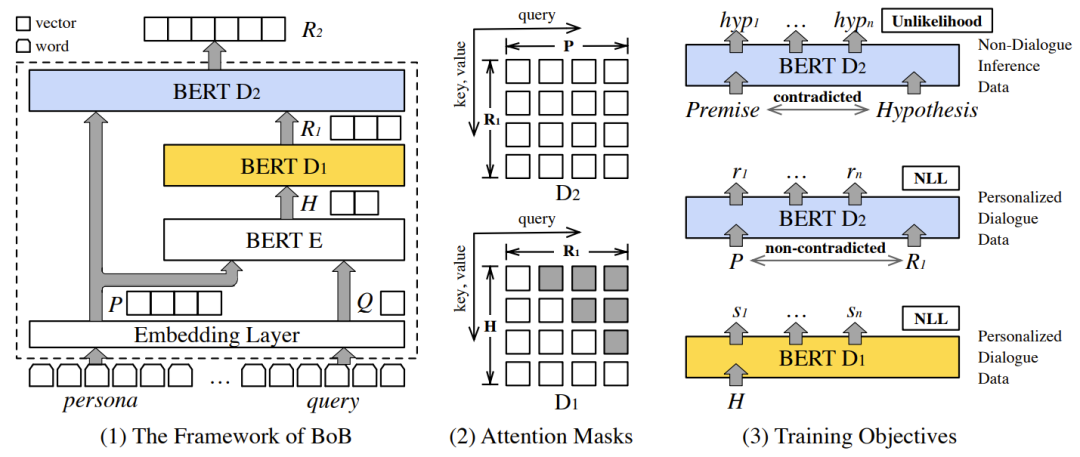
图3 BoB模型框架及训练目标
编码器E 该模块的工作原理类似于标准的BERT模型,该模型将输入文本双向编码为隐藏向量,以便于后续模块使用。在我们的模型中,输入文本包括角色信息 和对话输入 。对于角色信息,无论 是以文本形式(例如,“我养了两只猫”)还是以属性键值对(例如,“地点:西雅图”)给出的,我们都可以将其转换为一串单词序列。为了让模型能够区分角色信息和对话输入,我们在角色信息序列和对话输入之间放置一个特殊标记,输入格式如下:
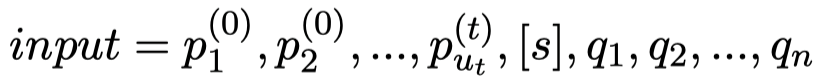
输入信息首先经过所有模块共享的Embedding层转化为词向量,然后再由编码器E经过多层双向自注意力机制编码为向量表示 。由于这里E的工作方式和原始的BERT完全一致,此处不再介绍细节。
自回归解码器 得益于预训练BERT的初始化,该模块继承了一个健壮的语言模型。不一样的地方在于,这里的 以自回归解码器的方式工作。在BERT预测某一个掩码词时,它会利用这个词语左右双向的信息;但是在自回归的生成任务中,词语是自左向右逐个预测的。为了消除这种不一致,受到UniLM的启发,我们在训练和预测过程中对 使用了图3中所示的上三角的掩码矩阵,以确保生成的回复词只能依赖已有的信息。此外,类似于经典的序列到序列模型,在解码器和编码器之间添加注意力机制能够有效地提升效果。我们也在E和 之间添加了交叉注意力机制(cross attention)。不同于自注意力机制中query、key和value完全相同,交叉注意力机制的query来自 的前一层信息,key和value来自 ,即:
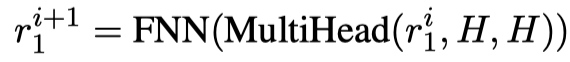
E和 都有N个相同的层。 最后一层的输出 会进一步送到 中进行一致性理解处理。
双向解码器 与E和 一样, 也是从预训练BERT进行初始化的,并由此继承了文本理解任务的良好语义表示。不同于自回归的生成任务,对于包括一致性理解在内的文本理解任务而言,模型都需要利用双向信息才能更好地进行学习。因此,虽然同样是解码器,如图3所示, 的输入信息上没有添加上三角的掩码矩阵。 的任务是学习如何理解一致性关系,并将这种能力应用于回复生成任务。为了达到这一目的, 同时通过标准的用于生成的交叉熵损失和用于一致性理解的Unlikelihood损失进行训练。 的交叉熵损失计算类似 ,不同之处在于 的输入是角色信息和 ,而非对话输入 ;输出仍然是对话回复。这一特点使得 的工作方式更加类似于降噪自编码器,而非经典的序列到序列模型中的解码器。另一方面,在进行一致性理解训练时, 的输入是文本蕴含数据集中的前提和假设,输出,也就是生成,的目标同样是文本蕴含数据中的假设。设置这种方式的目的在于模拟对话数据的生成方式,从而让模型能够利用非对话的文本蕴含数据进行一致性理解训练。因此, 是BoB模型分离理解任务和生成任务的关键。 同样有N层,对于每一层:
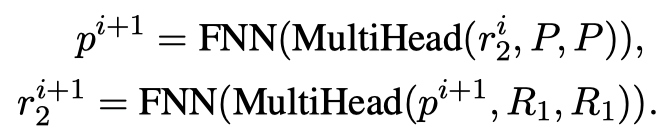
从上式可以看出,各层中产生的 融合了来自 和 的信息。 最后一层的输出是最终表示 。在 上接一个线性输出层,我们可以得到生成的最终对话回复 。
4. 实验结果
