论文 | Unpaired Sentiment to Sentiment Translation
转自知乎专栏:西土城的搬砖日常
论文来源:ACL 2018
介绍:
本文提出了一种新的方法用于无平行语料的情感风格迁移问题。现有的情感风格迁移的模型存在的问题是,在情感迁移的同时不能保证内容不变。例如,一句话“The food is delicious”,生成却是“What a bad movie”,虽然情感的极性改变了,但主语从food变成movie,内容也发生了变化。其原因是内容和情感在同一个隐向量中,所有信息混在一起难以解释。因为没有平行语料,非情感的语义信息难以不受影响。
本文提出了循环强化学习模型。包括中立化模块和情感化模块。中立化模块作用是去除情感词,以提取非情感的语义信息。情感化模块作用是添加情感词,让中性句子情感化。其核心思想是:第一步,中立化模块先去除情感,然后情感化模块根据原始情感和语义内容重构原句,让情感化模块在有监督的情况下学习增加情感。第二步,将情感词取反,这样就可以实现添加相反的情感词。
模型:
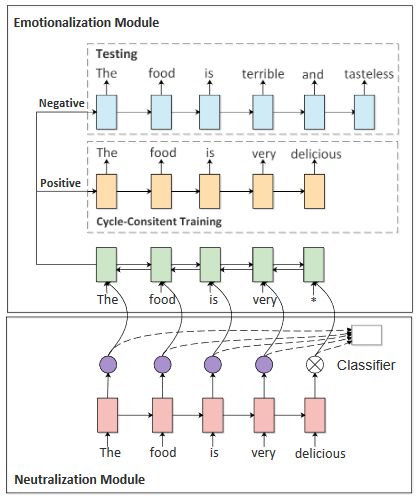
1)中立化模块,用于去除情感词,是一个LSTM+Attention的情感分类器,用LSTM来产生每个词是中性词或极性词的概率。循环强化学习要求模型有初始学习能力,因此提出一个预训练方法来让中立化模块学会判断非情感词。预训练使用了基于self-attention机制的情感分类器,将注意力权重作为指导。这么做的原因是,在训练好的情感分类器模型中,注意力权重在一定程度上反映了每个词对情感的贡献。通常情感词的权重大,中性词的权重小。试验结果表明情感分类准确率达到89%-90%,可以认为分类器充分捕捉了每个词的情感信息。根据权重提取非情感词,将权重离散化为0和1。如果某个词的权重小于这句话的权重的平均值,则其离散值为1,否则为0。情感词权重为1,非情感词为0。将这个结果可以帮助去掉情感。
2)情感化模块
情感化模块负责添加情感词。使用了seq2seq(bi-decoder)模型, encoder和decoder都是LSTM。有两个decoder,分别用于添加正情感词和负情感词。
训练:
用循环强化学习的方法,因为loss对中立化模块不再可导(对于中性词的选择是离散的),所以建模为强化学习问题,并且用策略梯度来训练去情感模块。首先计算相同情感、相反情感的输出的奖赏R1和R2,其次用策略梯度优化参数,通过最大化奖赏来训练中立化模块。这使中立化模块更好地识别非情感词。进一步,改进的中立化模块增强了情感化模块的效果。具体训练过程如下:

其中:reward有两个指标,分别考查情感转换度和内容保留度。Sentiment confidence:评价生成的文本是否符合目标情感,用预训练中的自注意力机制情感分类器做来评价。BLEU:评价内容的保持程度。reward表示为二者的加权调和平均数:
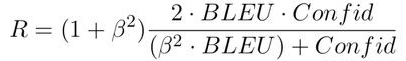
实验结果:
数据集:Yelp Review Dataset,400k训练,10k验证,3k测试。
Amazon Food Review Dataset,230k训练,10k验证,3k测试。
结果评价:
baseline:Multi-Decoder with Adversarial Learning(MDAL)
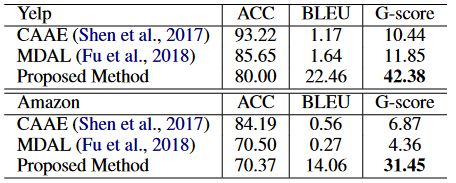
ACC:评价情感转换。BLEU:评价内容保持。G-score:二者的几何平均。
具体结果:

总结
1. 对情感转换问题,提出循环强化学习的办法,可以使用无平行语料的数据。
2. 通过将情感和语义明确区分开来保持语义。
3. 是目前工作中,语义内容上效果较好的。


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流




