论文 | 一种针对非线性数据的局部在线学习方法

小蚂蚁说:
亚太知识发现和数据挖掘会议(PAKDD,Pacific-Asia Conference on Knowledge Discovery and Data Mining)是知识发现和数据挖掘(KDD)领域的国际领先会议。它为研究人员和行业从业人员提供了一个国际论坛,分享他们的所有KDD相关领域的新想法,原创研究成果和实践开发经验,包括数据挖掘,数据仓库,机器学习,人工智能,数据库,统计学,知识工程,可视化,决策系统和新兴应用程序。
本文是蚂蚁金服录用于2018PAKDD research track长论文《A Local Online Learning Approach for Non-linear Data》(录取率仅为10%)的简要介绍,作者:杨新星、周俊、赵沛霖、陈岑、陈超超、李小龙。
摘要
由于在线学习(online learning)的高效性和可扩展性使其成为解决超大规模数据的实时学习问题的热门选择。
现阶段大多数在线学习方法都是基于全局模型的方法,即使用一个全局模型来处理所有数据,而且大多都假设流入的数据都是线性可分的。然而这种假设在实践中并非总是如此,因此基于局部在线学习框架被提出来解决非线性可分的问题。并且这种方法无需引入kernel, 从而降低了模型的复杂度。之前一些局部在线学习框架中的模型的参数大多数仅仅利用了特征的一阶信息,因此将严重限制分类器的性能。为了提高提高分类器的性能,许多二阶信息的模型被提出,比如典型的二阶在线学习算法SCW(Soft Confidence Weighted)。
受到以上信息的启发,我们提出了一个基于SCW算法的局部(Local)在线学习(Onlinelearning)算法(SCW-LOL)。该算法将单个SCW分类器扩展到多个SCW分类器,组成一个多分类器模型。我们还研究了各个分类器之间的更新和预测关系以及算法的理论预测误差上界。广泛的实验结果表明,我们提出所提出的SCW-LOL算法是收敛的,并且相对目前主流的在线学习方法,几乎在所有数据集都能达到最佳效果。
引言
近年来,在线学习算法在数据挖掘和机器学习中扮演越来越重要的角色。与通过学习整个训练数据产生最佳预测的传统机器学习技术相反,在线学习模型通过流式数据,每次只处理一个实例,根据预测结果实时更新当前模型,一直重复循环。由于在线学习不需要跟踪任何历史示例,因此避免了昂贵的训练成本并减少了大量的内存消耗。同时在线学习能实时将最新的数据反馈至模型中,减少了模型的延时性。这些优势使其在工业界有较多应用,例如搜索排序、协作过滤和异常检测等。
很早就有一些在线学习算法被提出和应用,如Perceptron Algorithm和Passive Aggressive(PA)算法。由于一阶在线学习算法仅仅使用一阶信息,往往称这些算法为一阶在线学习算法。后来又出现了大量的二阶在线学习算法来进一步提高分类器的性能。最具代表性有Confidence Weight(CW),Adaptive Regularization of Weights(AROW)和Soft Confidence Weight(SCW-I,SCW-II)算法等。二阶在线学习使用了二阶信息,其效果往往要优于一阶在线学习模型效果。一阶和二阶在线学习算法都假设传入的实例几乎是线性可分的,然而在实践中有些实例是线性不可分的,甚至是非线性的。
