详解SVO:半直接法单目视觉里程计
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
Part 1. 基本信息
这篇文章提出了一种半直接法的视觉里程计,结合了基于特征点方法的优点(并行追踪和建图、提取关键帧)和直接法的优点(快速、准确)。
主要应用场景是微型飞行器MAVs,论文开源地址为:http://rpg.ifi.uzh.ch/software,SVO团队编写的文档svo: main page:http://uzh-rpg.github.io/rpg_svo/doc。
补充:
基于特征点方法的单目VO思路:从图像中提取稀疏特征,使用描述子进行特征点匹配,再进行初始化(根据对极约束估计相机的位姿,再根据三角化得到特征点的深度(以初始化时的 t 为单位1,计算特征点的深度)),然后可以转化为PnP问题,通过构造BA(求最小化重投影误差)优化问题求解后续的位姿和路标点位置(场景结构)。
基于直接法的单目VO思路:直接根据像素灰度信息获得相机运动和对应点的投影,最初不知道第二帧中的哪个 p_2 对应着第一帧中的 p_1 ,此时根据估计的相机位姿来找 p_2 。当估计的位姿不好时, p_2 与 p_1 会有明显不同(灰度不变假设),这时通过构造优化问题(最小化光度误差),不断调整位姿以减小像素灰度差别,最终得到位姿的最优估计和投影点位置。
Part 2. 整体框架
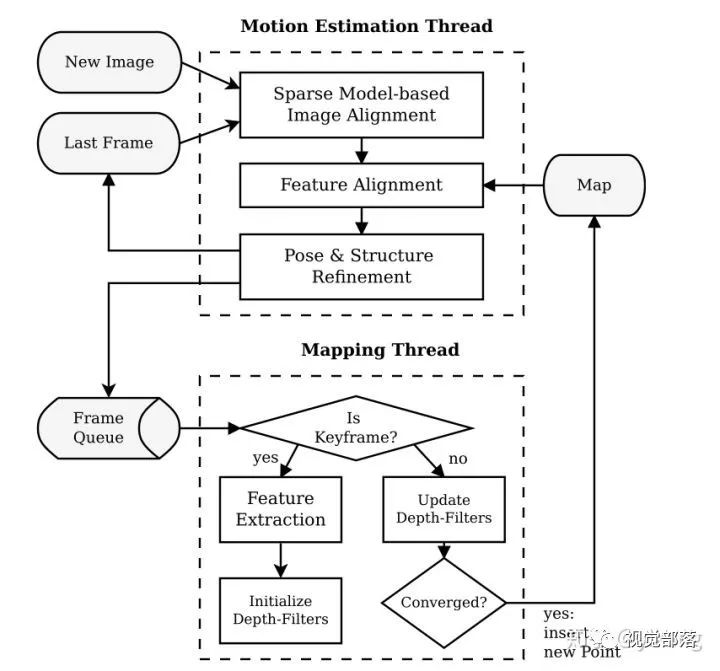
如上图所示,SVO整体上分为两个线程:
一个线程用于估计相机位姿:实现了相对位姿估计的半直接方法。
一个线程用于建图:为每一个要被估计的3D点对应的2D特征初始化概率深度滤波器,当深度滤波器的不确定性足够小(收敛)时,在地图中插入相应的3D点(更新地图),并用来估计位姿。
(1)位姿估计线程:
第一步是通过基于模型的稀疏图像对齐进行位姿的初始化,具体一点说就是通过最小化相同路标点投影位置对应的像素之间的光度误差,得到相对于前一帧的相机姿态(相对位姿)。注意这里优化的对象是帧间的相对位姿(直接法)。
第二步是通过相应的特征(块)对齐,对重投影点对应的二维坐标进行细化。意思是说,由于先前估计的位姿和路标点位置可能有误差,当前帧中的特征块与参考关键帧中相应的特征块之间会存在光度误差(灰度不变假设),我们在这一步中不考虑相机位姿,而是直接对当前帧中每一个特征块的2D位置进行单独优化以进一步最小化特征块的光度误差,这就建立了重投影点误差,也得到了相同路标点对应的重投影点的较好估计。这一步中优化的对象是当前帧中特征块的2D位置(重投影位置)。
最后一步是对相机位姿和路标点位置进行优化估计,这一步中重投影位置是使用上一步中优化后的,参考帧是地图中的关键帧,因此均认为是准确的。优化的对象是路标点位置和相机位姿。
(2)建图线程
第一步是从图像帧队列中读入图像帧,并检测图像帧是否是关键帧。
如果该帧图像是关键帧的话,就对图像进行特征提取,并对每个2D特征初始化概率深度滤波器,这些滤波器的初始化有很大的不确定性,在随后的图像帧中深度估计都将以贝叶斯方式更新。
如果该帧图像不是关键帧的话,就用来更新深度滤波器,当深度滤波器的不确定性足够小时(收敛时),在地图中插入相应的3D点(更新地图),并用来估计位姿。
