AB实验在滴滴数据驱动中的应用


文章作者:仇科凯 滴滴出行
内容来源:滴滴技术
导读:在各大互联网公司都提倡数据驱动的今天,AB实验是我们进行决策分析的一个重要利器。一次实验过程会包含多个环节,今天主要给大家分享滴滴实验平台在分组环节推出的一种提升分组均匀性的新方法。本文首先会介绍一下滴滴AB实验的相关情况,以及在实验分组环节中遇到的问题。然后介绍目前在实验对象分组方面的通用做法,以及我们对分组环节的改进。最后是新方法的效果介绍。
1.
互联网公司中,当用户规模达到一定的量级之后,数据驱动能够帮助公司更好的决策和发展。在滴滴各个团队中,我们经常会面临不同的产品设计方案的选择或者多个算法方案的决策,比如顶部导航栏的排序方案一二三,派单算法一二三等等。传统的解决方法通常是由该领域经验丰富的专家来决定,或者由团队成员讨论决定,有时候甚至是随机选择一个方案上线。虽然在某些情况下传统解决办法也是有效的,但是让AB实验后的数据说话,会让方案选择更加有信服力。
滴滴Apollo AB实验平台,支持了滴滴诸多业务的功能优化、策略优化以及运营活动,提供了在线实验以及离线实验的能力,并行实验数达到 6000+ / 周。在分组方法上提供随机分组以及时间片分组来应对不同的实验场景。效果分析方面,我们对基础指标、率指标、均值指标、留存指标等多种类型的指标提供了均值检验、VCM、Bootstrap等多种分析手段。
2.


上述的这种分组方式称为CR(Complete Randomization)完全随机分组。进行一次CR,能将一批实验对象分成对应比例的组。但是由于完全随机的不确定性,分完组后,各个组的实验对象在某些指标特性上可能天然就分布不均。均值,标准差等差异较大。如果分组不均,则将会影响到第四步的实验效果分析的进行,可能遮盖或者夸大实验的效果。