为了解决在线学习中的非线性可分问题,一些基于核的在线学习算法被广泛应用,但是这些基于核在线学习方法需要消耗更多的计算和内存资源。同时另一方面,为了解决线性不可分的任务,一些局部分类器已经在离线学习中提出。比如:局部线性支持向量机和局部深度核学习。这些局部分类器避免了内核建模,并且比内核方法快得多,但它们并不合适应用于在线学习任务中。为了解决在线学习的非线性数据的问题,一种基于多个局部分类器的联合在线学习框架被提出,并显示了良好的效果。为了提高模型的效果,我们进一步扩展地提出了基于SCW算法的局部在线学习算法(SCW-LOL)。稍后我们将详细描述该算法的细节以及实验结果。
问题分析
在线学习过程可表示为:时刻t时,模型遇到实时样本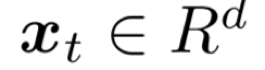
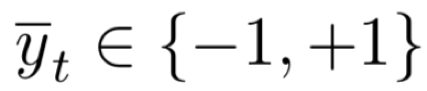
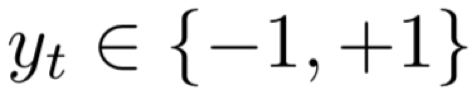
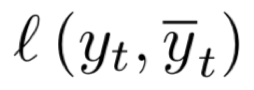
方法介绍
在这里我们将详细介绍我们的方法细节。SCW-LOL算法主要包括两部分:主分类器模型,其参数为均值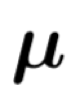
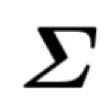
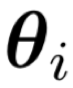
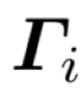