Part 3. 算法推导
(1)位姿估计
① 第一步
相邻两帧间的位姿通过最小化相同路标点投影位置对应的像素之间的光度误差计算得出:
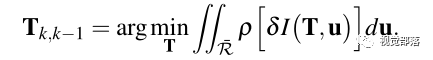
其中 

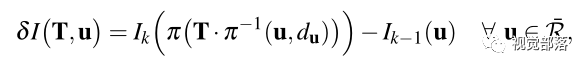 上式中
上式中
 为相机的投影模型,
为相机的投影模型,
 为像素坐标,而
为像素坐标,而
 表示深度已知的像素区域,且该区域在上一帧中也有对应投影点。
表示深度已知的像素区域,且该区域在上一帧中也有对应投影点。
该文章指出,SVO不同于以往工作中知道图像中大部分区域的深度信息,SVO只知道稀疏的特征位置的深度信息。并且使用向量 
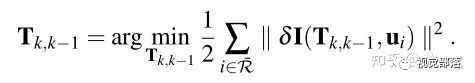
使用高斯牛顿法求解上述优化方程得到


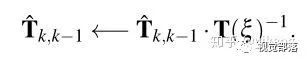
那么这个更新增量
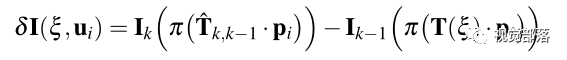
之后再对优化方程求导得到:
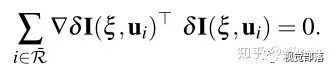
对 
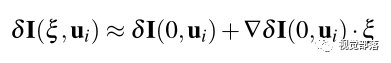
之后再考虑像素强度对扰动的导数,也就是雅可比矩阵 
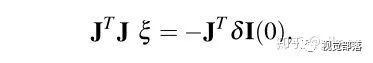
这样就可以解出
这一部分中论文还指出一个可以加速计算速度的技巧,由于前一帧图像特征块的强度值不变,以及路标点也不变,因此雅可比矩阵
至此就完成了该线程的第一步:初估相机位姿,接下来将进行第二步:优化特征块的重投影位置。
② 第二步
根据上一步得到的相机位姿,我们可以得到在当前帧中可观测到的3D点的投影点(特征点)位置的初步估计。由于第一步的位姿估计和3D点坐标存在误差,因此对投影点位置的初步估计显然也是有误差的。
在构造优化之前,先根据估计的位姿计算当前帧中特征的估计位置,然后对每一个重投影点都识别包含该点的关键帧(来源于地图map,因此该关键帧的信息认为是准确的),然后构造优化问题为:
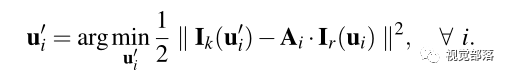
其中误差函数是光度误差 = 当前帧中特征的强度值 - 关键帧 r 中相应特征的强度值, 
在这一步中,实现了特征块之间更高的相关性(我觉得也可以说是获得特征块更准确的像素位置),但代价是违反了对极约束,因此有了下面这步对位姿和路标点位置的精细化估计。
③ 第三步
由于第二步之后的特征点坐标 
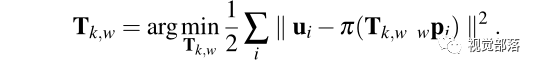
上式的形式是只对位姿进行估计的BA问题,可通过高斯牛顿法进行迭代求解。随后可以再构造最小化重投影误差的优化问题来优化观测到的路标点的位置。
④ 几个细节的讨论
相信很多读者在读完前面内容的时候会和我有一样的疑惑:为什么要“重复的”优化两次位姿呢?明明可以直接从第二步开始使用光流法追踪特征点,进而实现特征对齐,然后再进行第三步的BA求解位姿和路标点。论文中作者给出了解释,因为如果直接使用光流法追踪特征点,需要更大的特征块和应用图像金字塔进行“由粗至精”的追踪,这样做不仅更费时间,而且追踪效果也不够准确(那就需要提取并判断异常点了)。因此第一步先对图像进行稀疏对齐后,可以很方便的对特征对齐进行初化,并且这一步也满足了对极约束,确保没有异常点(误匹配特征)。
上面这个疑问是“第一步是否需要”,而下面这个疑问则是“第三步是否需要”。
有些学者认为第一步中得到的相机位姿足够用了,但是进行第三步后位姿精度显著的改善了,而且对比第一步和第三步优化位姿的过程可以发现:第一步中是以前一帧为参考帧,第三步中是以地图中的关键帧为参考帧。由于关键帧经过前端和后端的处理后特征的位置认为是准确的,因此这一点不同大大提升了位姿估计的精度。
(2) 建图
建图线程根据前端得到的位姿 

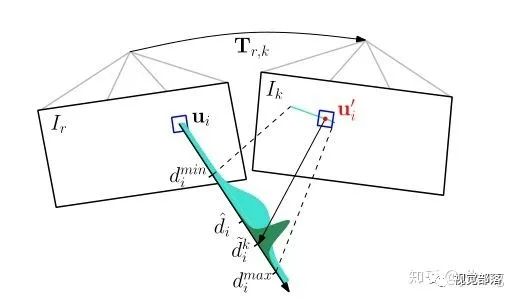
如上图所示,每一个概率深度滤波器都和一个关键帧 r 相关联。概率深度滤波器被关键帧 r 初始化:不确定度很大,均值设置为参考帧的平均深度(上图的浅绿色波形)。
在后面的图像帧 k 的极线上搜索与特征块 
论文中提出的三角化的方法之所以相较于其他方法有很大改善,是因为每一个深度滤波器都经过了多次测量,直至该深度值收敛,所以异常点非常少。此外还将异常点显式建模了出来,这使得滤波器在高度相似的环境中也可以收敛(鲁棒性提高)。
Part 4. 算法细节讨论
(1)图像金字塔
为了应对较大的帧间移动(快速场景),以0.5为缩放率构建了5层的图像金字塔,实现“由粗至精”的估计。为了节约时间,只优化到第三层,因为这个时候的精度就足够了。
(2)初始化地图
最初的地图是由前两帧图像进行三角化得到的,这一点没有什么疑问,因为也只能这样了。
(3)关键帧选择依据
SVO将检测新读入图像帧与之前所有关键帧平均图像深度之间的欧式距离,如果超出平均深度的12%(也就是一个阈值),那么就将其选为关键帧。(这里的计算量似乎并不小啊,肯定有更优的关键帧选取方案,先mark住)
(4)地图中的滑动窗口
为了提高优化效率,SVO在地图中只保留固定数量的关键帧(滑动窗口法),这些固定数量的关键帧就是用于位姿估计线程中的第二步和第三步。关于滑动窗口法之前的文章中已经介绍过了不再复述。
当一个新的关键帧被插入地图中时,SVO将剔除距离当前相机位置最远的一个关键帧。这种做法当然很直接,但是似乎并不是最优的:如果将新插入的关键帧同上一个关键帧进行比较,如果相似度过高(大于一个阈值),那么就可以删除上一个关键帧而不是最远的关键帧,因为过于相似的关键帧对优化的帮助并不大。
(5)图像的单元划分
在建图线程中,SVO将图像划分为固定大小的网格单元,这些网格的作用主要有两点:
初始化深度滤波器。如果某个单元区域在前端没有提取关键帧并进行三角化(也就是没有2D-3D的对应点),那么就在该单元区域中提取FAST角点,并用来初始化概率滤波器。值得注意的是,此时新提取FAST角点时,要做金字塔的每一层都进行提取,由粗至精得到精确的角点位置。
初估相机位姿。没错就是在位姿估计线程的第一步,这种图像块的做法我们在前面提到过。
Part 5. 实验结果讨论
(1)准确性
论文测试了SVO算法在笔记本和无人机的嵌入式平台上的效果,并且在前面框架介绍中我们可知算法最多使用了两个CPU核心。并且为了测试效果文章还算法设置了两套参数:快速型和准确型。(如下所示)。并且论文主要和改进版PTAM进行了对比。

然后论文测试了两种参数配置以及改进版PTAM(当时最好的单目SLAM算法)在同一个数据集中的表现。在结果图中可以看到位姿误差和姿态角速度误差都得到了改善(方差显著减小,均值更加接近0)
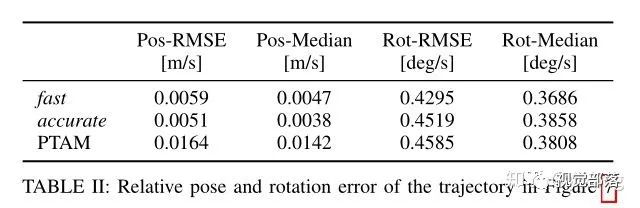
针对这一改善,论文分析他们提出的算法之所以好于改进版PTAM是因为PTAM没有提取金字塔级的最高分辨率的特征,并且PTAM的特征没有进行亚像素细化。而且PTAM之所以没有进行最高分辨率的特征提取是因为相似高频纹理导致了过多的异常3D点,那么SVO是怎么解决的呢,那就是建图线程中的深度滤波器很好的减少了异常点的数量。
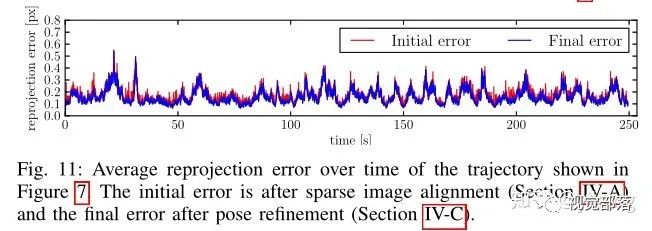
这张图中给出了重投影误差的变化,相比于位姿估计线程第三步精细化估计(蓝线),第一步的初估位姿(红线)已经非常接近于最终的位姿,说明第一步稀疏图像对齐取得了很好的效果。这个结果也说明第一步和第二步之间的特征对齐,只产生了很小的移动,也即特征块的位置移动很小。
上面的结果也说明,快速型的c参数设置对于精度来说已经足够了。(是不是说明可以探索一个精度足够的最快参数设置版本?)
(2)速度
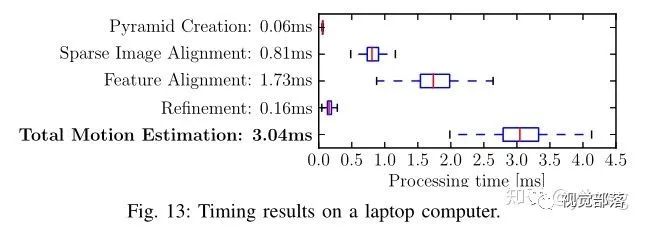
论文还对运行时间进行了分析,SVO的快速型参数设置(300 fps)大幅优于PTAM的表现(91 fps),分析原因是SVO没有像PTAM一样在位姿估计线程就提取特征,这是非常耗费时间的。
并且由于引入了深度滤波器,SVO只需要更少的(120)特征点就可以达到更好的效果,而PTAM需要160~220个特征点。
除此以外!竟然建图线程的运行时间还小于位姿估计线程的运行时间!amazing啊有没有!
(3)鲁棒性
由于引入了深度滤波器,使得3D异常点大大减少,这不仅提高了准确性,还提高了鲁棒性,使得SVO在高重复性的场景中也可以应用。
总计一下,上面提到的速度、准确性和鲁棒性的的改进主要来自于 [深度滤波器] 的引入。
Part 6. 总结
主要想说一下为什么这个算法被称为半直接法呢?
相比于普通直接法根据像素强度直接估计相机运动和3D点位置(需要提取关键点),SVO提出的方法加入了一些改动,直接法的应用主要是在位姿估计线程的第一步:初估相机位姿。在这一步中图像被固定尺寸大小的单元划分为网格,然后利用直接法使得对应图像块的光度误差最小,进而得到相对于上一帧的相对位姿。而后面不同于直接法的是,又对投影点坐标进行了优化(第二步),以及利用地图中的关键帧和第二步得到的投影位置对位姿和路标点进行了细化。因此位姿估计线程的这种做法被取名半直接法。
从0到1学习SLAM,戳↓
交流群
欢迎加入公众号读者群一起和同行交流,目前覆盖SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群,请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

好赞!我看完啦




