赛尔原创@ACL 2021 | 基于分离隐变量的风格化对话生成
论文名称:Neural Stylistic Response Generation with Disentangled Latent Variables 论文作者:朱庆福,张伟男,刘挺,William Yang Wang 原创作者:朱庆福 论文链接:https://aclanthology.org/2021.acl-long.339.pdf 转载须标注出处:哈工大SCIR
1. 引言
语言风格是自然语言的重要属性,在对话生成中考虑回复的风格,有利于增强对话的整体风格一致性、进而实现对话系统的拟人化。实现风格化对话生成最直接的方法是,在大规模风格对话数据上训练模型。然而,一方面,现有对话数据大多收集自不同性别、年龄的用户,数据来源较为庞杂、不具有统一的期望风格;另一方面,现有(期望)风格数据大多以自由文本的形式存在,例如小说、剧本等,不具有可用于对话生成训练的平行形式。总的来说,平行(对话)数据无风格、风格数据非平行,因此,已有对话生成模型很难直接应用到风格化对话生成任务上。
2. 相关工作
为解决上述问题,一些文献开始研究如何同时使用非平行风格数据为平行对话数据上训练得到的模型注入风格。Niu和Bansal [1]使用风格数据训练了一个语言模型,通过考虑回复在该语言模型下的生成概率来注入风格。然而由于该语言模型忽略了对话历史,因此会影响回复与对话历史的相关性。Gao等人[2]提出了一种结构化的隐变量空间,对话历史和其回复在训练时均被映射为空间内的点,且回复分布在以对话历史为球心的超球面上。由此,在预测阶段便可通过在对话历史周围随机采样来获得不同的回复。在此基础上,进一步将风格数据通过K近邻损失对齐到空间中,便可增强生成回复的风格强度[3]。图1展示了结构化隐变量空间的示意图,其中, 为话历史 在隐变量空间中的表示, 为第 个回复 的表示, 为风格句子表示:

图1 结构化隐变量空间示意图
该方法通过隐变量空间的对齐,有效缓解了回复相关性较差的问题,但同时也限制了回复风格强度。图2从回复内容相关性和风格强度两个维度展示了已有方法的现状:内容相关性和风格强度之间存在着较为明显的trade-off关系,一个维度的提升会带来另一维度的降低。
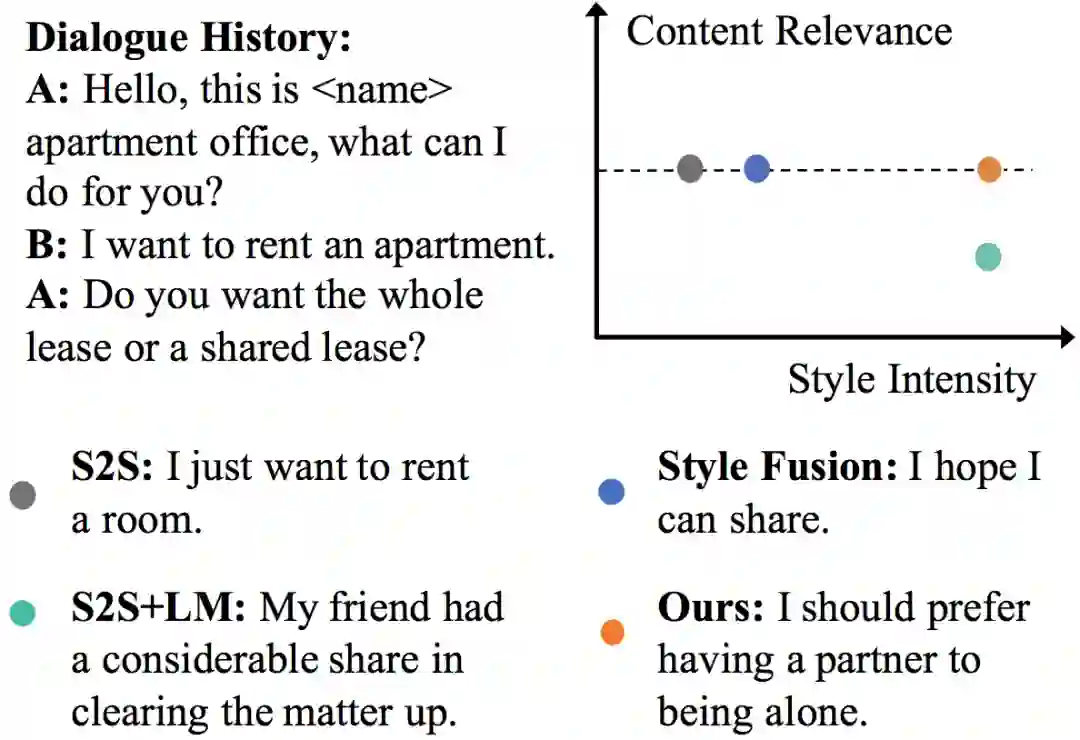
图2 内容相关性和风格强度的trade-off关系示意图
3. 模型结构
我们认为上述trade-off关系产生的原因在于:在隐变量空间内,内容信息和风格信息是耦合在一起的。为此,我们尝试了对两者进行分离,从而避免风格强度的提升影响内容相关性。我们假设一个自然语言句子的内容信息和风格信息可以分别由隐变量空间内的内容表示 和风格表示 加以建模,因此分离的预期结果便可视为将内容和风格信息和分别解耦合到 和 两个“容器”中。此外,我们将风格信息理解为了一种“数据集”级的特征,即相同数据集下的不同句子具有相同的风格;而内容信息为一种“句子”级的特征,即便是相同数据集下的不同句子,它们的句子信息也是不同的。
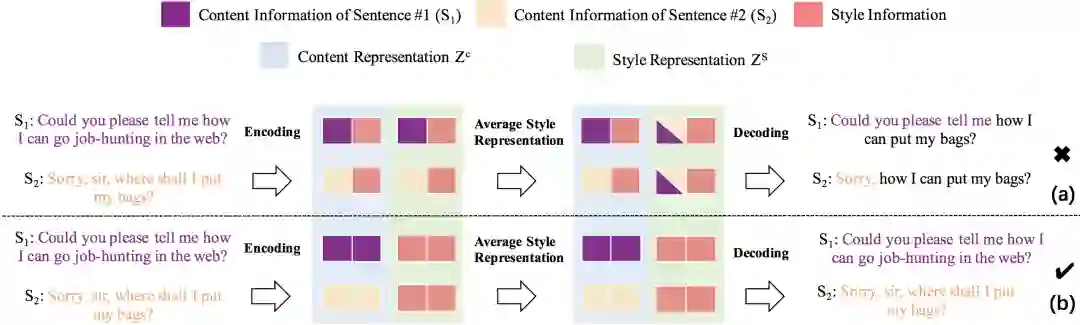
图3 内容、风格信息分离方法示意图
