浅谈立体匹配中的新式应用场景

基于深度学习的立体匹配(stereo matching)是根据左右视角的 RGB 图像来进行视差(深度)估计,两张图像的成像条件是具有相同内参的两台彩色相机,在同一时刻成像,并且经过水平校正。
Accurate Stereo Matching:以有监督学习的方式提升立体匹配算法在常用数据集上的准确率;
Real-Time Stereo Matching:探索更快速的立体匹配算法以满足实时性需求;
Un-/Self-supervised Stereo Matching:不依赖视差标签的无监督/自监督立体匹配;
Adaptive Stereo Matching:解决合成数据和真实数据领域偏差的自适应立体匹配;
Efficient Stereo Matching:探索轻量级的、内存占用低、参数量少的更高效的立体匹配;
-
Confidence Estimation & Measures:立体匹配中的置信度/不确定性估计和度量;
今年的顶会上涌现出一些新的立体匹配应用场景研究,它们不同于上述研究方向,而是基于立体匹配问题的引申和拓展。本文将从新场景,新应用和新数据三个方面来介绍相关的开源研究工作。

新场景

论文标题:
360SD-Net: 360° Stereo Depth Estimation with Learnable Cost Volume
论文来源:
ICRA 2020
论文链接:
https://arxiv.org/abs/1911.04460
论文代码:
https://albert100121.github.io/360SD-Net-Project-Page/
1.1 概述
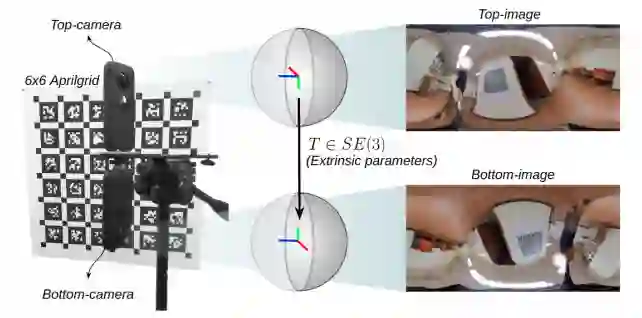
上图展示了利用两个 Insta360® ONE X 相机采集全景图像的过程。将底部图像(bottom)作 180 度翻转,即可与顶部图像(top)进行配对来估计视差。360° 全景图像有以下两个特点:
-
将三维空间中的水平线投影到二维平面时并不总是保持水平,这意味着它不满足经典立体匹配中的水平极线约束。因此,作者采用上下(top-bottom)两个相机采集,使得上下视角图像在竖直方向是对齐的; -
图像的顶部像素和底部像素比那些位于赤道线附近的像素拉伸得更多。因此作者提出了新的 360SD-Net 来专门学习竖直对齐的全景图像的视差/深度。
1.2 方法
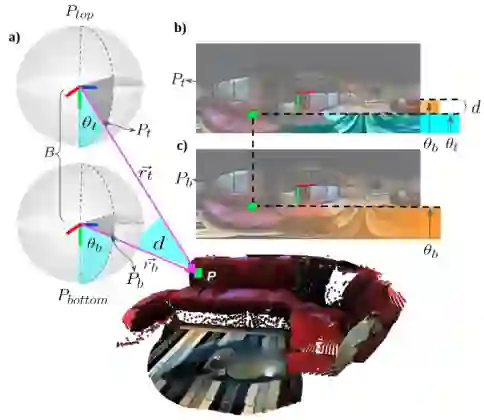
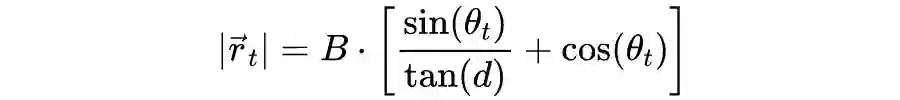
360SD-Net
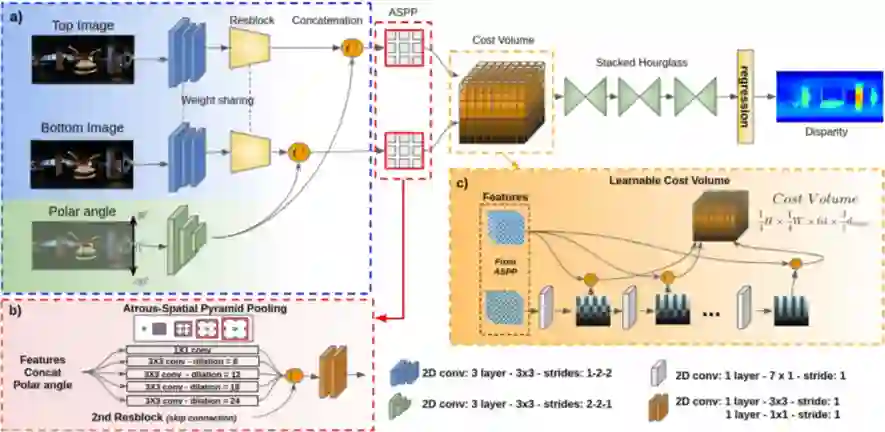
上图是 360SD-Net 的整体结构,其主体框架来自于 PSMNet,包括三个组成部分:1)两个分支的特征提取模块用来提取双目全景图像的特征和极角的融合特征;2)用于扩大感受的 ASPP 模块;3)用于非线性球面投影的可学习的 cost volume。
最后采用 Stacked-Hourglass 来回归视图,采用 smooth L1 损失监督。
Polar Angle:根据球面视差的定义,视差的计算和投影向量的极角有关,这里作者引入极角作为额外的输入分支(如上图(a)),用来增加几何信息。采用残差模块提取 RGB 图像的特征,用三层 2D 卷积来提取极角的特征,之后将二者的特征进行融合,这比直接将二者的 concat 作为输入要更好。
ASPP Module:由于全景图像比常规图像具有更大的感受野,因此作者采用有空洞卷积的 ASPP 模块(如上图(b))来提取多个尺度的特征,并且增加特征提取的感受野,以适应全景图像。
Learnable Cost Volume:已有的深度立体匹配采用固定步长的像素搜索策略来构建 cost volume,然而这种固定步长的逐像素搜索策略与来自极角的几何输入信息是不一致的。
1.3 实验
360°全景图像数据集
作者利用 Minos 虚拟环境和 Stanford3D 点云的重投影,通过 Matterport3D 采集了两个具有照片真实感的数据集 MP3D 和 SF3D。这两个 360° 双目全景图像数据集各包含 1602/800 张训练图像,431/200 张验证图像和 341/203 张测试图像,其分辨率为 1024*512,包含深度标签。
实验结果





论文标题:
Bi3D: Stereo Depth Estimation via Binary Classifications
论文来源:
CVPR 2020
论文链接:
https://arxiv.org/abs/2005.07274
论文代码:
https://github.com/NVlabs/Bi3D
2.1 概述
已有的立体匹配算法需要对每个像素点的精确视差值进行估计,虽然深度立体匹配模型在准确率上逐步提升,但是也需要较大的计算消耗。

2.2 方法
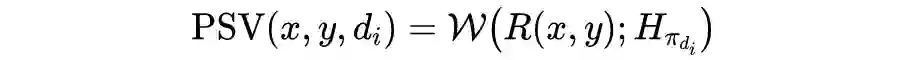
二值深度估计
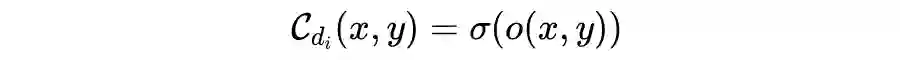
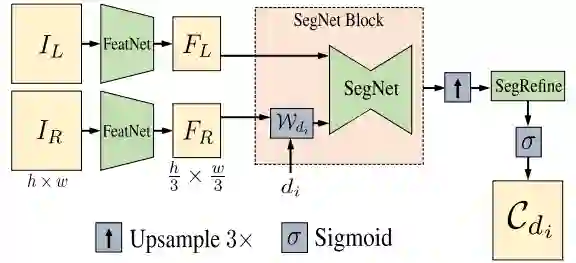
上图是 Bi3D 的网络结构图,利用 FeatNet 提取左右图特征,之后对右图进行 warping,将左图和 warp 后的右图作为 SegNet 的输入,再经过 SegRefine 优化得到二值化置信度估计。
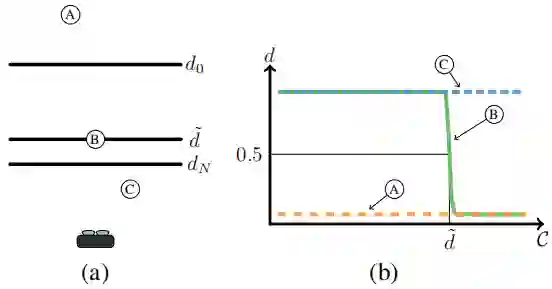
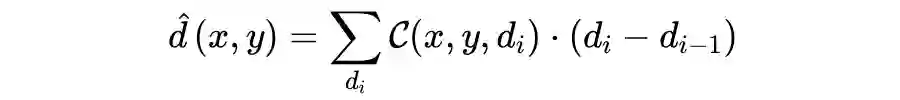
量化深度估计
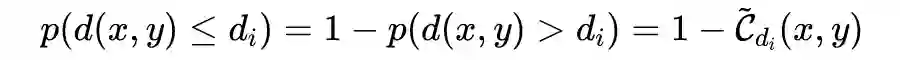
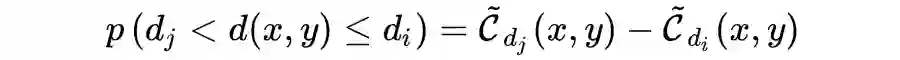
选择深度估计
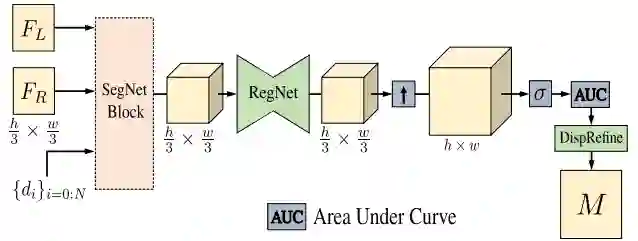
在上图中,对每个视差层级运行一次 Bi3DNet 中的 SegNet 模块,之后利用编码-解码结构的 RegNet 提取特征,构建匹配代价体 cost volume,从而得到各个视差层级的置信度估计;
2.3 实验




论文标题:
Learning Stereo from Single Images
论文来源:
ECCV 2020
论文链接:
https://arxiv.org/abs/2008.01484
论文代码:
https://github.com/nianticlabs/stereo-from-mono/
3.1 概述
真实场景下的立体匹配数据集往往难以进行深度/视差标签的采集或标注,因此已有的真实数据集的规模都很小,例如 KITTI,MiddleBury 和 ETH3D。
一方面,可以利用计算机图形学构造 3D 模型,通过模拟器来构建合成图像,但是合成图像和真实图像之间存在很大的领域偏差(domain gap),主要表现在色彩、纹理信息等方面。
另一方面,可以通过真实图像的纹理贴图来构建更符合真实场景的合成图像,但是在场景布置,物体形状和色彩选择等方面都需要大量的人工设计,并且场景渲染也需要较大的计算资源。
这篇论文提出一种新的立体匹配数据集构造方法,无需人工数据采集和合成图像构建,通过已有的单目深度估计算法和其他任务中的单目自然图像来构建双目立体匹配数据集,比如用于目标检测的 COCO 数据集就具有大量真实场景的数据集。
3.2 方法
-
利用已经训练好的单目深度估计网络 来对左图进行深度估计,得到深度信息 ; 是由估计的深度信息根据设定的相机参数转换得到的视差标签 ,其中 是从 中随机采样的尺度因子,这样可以保证得到的视差范围具有多样性。 -
合成的右图 由左图 和估计的视差 通过 warping 操作得到,即将 中的每个像素 向左平移 个像素,再利用插值法合成 。
-
由于遮挡的原因, 中会出现缺失的像素点;另外,多个像素点可能最终落在右图中的同一个像素点上,由此带来冲突。 -
单目深度估计的不准确会造成深度图的不连续,从而在构造右图时出现很多野点(flying pixels)。
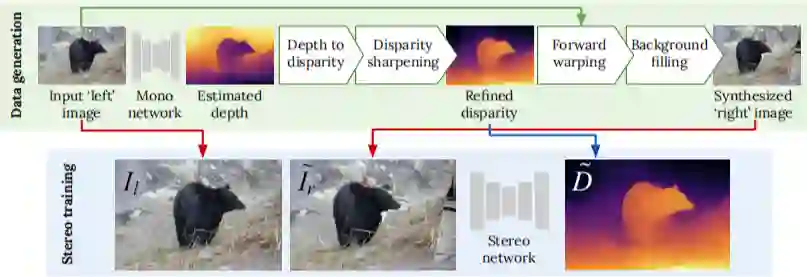
遮挡和冲突处理
深度图锐化处理

3.3 实验
数据集

实验结果
-
相比于在合成数据上训练,本文的方法能够获得性能更好,泛化更强的结果; -
对单目深度估计的结果具有鲁棒性,不论单目数据的来源,均能得到较好的泛化结果; -
消融实验表明论文中的设计是有效的; -
在各种立体匹配模型上均能获得性能提升; -
随着构造的立体匹配数据集规模越大,相应的性能会越高; -
在 MfS 数据集上预训练再在真实数据集上微调的性能比原来在合成数据集上预训练再微调要好。
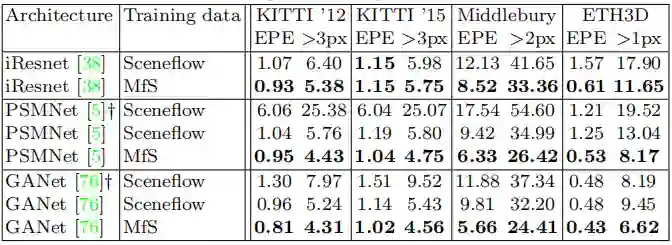
上表的实验结果对应于结论(5),以上6个结论在论文中均有相应的实验支撑,感兴趣的同学可以对照论文详细阅读。

小结
本文从新场景,新应用和新数据三个方面介绍了近来顶会上在立体匹配领域的一些新的研究思路。新场景是在 360 度全景图像上的球面视差估计,全景图像不仅仅在立体匹配领域开始受到关注,在语义分割等领域也有不少研究。
新应用是在将精确的视差估计简化为二值化、多级量化的视差估计,能够在资源较少的情况下快速实现目的。新数据是通过单目深度估计和已有的数据集来构造双目数据集,这种思路在图像分类等领域已有不少应用,在立体匹配领域尚属首次。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