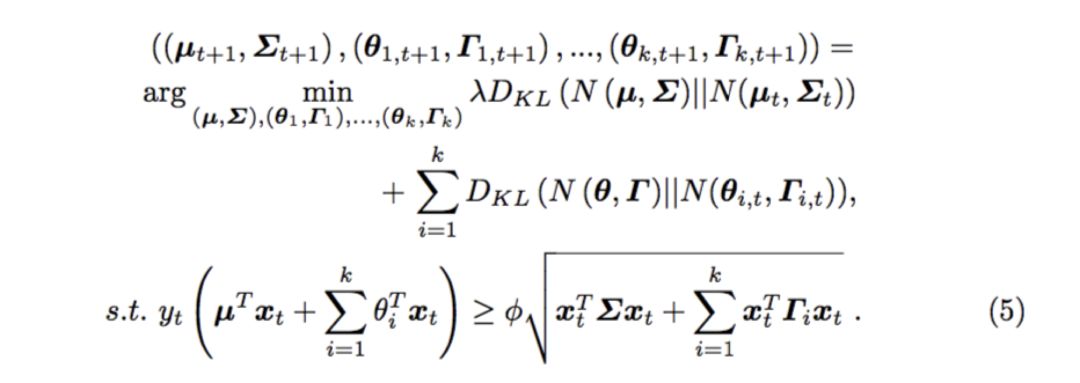
在实际中,每个样本都对应一个主分类器和一个特定的子分类器,公式(6)表示当前样本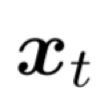
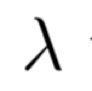
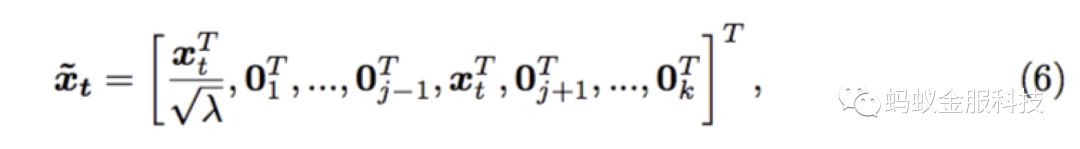
与其他传统的在线学习不同,在样本与子分类器的选择上,我们采用一种onlineKMeans算法,将样本分配到离样本距离最近的子分类器。每个子分类器维护自己的一个质心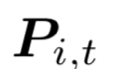
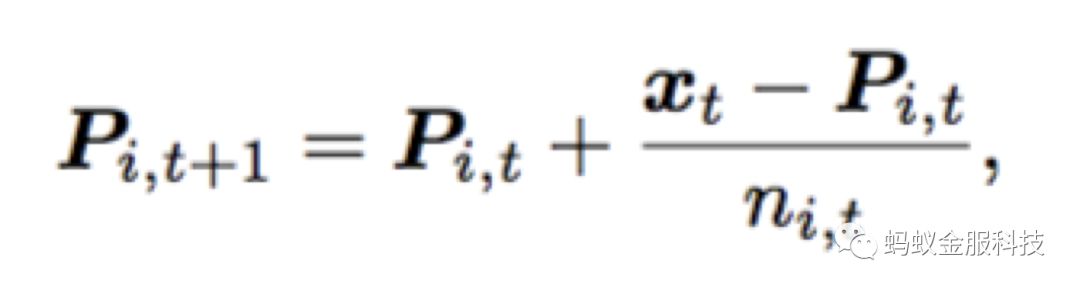
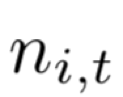
同理,主分类器和子分类器模型的参数可表示如下形式:
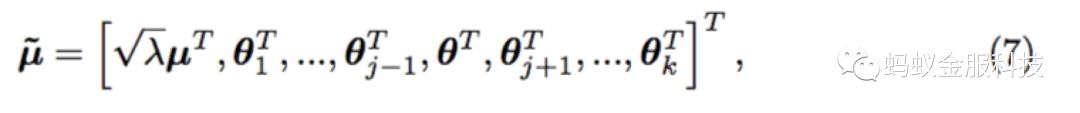
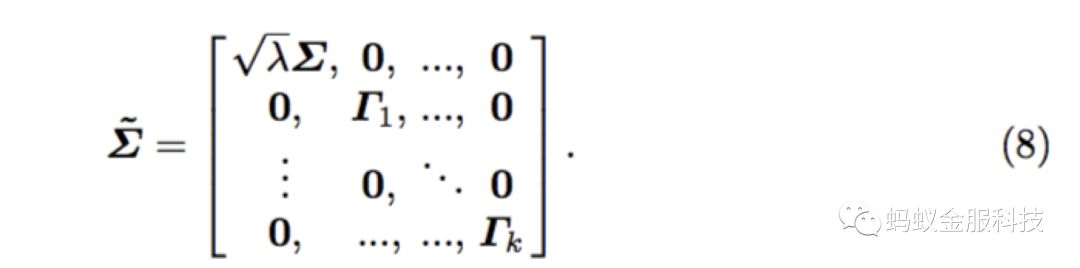
那么公式(5)可以写成如下公式:
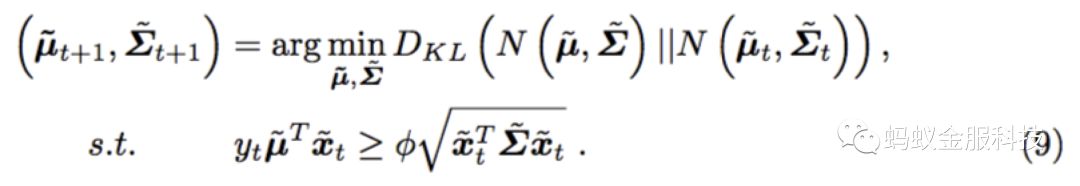
公式(9)和SCW算法的目标函数类似,模型参数的更新公式如下:
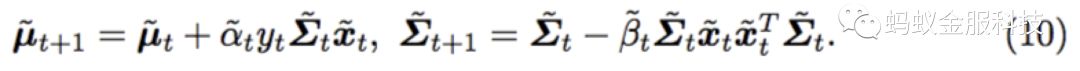
其中相关系数的计算如下:
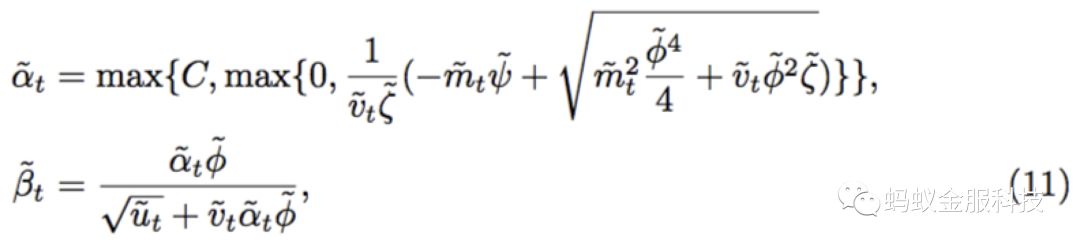
