赛尔原创@EMNLP 2021 | 预训练跨语言模型中的大词表构建及使用
论 文 名 称 : Allocating Large Vocabulary Capacity for Cross-Lingual Language Model Pre-Training
论 文 作 者 :郑博,董力,黄绍晗,Saksham Singhal,车万翔,刘挺,宋夏,韦福如 原 创 作 者 :郑博 论 文 链 接 : https://aclanthology.org/2021.emnlp-main.257/ 代 码 链 接 : https://github.com/bozheng-hit/VoCapXLM 转 载 须 标 注 出 处 : 哈 工 大 S C I R
1. 简介
预训练跨语言模型(Pre-Trained Cross-Lingual Language Model)是通过在大规模多语言语料上进行预训练得到,其展现了在不同语言间优秀的迁移能力。这类模型通常由多语言词表以及 Transformer 编码器组成,可以将不同语言的文本编码进统一的表示空间。尽管大多数预训练单语模型和跨语言模型中使用的 Transformer 编码器结构几乎相同,但它们的词表有较大的区别。现有预训练单语模型的词表一般包含 30K 到 60K 子词单元,与此同时,XLM-R[1] 及 mT5[2] 等模型使用包含 250K 子词单元的多语言词表来表示上百种语言,虽然有些子词单元是跨语言共享的,但是每个语言分配的语言特定子词单元平均不超过 2.5K 个,用来表示一种语言依然是相对不足的。并且常用的多语言词表是通过 BPE 或 unigram 语言模型等算法在多语言语料上学习得到,这些算法在词表构建过程中更倾向于选择在不同语言之间共享的子词单元,如使用拉丁字母和西里尔字母的语言[3],而选中语言特定子词单元的概率较低。对于这些算法而言,很难确定是否已经为每种语言分配了足够的词表大小,使得每种语言都能被充分表示。此外,相比于单语模型,跨语言模型中的大词表不仅会降低预训练速度,同时也会导致模型参数量增加。
为了解决上述问题,本文首先提出 VoCap 词表构建算法得到一个更大的多语言词表,在构建过程中综合考虑每种语言的语言特定词汇能力及预训练语料大小为每种语言分配合适的词表大小。对于进一步加大跨语言模型中的多语言词表所带来的预训练速度降低的问题,本文提出基于 k 近邻的目标采样方法,通过近似估计训练目标中的 softmax 函数来提升跨语言模型预训练效率。XTREME benchmark[4] 上实验结果表明,基于 VoCap 方法构建的多语言词表要优于之前的词表,基于 k 近邻的目标采样方法在达成可比性能的同时,大幅度提升了跨语言模型的预训练效率。
2. 多语言词表构建方法
我们将影响跨语言模型中特定语言表现的主要因素归结为:特定语言的预训练语料大小和多语言词表对该语言的词汇能力。我们在 2.1 节中对词表的语言特定词汇能力进行分析;然后我们在 2.2 节中给出 VoCap 词表构建方法;最后在 2.3 节中给出实验结果和分析。
2.1 语言特定词汇能力分析
为了确定一种特定语言需要多少词表大小来表示该语言,我们首先引入 ALP(Average Log Probability,平均对数概率)来量化多语言词表中对特定语言的词汇能力(Vocabulary Capacity),给定由词表 切分的第 种语言的单语语料 ,其词汇能力 ALP 定义如下:
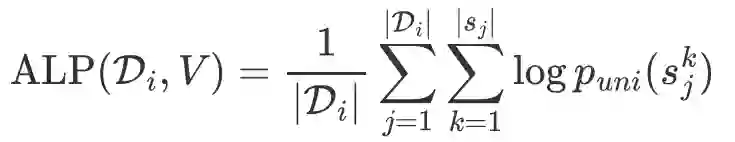
上式中, 为句子 的第 个子词单元, 为在单语语料 上统计的 unigram 子词分布。由于原始训练语料中包含大量的 code-switched 数据,很难统计多语言词表中的语言特定子词单元数量。相比之下,ALP 是一种更方便的语言特定词汇能力指标,其值反映了特定语言的子词切分粒度,并且被切分结果中低频子词所惩罚。下一步我们通过设置实验来分析词汇能力指标 ALP 和下游任务性能的相关性。
我们首先在单语语料上学习不同大小的单语词表(1K 到 30K 之间,每 1K 学习一个单语词表),这些单语词表分别在相应的单语语料上具有不同的 ALP。接下来使用得到的单语词表在单语语料上进行预训练,得到使用相应词表的预训练模型在下游任务上的性能,即可将 ALP 与下游任务性能关联。我们选择印度语(hi),波斯语(fa),意大利语(it)和俄语(ru)作为实验语言,覆盖了不同语族以及低中高资源语言。实验数据集选择XTREME benchmark 中的词性标注任务和命名实体识别任务数据集。
我们从图1、2、3中,可以得到以下观察结果:
-
增加词表大小对不同语言词表的词汇能力有不同程度的影响,说明 ALP 与语言特性有关,如 hi 和 fa 上 ALP 随词表大小增长缓慢的原因是这两种语言中复合词较少。 -
对于每种语言,每将词表大小增加 1K,所带来的ALP的提升是单调递减的,说明对已经有分配足够词表容量的语言,进一步分配更多词表容量带来的提升是有限的。 -
ALP 与下游任务性能呈正相关。
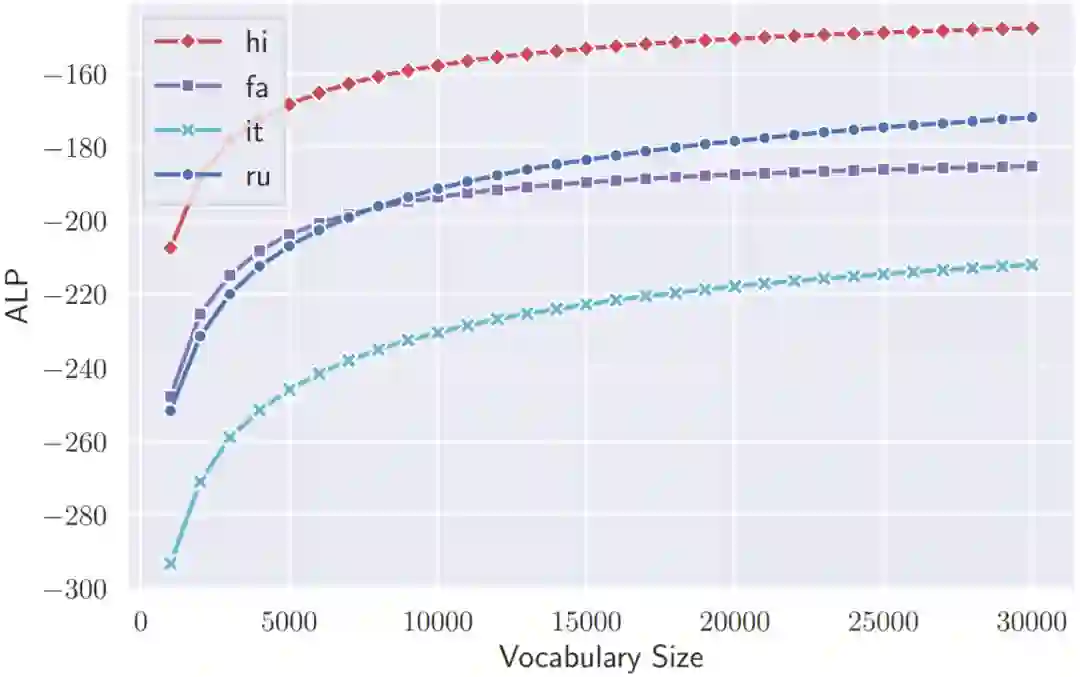
图1 不同语言单语词表的在不同词表大小下的 ALP 比较
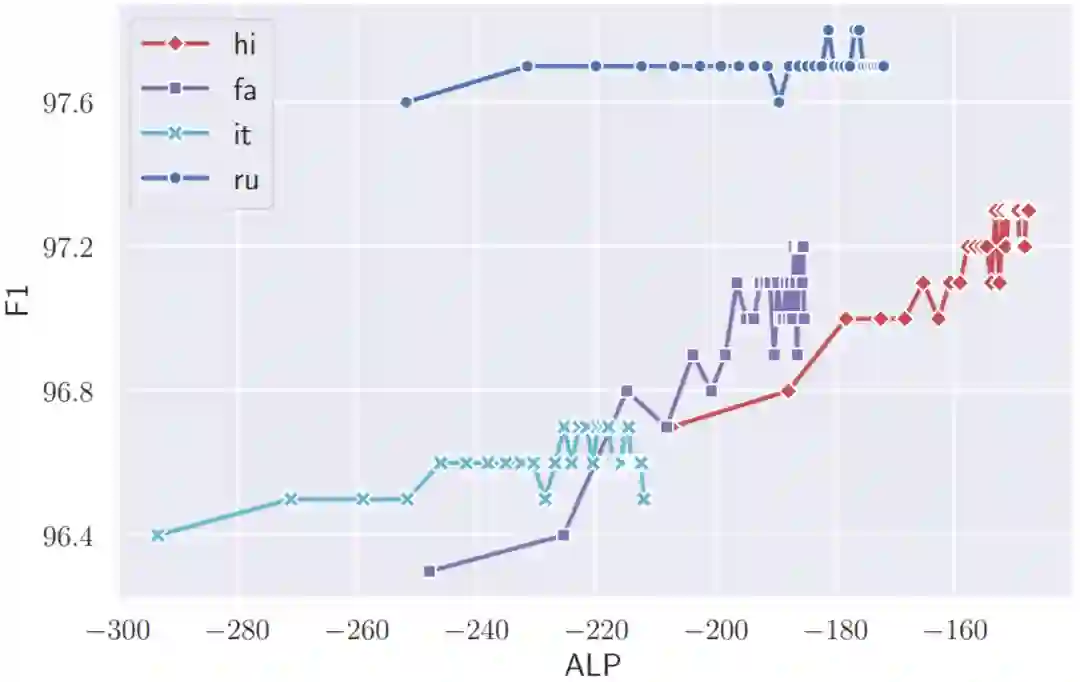
图2 不同词表在对应的单语语料上的 ALP 以及词性标注任务的 F1 分数
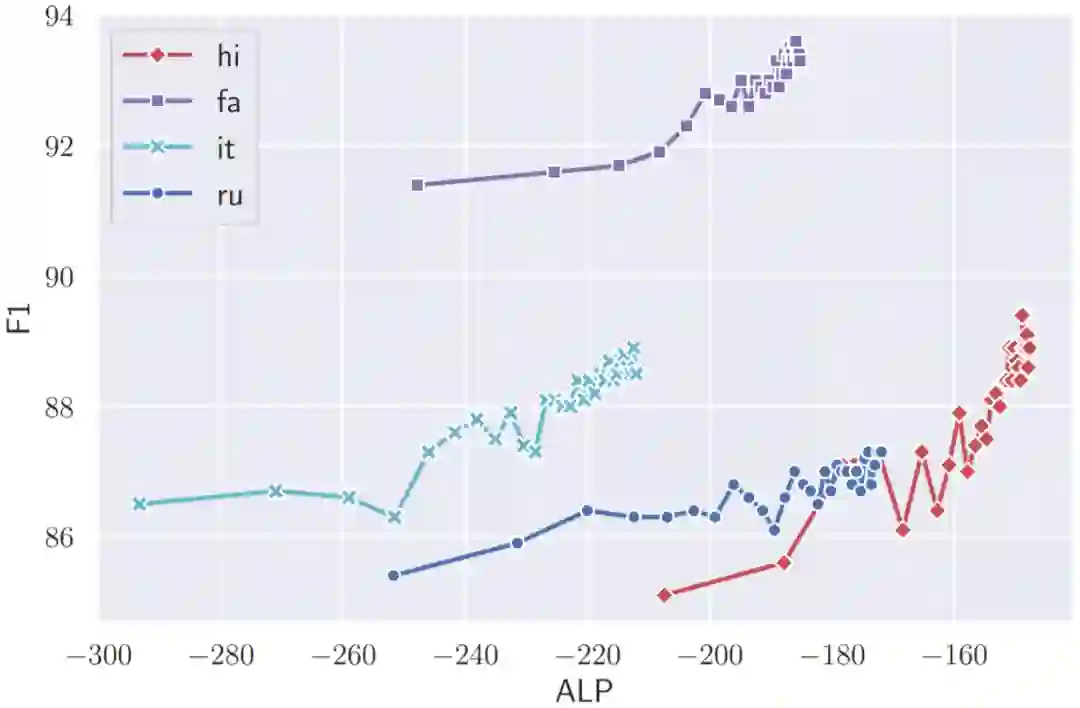
图3 不同词表在对应的单语语料上的 ALP 以及命名实体识别任务的 F1 分数
2.2 VoCap:基于语言特定词汇能力的词表构建方法
基于以上观察结果,我们将 VoCap 方法的词表构建目标定义为将预设的词表大小分配给每种特定语言的最优方式,使得构建的多语言词表在所有语言的整体词汇能力最大(以ALP评价):
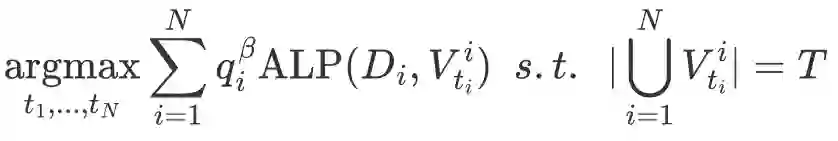

2.3 实验
表1 XLM-R250K 指使用 XLM-R 包含 250K 子词单元的词表, Joint 指使用直接在多语言语料上使用 SentencePiece 工具训练得到的词表
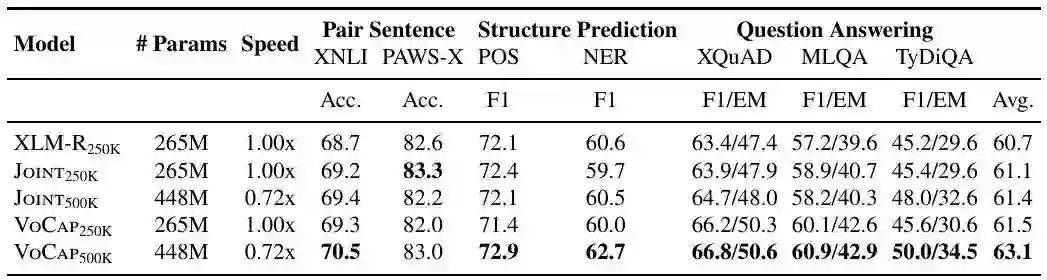
表 1 给出了基于不同多语言词表的跨语言模型在 XTREME benchmark 上的测试结果。在 250K 词表大小下,VoCap 相比 Joint 方法得到的词表在七个数据集上平均提升 0.4%;在 500K 词表大小下,VoCap 相比 Joint 方法得到的词表在七个数据集上平均提升1.7%;词表大小从 250K 提升到 500K, Joint 方法和 VoCap 方法的平均提升分别为 0.3% 和 1.6%,进一步说明了选择语言特定子词单元以及权衡每种语言所需的词表大小的重要性。
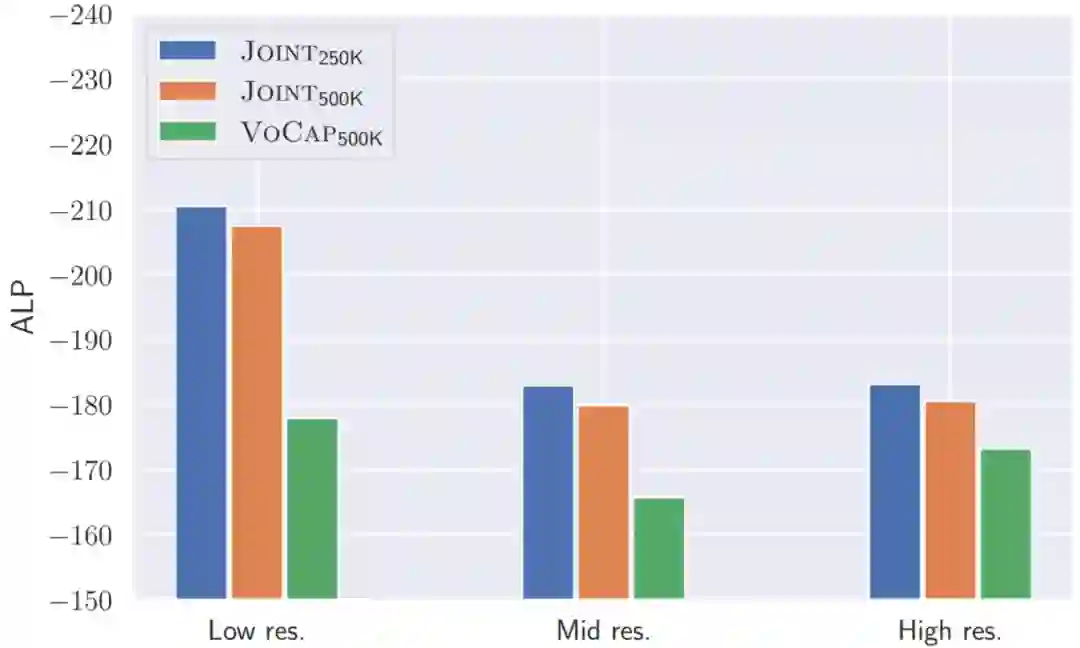
图4 不同资源语言词汇能力(ALP)的比较,条形图越短,表示词汇能力越强
图 4 给出了不同资源语言类别下,不同词表的词汇能力的比较,相比于 Joint 方法,VoCap 方法构建的词表在词汇能力指标上更优,尤其是在中低资源语言上。
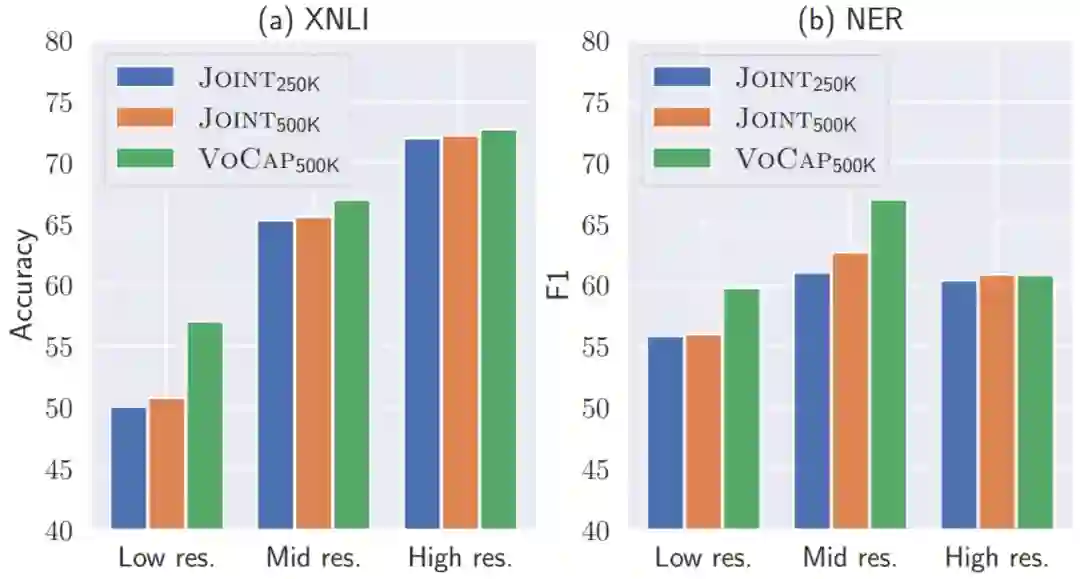
图5 不同词表构建方法在不同资源语言上对 XNLI 数据集和 NER 任务结果的影响
为了分析下游任务的提升的主要来源,图 5 给出了不同词表构建方法在不同资源语言上的下游任务性能的比较,可以发现 VoCap 方法构建的词表在中低资源语言上提升更明显,同样也能说明 ALP 和下游任务性能的相关性。
3. 大词表模型的预训练加速方法
尽管增加多语言词表大小有益于预训练跨语言模型,但使用大词表来来了两个预训练中的实际问题:缓慢的预训练速度以及增大的模型参数量。为了解决这两个问题,我们在 3.1 节中提出了基于 k 近邻的目标采样算法,该算法通过近似 softmax 来提高计算效率;然后我们在 3.2 节中介绍如何重新分配模型参数,使得模型总参数量不变;最后在 3.3 节中给出实验结果和分析。
3.1 基于k近邻的目标采样方法
在预训练跨语言模型时,原始的 MLM 训练目标为在一个较大的多语言词表上,最优化每个被 mask 子词 的交叉熵损失。基于k近邻的目标采样方法通过采样得到一个较小的词表子集 ,对被 mask 子词 的 MLM 损失函数近似如下:
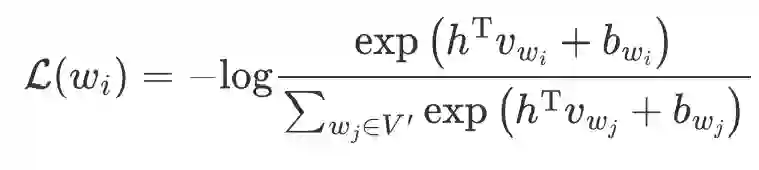
上式中, 为 Transformer 编码器在对应位置的表示输出, 为子词单元 的向量表示, 为其偏置项。词表子集的构建方式形式化如下:
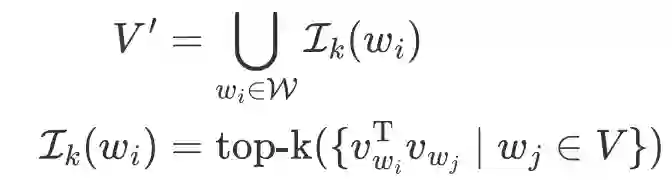

3.2 降低子词向量表示维度
为了在增加词表大小的同时保持模型参数量不变,我们仿效 [5,6] 来降低输入输出子词向量表示维度,并将降低过后的表示维度线性变换到 Transformer 的隐层维度。更具体地说,当词表大小增加一倍时,减半子词表示维度。这种策略在只略微降低模型性能的同时,提高预训练速度并减小模型参数量。
3.3 实验
表2 k-NN 指使用基于 k 近邻的目标采样方法,“half emb” 指通过减半子词向量维度保持参数量不变
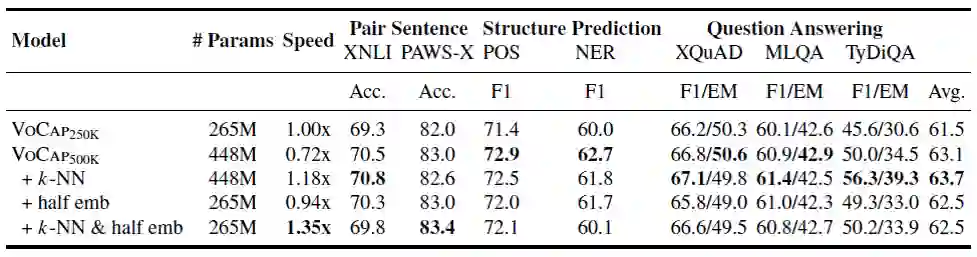
表 2 给出了加入了预训练加速方法后跨语言模型在 XTREME benchmark 上的测试结果。与传统使用 250K 词表大小的预训练相比,基于 k 近邻的目标采样算法在使用 500K 词表大小的情况下,达到了 1.18 倍加速效果的同时,在七个数据集上平均提升为 2.2%。通过进一步减半子词向量表示维度,得到与 250K 词表相同参数量的模型,此时的速度提升为1.35倍,在七个数据集上的平均提升仍然有 1.0%。
表3 基于采样的 Softmax 近似方法的对比
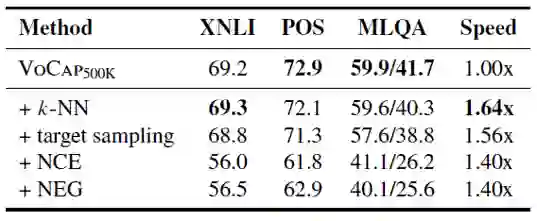
表 3 给出基于采样的不同 softmax 近似方法的对比,基于 k 近邻的目标采样方法在效果和速度上相比于之前的方法均有显著提升。
表4 k 值大小对预训练速度和下游任务性能的影响
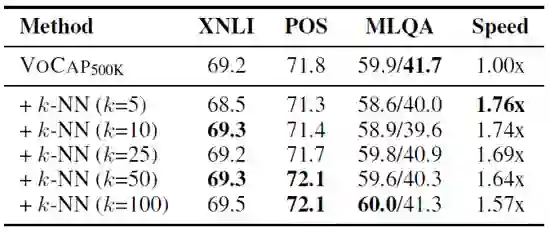
表 4 给出基于 k 近邻的目标采样算法中 k 值大小对与训练速度和下游任务性能的影响,权衡速度和性能,最终使用 k=50 作为最终实验设置。
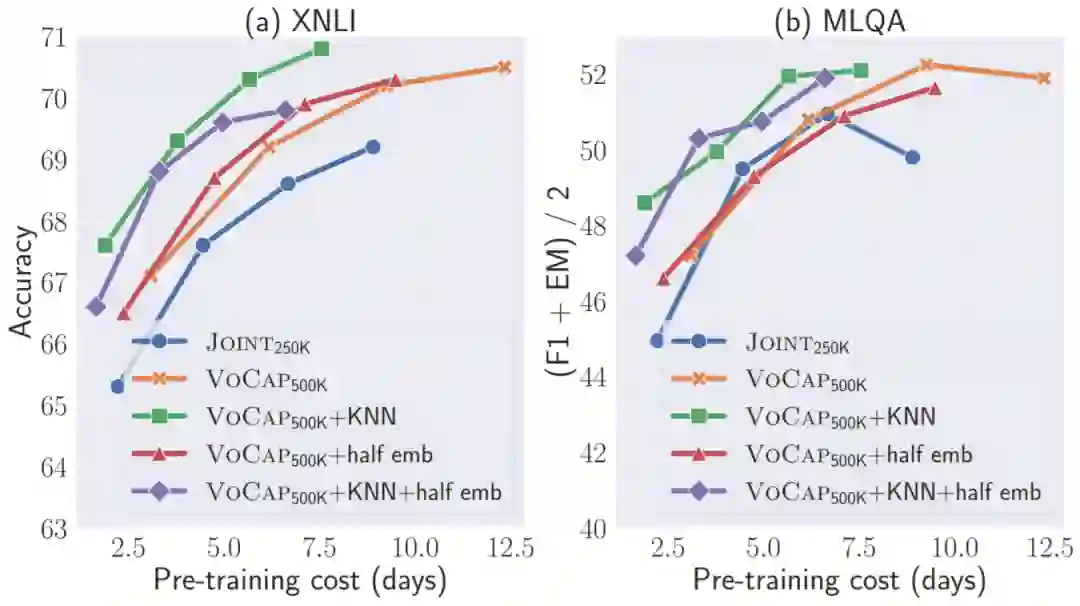
图6 不同预训练开销下跨语言模型性能的比较
图 6 为不同预训练开销下跨语言模型性能的比较,可以看出在同等开销下,使用所提出加速方法模型的性能要更加优越。
4. 总结
本文研究了大词表跨语言模型的预训练。首先,我们提出 VoCap 方法构建跨语言模型中的多语言大词表。我们首先通过定量分析说明平均对数概率是一个衡量词表中特定语言的词汇能力的有效指标,并且与下游任务性能呈正相关。VoCap 方法通过衡量为每种语言分配适当的词表大小来构建多语言词表。此外,我们提出了基于 k 近邻的目标采样方法,通过近似 softmax 函数来提高大词表模型的预训练效率。此外,我们还通过降低子词向量表示维度,在不增加模型参数量的情况下保留增大词表带来的性能提升。实验证明了所提出的多语言词表构建方法和加速方法的有效性。
参考文献
[1] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, et al. Unsupervised cross-lingual representation learning at scale. ACL 2020.
[2] Linting Xue, Noah Constant, Adam Roberts, et al. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. NAACL 2021.
[3] Hyung Won Chung, Dan Garrette, Kiat Chuan Tan, et al. Improving Multilingual Models with Language-Clustered Vocabularies. EMNLP 2020.
[4] Junjie Hu, Sebastian Ruder, Aditya Siddhant, et al. XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalisation. ICML 2020.
[5] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. ICLR 2020.
[6] Hyung Won Chung, Dan Garrette, Kiat Chuan Tan, et al. Improving Multilingual Models with Language-Clustered Vocabularies. EMNLP 2020.
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴


