CVPR 2018 | 商汤科技论文详解:立体匹配神经网络的自适应训练
CVPR 2018正在美国盐湖城如火如荼举行,今天我们还将为大家分享一篇论文解读。以下是在计算摄影领域,商汤科技发表的一篇论文,该工作通过挖掘立体匹配神经网路自身有利的特性,实现立体匹配神经网络在新场景下的自适应训练。基于本工作的训练方法已应用到商汤科技的双摄解决方案中。本文由商汤科技研究员庞家昊与商汤科技研究院副总监孙文秀等共同完成。
论文:Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
作者:Jiahao Pang, Wenxiu Sun, Chengxi Yang, Jimmy Ren, Ruichao Xiao, Jin Zeng, Liang Lin
论文链接:
https://arxiv.org/pdf/1803.06641
简介
双目立体匹配是计算机视觉中的经典问题:给定一组校准好的双目视图(主图与辅图),立体匹配旨在寻找主图每一像素在辅图中的对应点并得到对应的视差,从而估计视图中所有像素的深度信息(如图1所示)。
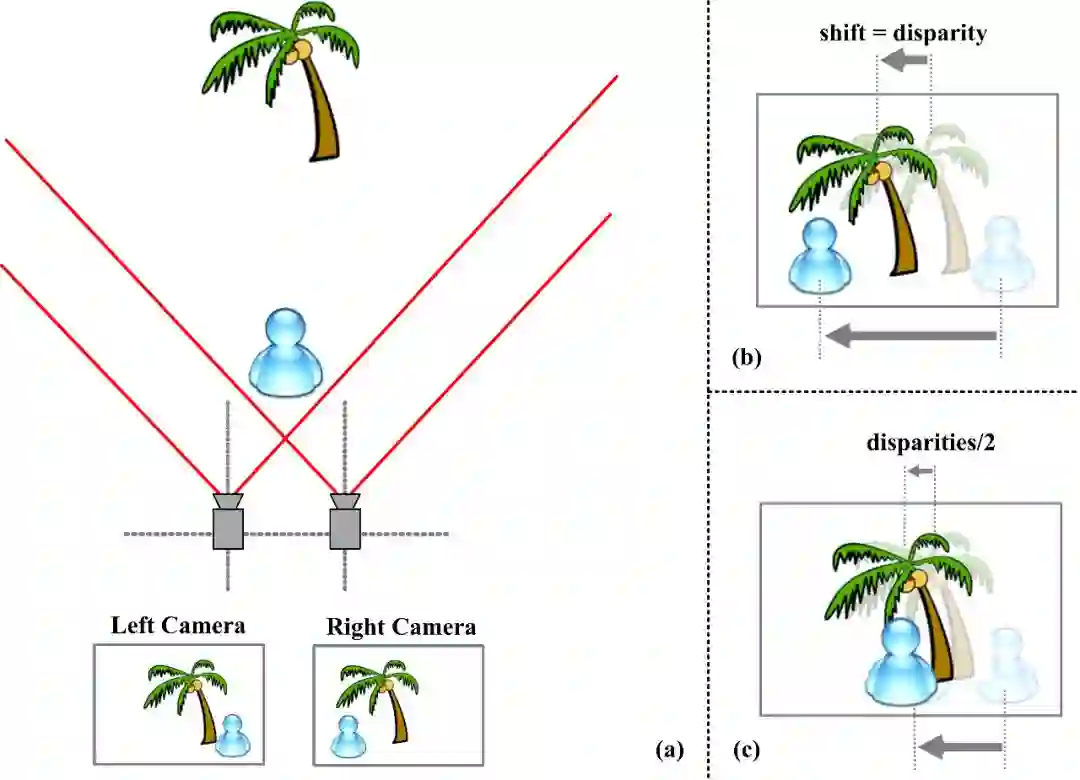
图一:
立体匹配示意图
双目立体匹配在许多领域有着重要的应用价值,例如,通过智能手机的双摄模组模拟单反拍照的背景虚化效果,需要立体匹配算法计算出准确的深度图;在辅助驾驶的场景中,有效的立体匹配算法能够提供准确可靠的深度信息以保证驾驶的安全性。随着深度学习技术的不断发展,在特定场景下,神经网络在立体匹配问题上已经达到了优异的性能。然而,若将某一特定场景下(如驾驶场景)训练的立体匹配网络直接应用到另一场景(如人像)下,其效果会大打折扣;另一方面,采集新场景下准确的深度标注信息需要相当繁琐且昂贵的资源。
为解决此问题,本文提出了Zoom and Learn(ZOLE)方法,其结合了立体匹配网络的性质及传统方法中的图拉普拉斯正则化,使立体匹配神经网络在缺少新场景标注信息的情况下,实现自适应训练,使其能被有效地应用到新场景之下(如图2所示)。

图2:
(由左至右)主图、由合成数据训练的
网络结果(第二、三列)、本文的结果
多尺度观察
得益于深度学习技术的迅猛发展,在特定场景下(如驾驶场景),卷积神经网络已在双目匹配问题上优异的匹配精度。但若把适用于特定场景下的立体匹配网络直接应用至另一场景中,其结果往往难以接受;另一方面,要采集新场景下准确的深度信息也并不容易。
为解决此问题,现有的工作通常利用左右一致性检测实现半监督或无监督的立体匹配网络训练。然而,在实际场景下,主图与辅图的成像性质往往并不一致(色调、白平衡、噪声等),使得基于左右一致性检测的方法难以有效泛化至新场景。
不同于现有的方法,一方面本方案仅需要新场景下的一系列主辅图作为训练数据,而不需要新场景中正确的视差图来监督网络的学习;另一方面,本工作基于立体匹配网络在不同输入尺度下的不同表现实现自适应训练。

图3:
两种不同应用匹配网络的方案
具体地,假设一个已经在旧场景下训练好的立体匹配神经网络S,那么对于某一组新场景下的主辅图,若直接将其输入到神经网络中,可以得到新场景的视差图(记作D)。若将输入图像上采样r倍,再将上采样后的主辅图输入到神经网络中,并将神经网络的输出缩小r倍,可以得到另一视差图(称作D'),D'与D有着同样的尺寸(如图3所示)。本文作者发现,与D相比,通常地D'拥有更为丰富的高频细节(如图4所示)。
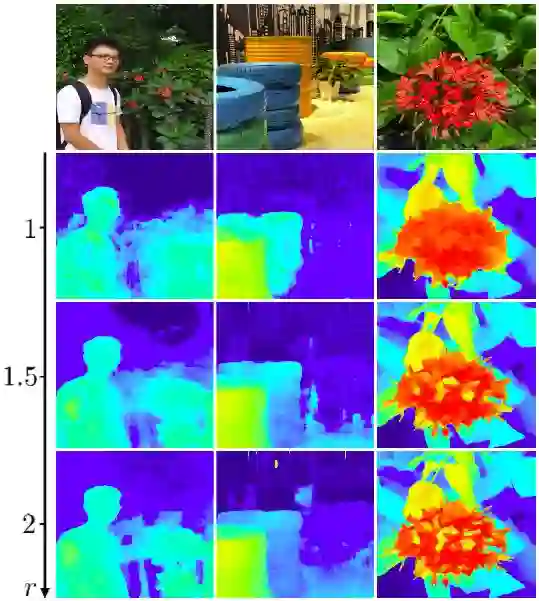
图4:
不同尺度下得到的视差图,第一行为对应的主图
然而,更大的放大倍数r并不一定意味着更好的结果,由表1可见,输入主辅图放大到一定程度后,得到的视差图精度开始下降。
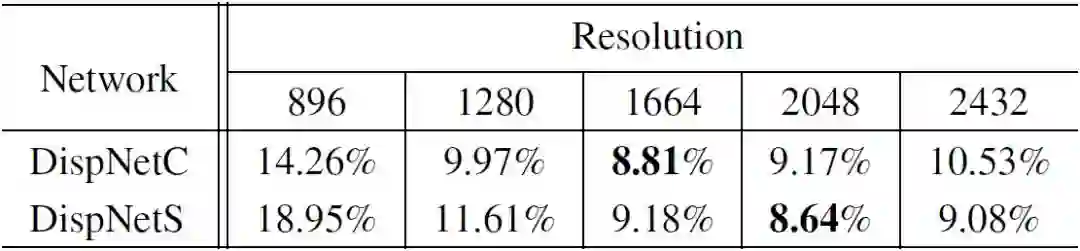
表1:
将KITTI数据集的主辅图放大到不同分辨率后
输入匹配网络得到的性能指标(数字越小越好)
导致该现象的原因是,将输入图像放大等价于让立体匹配算法在亚像素的精度下进行匹配(更高的颗粒度),于是能产生更多的高频细节;然而,神经网络等价的感受野也会相应变小,换句话说,网络变得相对“短视”了,因此当r达到一定数值后,匹配精度开始变差。
为了在没有新场景标注的情况下也能实现神经网络的训练,本文作者提出让神经网络不断学习自身在高颗粒度下输出的高频细节,这也是本方法的名称Zoom and Learn (简称ZOLE)的含义。
先放大,再学习
为方便叙述,设想已有一个预先在计算机合成数据(旧场景)上训练好的立体匹配网络S,以及旧场景下的训练数据(大量计算机合成的主辅图与对应的视差图),同时有一系列真实拍摄的人像主辅图(新场景),但并无对应的视差图。本文目标是对网络S进行自适应训练,使其能适用于日常生活中拍摄的人像图像。
本文算法的总体流程是,把计算机合成数据(有已知的视差图)和人像数据(没有视差图)混合在一起,让立体匹配网络迭代地进行训练。在每一个训练批次,将前述两种数据混合在一起,对于计算机合成的数据(旧场景)采用通常的方式进行有监督的训练;对于人像数据(新场景),则按照前述方法用网络S计算对应的高颗粒度视差图,以其作为当前的伪标注对网络进行有监督训练。
除此之外,为防止匹配网络学习到一些错误的细节,对于新场景数据,本文引入了经典方法中的图拉普拉斯正则化(Graph Laplacian Regularization)作为神经网络训练时的损失函数,从而引导神经网络有选择地学习高颗粒度输出中有意义的图像细节。
实验结果
下面展示将在FlyingThings3D数据集(计算机合成数据)上训练的立体匹配网络自适应到人像场景中(如图5所示),可见相比起原来的网络,经过自适应训练后的网络在人像数据上能产生更准确的视差图及更丰富的细节。

图5:
(由左至右)主图、原来网络的结果
及自适应后的网络结果
表2展示了立体匹配的定量分析结果。由于自行采集的人像数据并无真实的视差图信息,本文先计算视差图,并用其及辅图合成出一张左图,然后计算合成的左图与真正的左图的PSNR和SSIM,以此估量自适应训练后的立体匹配神经网络在新场景下的性能(如表2所示),可见本文提出的方法在两项指标上均大有提升。

表2:
原网络及自适应后的网络
在人像数据集与计算机合成数据集上的表现
结论
本文提出了一种立体匹配神经网络自适应训练方法——Zoom and Learn (ZOLE)。
首先,本文作者观察并分析了立体匹配神经网络在不同输入尺度下的性质,发现将主辅图上采样后输入到网络中能得到在原有的尺度上所没有的高频细节。本文利用这个有利的特性,使神经网络在原尺度下也能产生更多细节,提出让神经网络学习自身的高颗粒度输出,同时采用了经典方法中的图拉普拉斯正则化约束神经网络的结果,使其有选择性地学习有用的细节。
实验表明,本方法可以有效地将某单一场景下训练的立体匹配网络泛化至不同场景。此外,进一步的实验也展示本文算法在光流估计及图像分割上也能带来性能的提升。