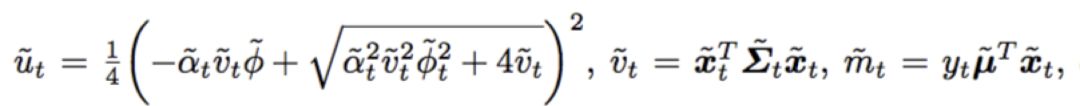
其中SCW-LOL算法训练和更新的流程如下图:

实验结果
我们采用两个主要指标来衡量在线学习的性能,一个是累积错误率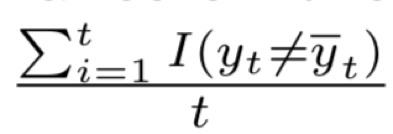
我们在10个不同数据集(5个2分类数据集,5个多分类数据集)上测试了我们的SCW-LOL算法,并同时与其他主要的在线学习算法比较,其结果如下:
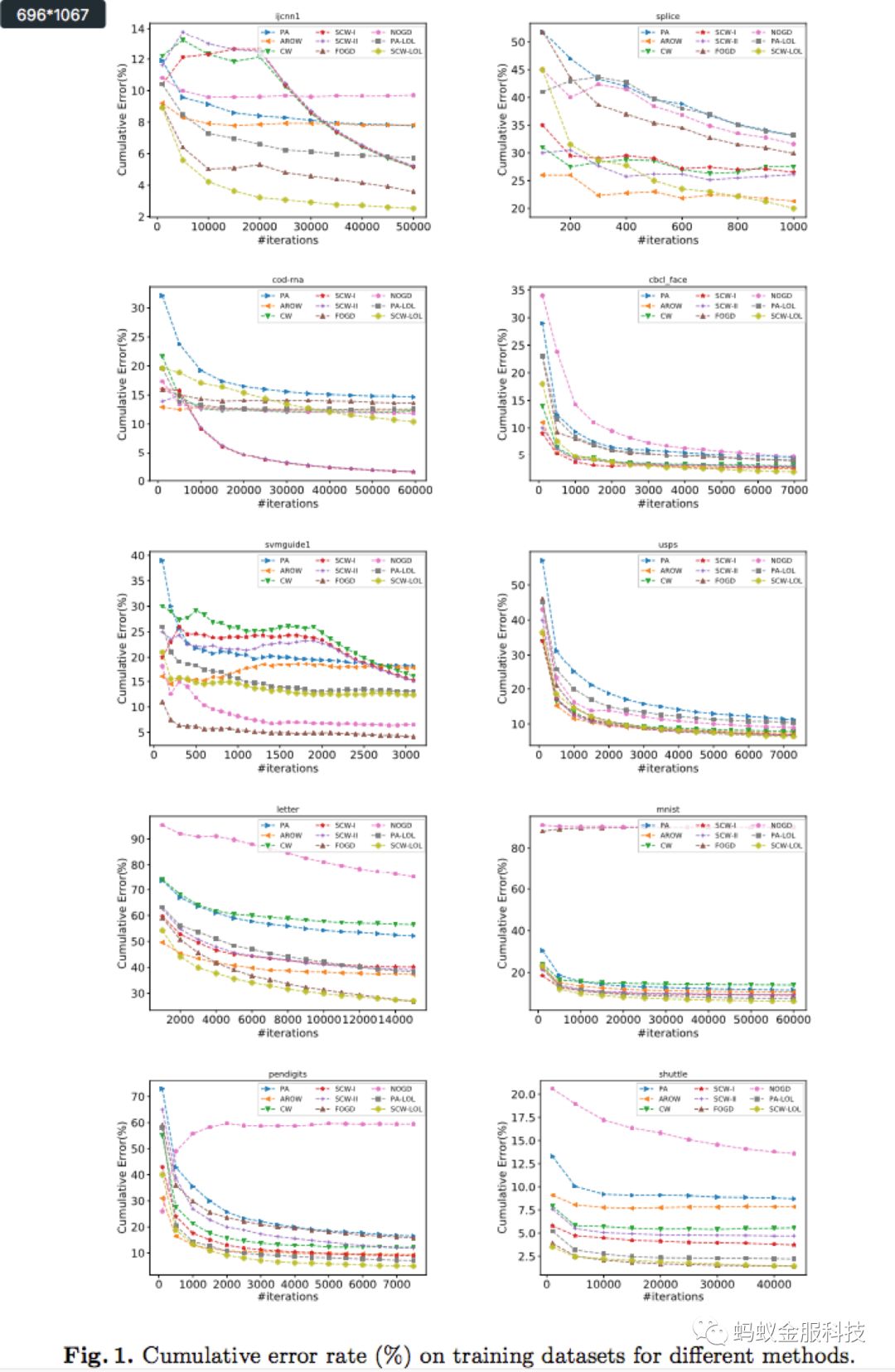
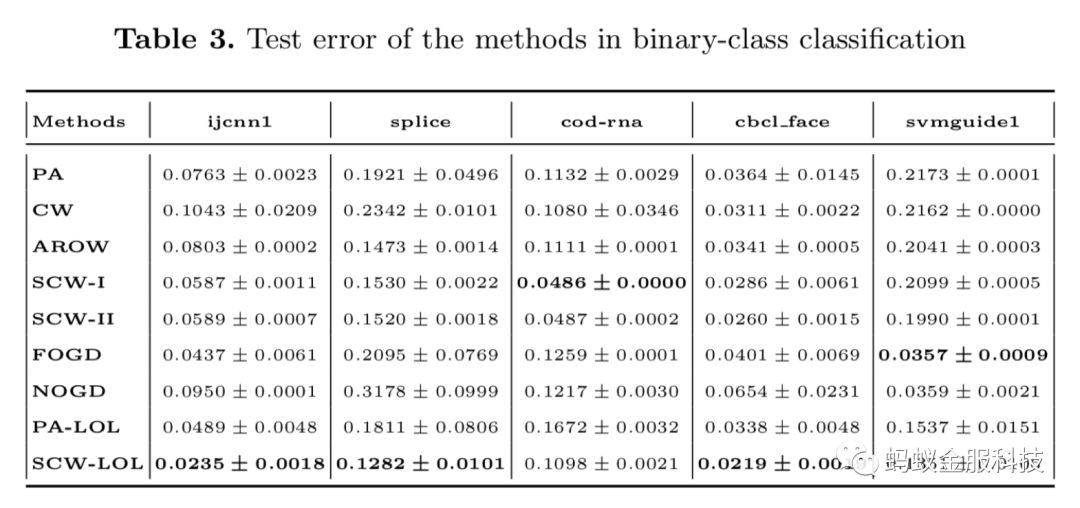
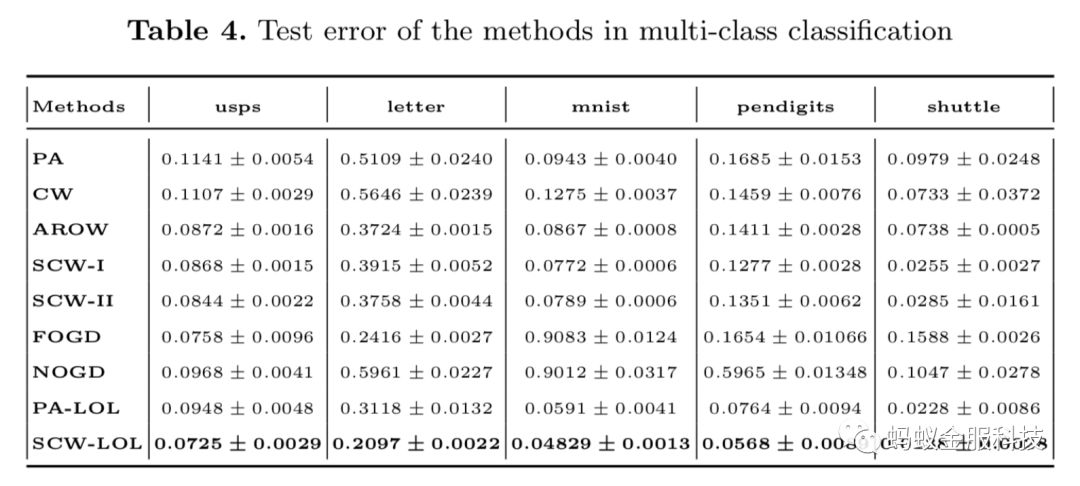
从实验结果来看,SCW-LOL算法在大部分数据集上都取得了最好的性能。尤其在多分类预测中,在所有算法中的错误率最小。
总结
为解决在线学习中非线性数据的问题,我们提出了一种基于SCW算法的局部在线学习(SCW-LOL)算法。该算法从流数据中学习并更新全局模型和局部模型。传入的样本将被分配到相应的局部模型,通过多个局部线性模型来逼近非线性模型,从而解决数据非线性可分问题。此外,我们的方法模型参数维护了二阶信息,比一阶在线学习方法的准确度更高。通过损失界限的理论分析,SCW-LOL算法的损失界限不会高于SCW算法的损失界限,也就意味着该在线学习算法是收敛的。实验结果显示,SCW-LOL算法在流式数据预测中性能十分突出,尤其在多类分类预测任务上。
— END —
蚂蚁金服科技,只为分享干货
您的转发是对我们最大的支持

欢迎在文章下方留言与我们进行交流哦~