我们同时在角色信息稠密的PersonaChat数据集(英文,众包,12万数据量)和角色信息稀疏的PersonalDialog数据集(中文,社交媒体,1200万数据量)上通过大量的实验来验证了BoB模型的有效性。在评价指标方面,我们同时使用了人工评价和客观指标,来比较不同模型的角色一致性和回复质量。为了更客观地评价不同模型的角色一致性,我们引入了基于不同类别(一致和矛盾)对话回复的语言模型困惑度指标和基于分类器的一致性得分指标来进行比较。基线模型中既包括了最新的非预训练模型,也同时包括了强有力的生成式预训练模型。另一方面,我们还通过减半训练数据的方式来评估了我们的方法在资源更受限的情况下的性能。我们把实验结果放到了本文的末尾。相关实验结果证明了BoB模型在保持良好的回复质量的同时,仍然在角色一致性上优于所有基线模型。此外,在训练数据稀缺的情况下,BoB模型仍然有效:得益于分离理解和生成的设计,BoB模型甚至在只使用1/8角色化训练数据的情况下,就能在大多数指标上超过使用全量数据的强基线模型。更多的实验分析请参阅论文。
表1 PersonaChat数据集全量数据实验结果。
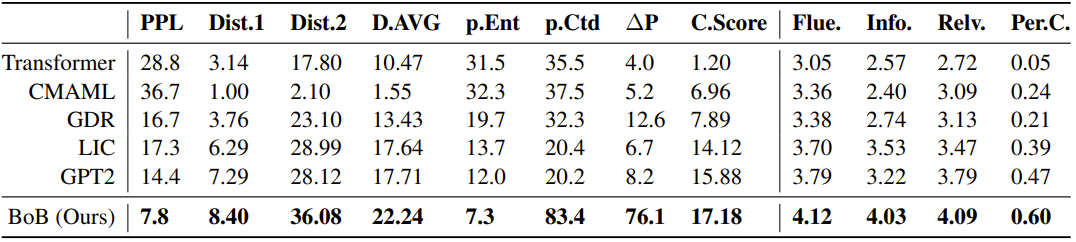
表1是PersonaChat数据集全量数据实验结果。PPL衡量了模型拟合数据的能力,Distinct-1,Distinct-2和Distinct Average衡量了对话回复用词的多样性。p.Ent和p.Ctd分别是不同模型在一致和矛盾的对话数据上的困惑度:一致的困惑度越低越好,矛盾的困惑度越高越好;ΔP则是二者的差值。C.Score是基于RoBERTa模型的一致性自动评分指标,越高越好。
表2 PersonaChat数据集低资源实验结果。

表2是PersonaChat数据集低资源实验结果。1/2,1/4,1/8分别表示训练所用的PersaonChat训练集数据量。†表示我们的方法超过基线模型最好效果所需要的最少数据量。
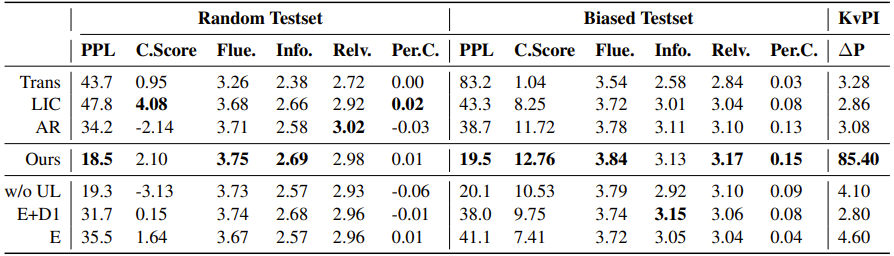
表3是角色信息稀疏的PersonalDialog数据集主实验结果及消融实验结果。该数据集有两个不同的测试集:Random Testset随机取样自训练集同分布的数据,角色信息同样稀疏;Biased Testset则通过人工筛选,更倾向于表达角色信息。两个测试集分别测试了模型在常规对话场景下和角色化对话场景下的效果。我们的方法在角色稀疏的数据上进行训练,虽然常规对话场景下没有绝对的优势,但是在角色化的测试数据上仍然表现出了优秀的性能。
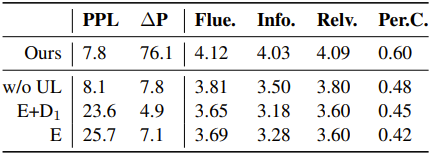
表4是PersonaChat数据集消融实验结果。可以看到,Unlikelihood训练目标对于一致性理解最为重要;而第二个解码器则对于多样性和困惑度贡献最大;基础的BERT编码器也有不错的性能表现,为我们的BoB模型提供了良好的初始化。
5. 结论
在这项工作中,我们提出了一种全新的基于BERT的角色化对话模型,通过分离回复生成和一致性理解,从有限的角色化对话数据中进行学习。此外,我们在训练过程中引入了基于非对话推理数据的Unlikelihood训练,提高了模型的一致性理解能力。在两个公开数据集上的实验表明,我们的模型可以使用更少的角色化对话数据训练,同时获得比使用全量数据训练的强基线方法更好的效果。
参考文献
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴

