基于统计关系学习的自动数据清洗
点击上方蓝字

关注我们
导
读
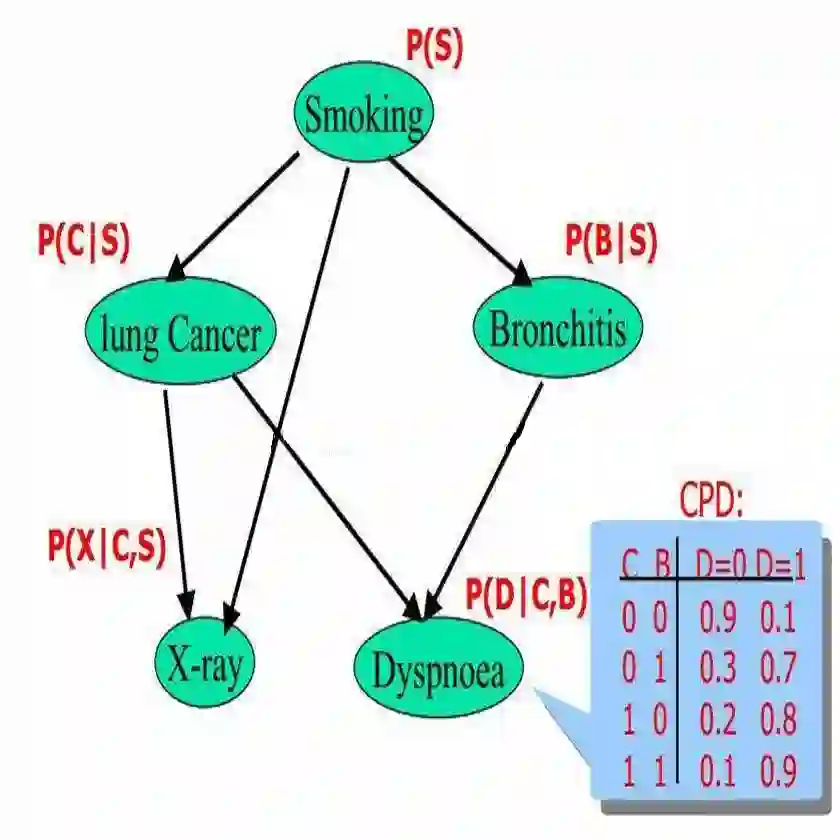
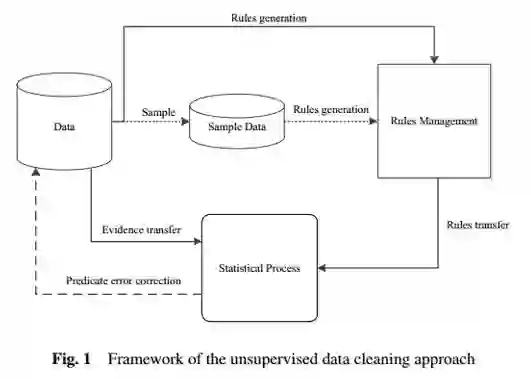
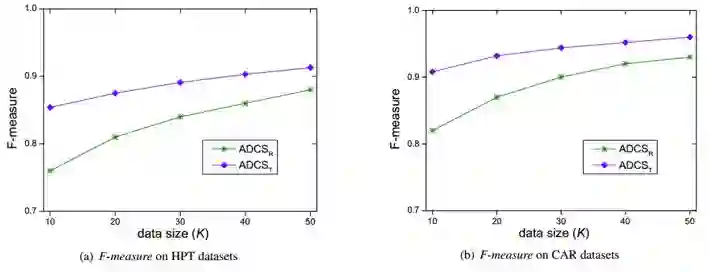
现实世界中脏数据十分普遍,从脏数据中检测和修复错误是数据分析领域的主要挑战之一,数据错误和缺失等数据质量问题直接影响到数据分析结果的准确性。过去几十年中,脏数据清洗是数据管理领域的研究热点之一。现有的数据清洗方法通常需要使用现成的约束/规则,或者需要人工介入。在现成的约束/规则缺失的情况下进行数据清洗是一个挑战性问题。本文提出一个基于统计关系学习的脏数据自动清洗方法,从脏数据中学习得到数据表属性之间的贝叶斯网络,进而转换成一阶谓词逻辑,基于互信息计算一阶谓词逻辑权重,得到对应的马尔科夫逻辑网络,将马尔科夫逻辑网络转换成DeepDive规则,进而基于DeepDive进行概率推理,推理结果用于错误数据修复和缺失数据填充。基于真实数据集的实验结果表明本文提出的方法能够有效进行脏数据的自动清洗。
文章精要




更多详细证明信息,请参考网页上的Supplementary material部分。
相关内容推荐:
利用局部计算的整体性子图匹配 2018,12(5):966-983
FCS 12(1) 文章 | 处理大规模索引中的查询偏斜:一种基于视图的方法
FCS 12(1) 文章 | 伪相关反馈的强度Pareto适应度分配:在MEDLINE中的应用
Frontiers of Computer Science


长按二维码关注Frontiers of Computer Science公众号