基于以上假设和分析,我们提出了如图3所示的分离方法。以包含2个样本的batch的训练过程为例,图中的紫色和橙色方块分别表示两个样本的内容信息。两个样本来源于相同数据集,因此风格信息相同,统一用红色方块表示。我们的目标是将紫色和橙色的内容信息分离到蓝色背景的 中,将红色的风格信息分离到绿色背景的 中。为实现该目标,我们在解码前对 在batch内的样本之间进行了平均化。若内容和风格信息没有分离,那么不同样本的内容信息在平均化后将混杂在一起,使得解码无法还原输入,如子图(a)所示;若成功分离,不同样本的风格信息彼此相同因而不会受平均化影响,内容信息在 中未被平均化,同样不会被影响。因此,该方法将鼓励分离行为以减小输入重建损失。
4. 实验结果
我们在DailyDialog数据[4]上进行了实验,并对比了如下的基线方法:
-
S2S:序列到序列模型 -
S2S+LM:序列到序列模型结合风格语言模型 -
Style Fusion:基于结构化隐变量空间的风格化对话生成模型
表1展示了人工评价结果,该评价借助亚马逊人工标注平台,将每一个测试样本同时分发给5位标注者。每位标注者被要求在给定对话历史的条件下,在本文方法和一个基线方法回复中选择出哪一个更好。可以看出,在内容相关性方面,本文方法取得了和最佳基线方法相近的效果;在风格强度方面,本文方法显著优于所有基线方法,证明了其可以在保持相关性的同时显著提升风格强度。
表1 人工评价实验结果

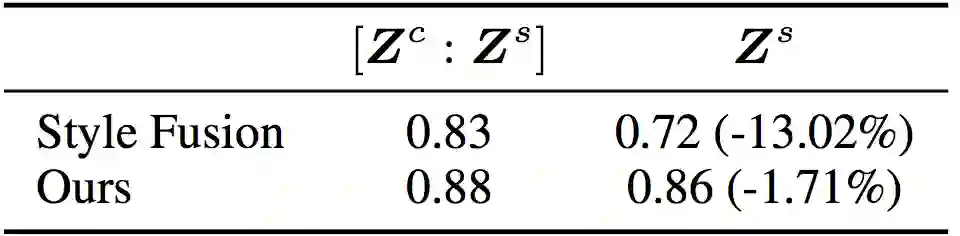
此外,我们还对内容和风格的分离效果进行了分析。具体地,我们以某个表示(例如
)作为输入,训练根据该表示预测风格的分类器,然后使用验证集的准确率作为该表示包含的风格信息量的表征。分析结果如表2所示,基线方法仅根据
预测的准确率为0.72,相比根据完整表示([
:
])预测的准确率下降了13.02%,证明相当一部分风格信息依赖于内容表示
。相比之下,本文方法的降幅仅为1.71%,证明绝大部分风格信息被成功分离到了风格表示
中。
表2基于表示的风格分类准确率
5. 结论
本文提出了一种基于分离隐变量的风格化对话生成方法,该方法利用内容信息和风格信息粒度的不同来实现两者在隐变量空间内的解耦合。实验结果表明,该方法可以在保证回复内容相关性的同时显著提升风格强度。
参考文献
[1] Tong Niu and Mohit Bansal. 2018. Polite dialogue generation without parallel data. Transactions of the Association for Computational Linguistics, 6:373–389.
[2] Xiang Gao, Sungjin Lee, Yizhe Zhang, et al. 2019a. Jointly optimizing diversity and relevance in neural response generation. NAACL 2019.
[3] Xiang Gao, Yizhe Zhang, Sungjin Lee, et al. Structuring latent spaces for stylized response generation. EMNLP-IJCNLP 2019.
[4] Yanran Li, Hui Su, Xiaoyu Shen, et al. Dailydialog: A manually labelled multi-turn dialogue dataset. IJCNLP 2017.
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴