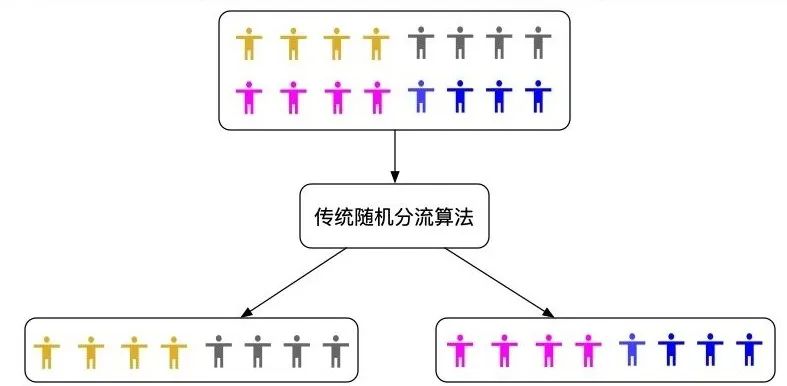
随机分流人群分组不均示意图
基于CR的风险较大的情况,一般会对CR进行简单的一步优化,即进行RR(Rerandomization)。RR是在每次跑CR之后,验证CR的分组结果组间的差异是否小于实验设定的阈值。当各组的观察指标小于阈值或者重新分组次数大于最大允许分组次数后,停止分组。
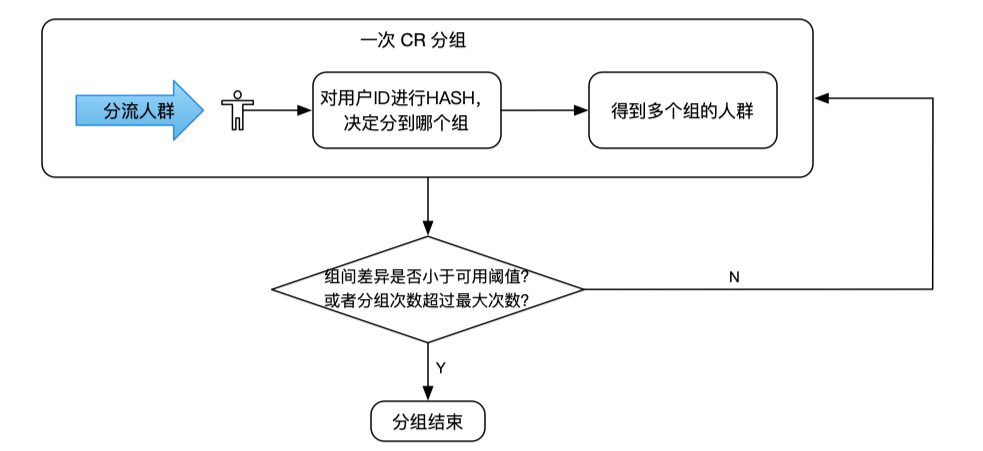
相比于CR,RR通过牺牲计算时间,能在一定概率上得到符合要求的分组。重分组次数与输入的实验对象样本大小相关。样本量越大,需要进行重分的次数一般较少。但是RR分组能得到符合要求的分组有一定的概率,且需要花更多的时间。所以,我们希望通过对分组算法的改进,在一次分组过程中分出观察指标均匀的分组结果,如下图所示。
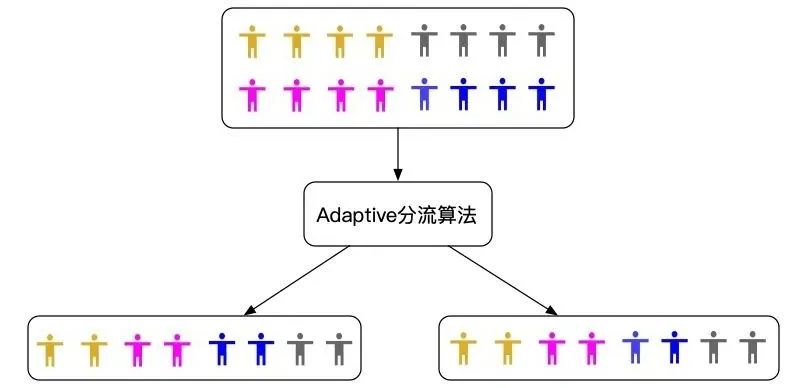
分流人群分组均匀示意图
Apollo实验平台实现了滴滴AI LAB团队设计的Adaptive(自适应)分组算法。
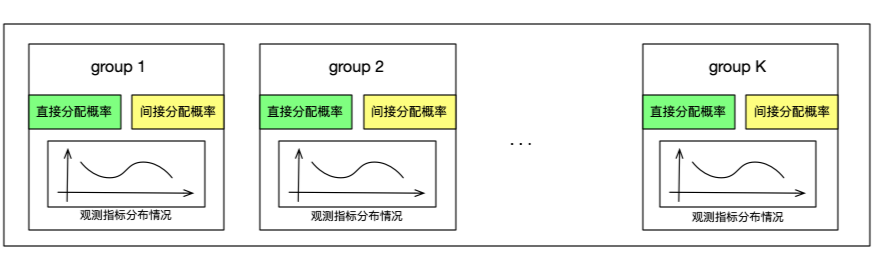
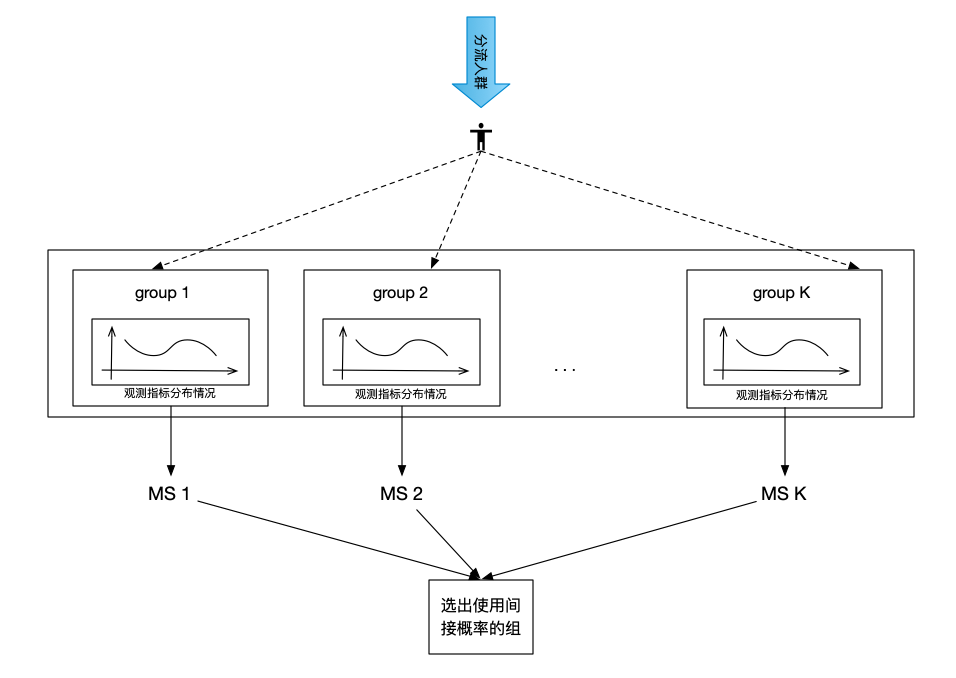
Adaptive分组方法可以在只分组一次的情况下,让选定的观测指标在分组后每组分布基本一致,可以极大的缩小相对误差。相比于传统的CR分组,Adaptive分组的算法更加复杂,在遍历人群进行分组的同时,每个组都需要记录目前为止已经分配的样本数,以及已经分配的样本在选定的观测指标上的分布情况。从分流人群中拿到下一个要分的对象后。会对实验的各个组进行计算,计算该对象如果分配到本组。本组的观测指标分布得分情况。然后综合各个组的预分配得分情况,得到最终各个组对于该实验对象的分配概率。
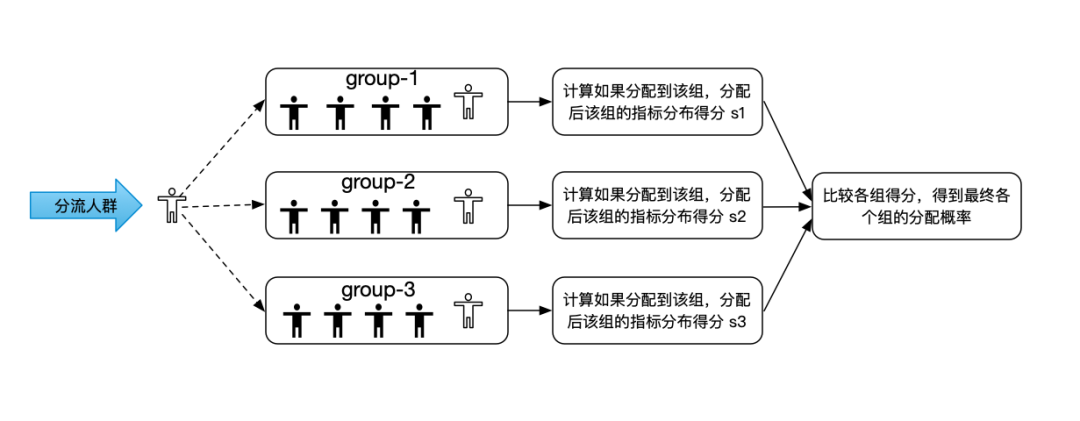
Adaptive分组流程
系统交互流程如下:
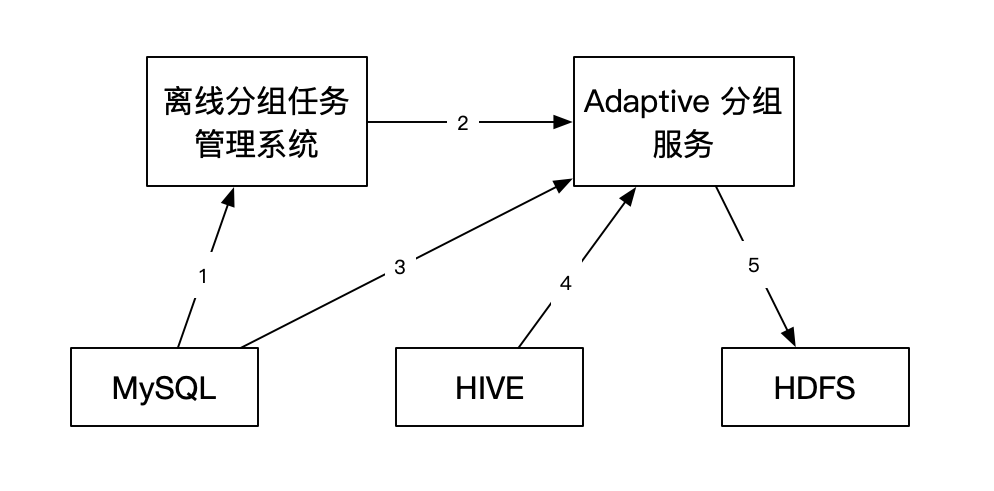
Adaptive分组方案的设计与实现复用了Apollo AB实验已有离线分组架构的能力。用户在实验平台通过API接口或者页面创建完Adaptive实验之后,实验平台会将分组需求发送到分组任务管理系统,生成分组任务存入数据库中。Adaptive分组执行分为以下几个步骤:
首先分组任务管理系统从数据库中获取需要进行分组的任务。然后根据任务类型调用不同的分组服务。Adaptive分组服务从数据库中获取实验对应的计算信息。根据实验计算信息中的观察指标,从HIVE中获取指标数据,根据人群信息的地址获取人群数据。执行完分组算法之后,将分组结果写入HDFS。
算法介绍
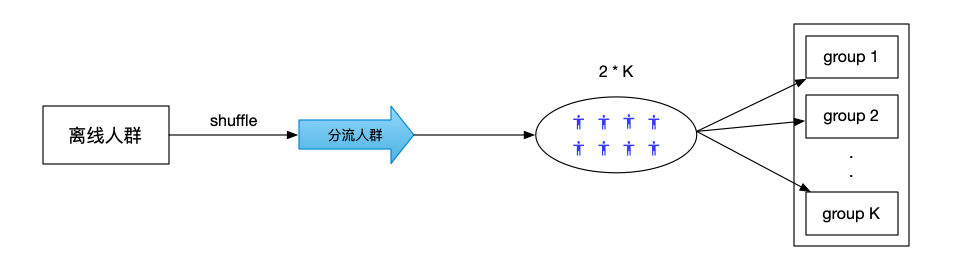
▍样本打乱&随机分配
将人群shuffle打乱之后,对于人群的前2 * K(K是组数)的人进行随机分组,保证每个组中至少有两个样本之后再开始进行Adaptive分组。
6.
使用Adaptive分组之后,1次分组得到符合要求的分组概率超过95%。
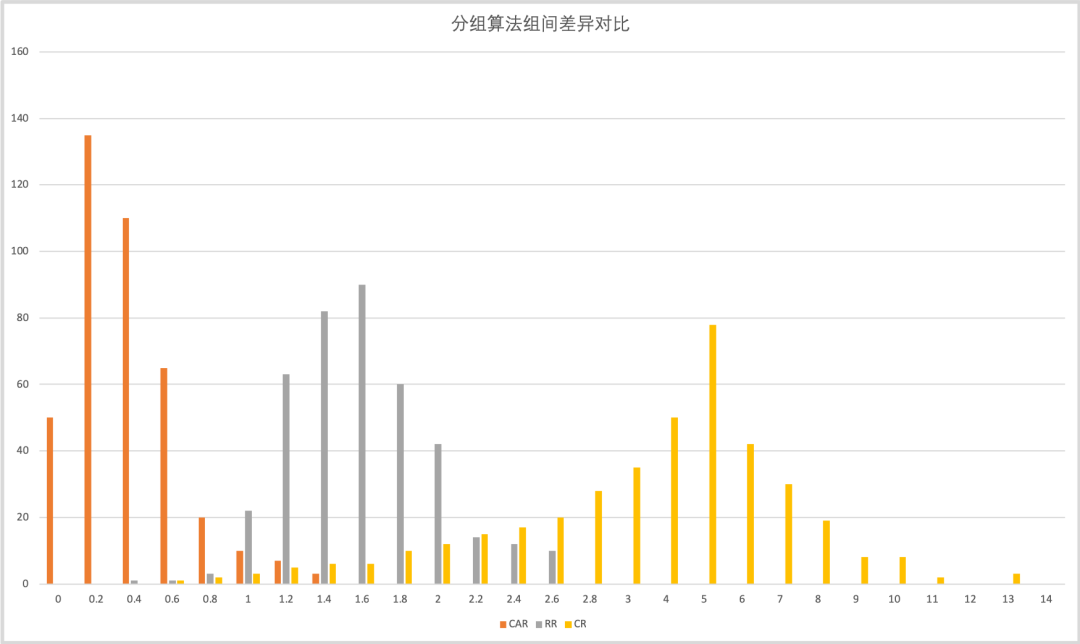
总结
通过提供Adaptive自适应分组能力,我们极大的提高了随机分组实验的数据精度。降低了无效实验的概率,缩短了实验周期。然而,对于已经通过CR方式完成的随机分流实验,用上述的这一套方案已经无法重新均衡。如何从这种已经完成的实验分组中抽取分布平衡的样本进行效果评估是一个更大的挑战,目前正在设计中,欢迎大家在本文留言,提宝贵意见,一起探讨实验相关问题。
今天的分享就到这里,谢谢大家。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
社群推荐:
欢迎加入 DataFunTalk 用户增长 交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:datafun-coco ),逃课儿会自动拉你进群。

团队介绍 ▬
滴滴工程效能团队肩负通过工程技术持续提升组织效能的使命, 致力于建设世界一流的工程能力体系。为工程师提供极致的工作体验,打造高效能研发组织。 作者简介
▬ ![]()
2018年北邮硕士毕业加入滴滴。在工程效能团队Apollo AB实验项目组,从事实验效果评估相关工作,负责实验科学性相关的研究。
福利来了
![]()
用户画像技术及方法论
上线1天,点击破万的热门文章,提供了PDF电子版啦,小伙伴们可以收藏起来慢慢看哦! 识别下方二维码,回复“ 0527 ”,即可获得下载链接。 ![]()
推荐阅读
▬



 福利来了
福利来了 




关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号DataFunTalk累计生产原创文章400+,百万+阅读,5万+精准粉丝。
一个在看,一段时光!👇




