Rethink DL | 激活、损失函数与正则化

Rethink知识整理系列,持续更新

写在前面
在上一篇文章中我们介绍了 DNN 的基本结构,以及使用 BP(Backpropagation)求解 的说明,并简单介绍了在 DNN 中可以使用 Mini-batch GD(Stochastic Gradient Descent)来获得更好的结果。这几个方面算是 DNN 的基础,也即较为固定的。同时,还有其他一些方面,随着对 Deep Learning 认识、试错的增加,有过一些改变或发展,而且以后可能还会继续演进。接下来会从几个方面进行具体介绍:Activation Function、Cost Function、Optimization、Dropout 等。
Activation Function
Sigmoid
最开始接触 ANN 的时候,大家听说的 Activation Function 应该还都是 Sigmoid 函数。它的定义如下:
其图形如下
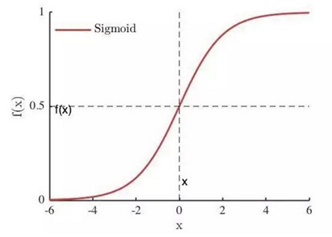
Sigmoid 函数优点很多:
-
作为 Activation Function,它是单调递增的,能够很好地描述被激活的程度 -
Sigmoid 能将 转换为 ,避免数据在传递过程中太过发散,同时输出还能被理解成某种概率 -
Sigmoid 在定义域内处处可导,而且导数很好算。 ,图形如下,可以看出
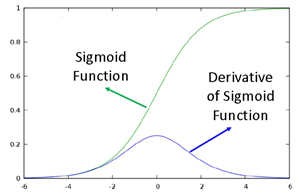
但是,Sigmoid 的导数也带来了一些问题。在上一部分我们介绍过如何通过 BP 来计算 ,如下
假设 为 Sigmoid 函数,有 。因此随着 的减小, 会越来越小,从而 也会越来越小。当 DNN 比较深的时,较前层的参数求出的梯度会非常小,几乎不会再更新,这种现象被称为 Gradient Vanish。
ReLU
为了缓解 Gradient Vanish 现象,现在大家都会使用 ReLU(Rectified Linear Unit),其定义如下
对应的图形如下
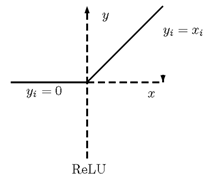
ReLU除了具有Sigmoid函数大部分的优点外,还有
-
对某个神经元,当 时,其导数为1,因而缓解了Gradient Vanish现象。因此,ReLU也是最近几年非常受欢迎的激活函数 -
对某个神经元,当 时,其输出也是0,也就是对后续的网络不起作用,可以看作从网络中被移除了。因此在整个训练过程结束后,整个网络会呈现出一种稀疏的状态,也就是会有很多的神经元由于在网络中不起作用,可以当成不存在。这种稀疏也表明ReLU对避免网络过拟合有一定作用。
同时,ReLU也有自己的缺陷:
-
可以看出当 时,不仅输出为0,ReLU的导数也为0。即对应的参数不再更新。因此这个神经元再也没有被激活的机会了,这种现象被称为dying ReLU -
第二个现象叫Bias shift。在将数据输入DNN时我们一般会进行高斯归一,但是由于ReLU的输出恒大于0,会导致后续层输出的数据分布发生偏移。对于很深的网络,这可能会导致无法收敛。
LReLU、PReLU
为了解决dying ReLU的问题,有学者提出了LReLU(Leaky Rectified Linear Unit)、PReLU(Prametric Rectified Linear Unit)。它们被定义为
对应的图形如下
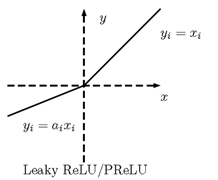
LReLU 可以避免 dying ReLU,使神经元在任何输入下都能持续更新参数。对于 LReLU, 是需要我们提前设定好的较小的数,比如 0.01。但是,提前设定 也带来了调参的难度。为了解决难以选择合适参数的问题,出现了 PReLU。
PReLU 公式跟 LReLU 是一样的,不同的是 PReLU 的 是通过训练样本自动学习的。学习的方式依然是 BP 算法。但是,PReLU 在小数据下容易过拟合。具体的步骤可以参考"He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Delving deep into rectiers: Surpassing human-level performance on imagenet classication.2015."
RReLU
RReLU(Randomized Rectified Linear Unit)是 LReLU 的随机版本。它最早出现在Kaggle NDSB[1]比赛中,定义如下
其中
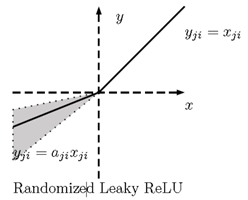
在训练时, 是一个保持在 内均匀分布的随机变量,而在测试中被固定为 。关于 RReLU 并没有太多的文章,想进一步了解的话可以参考“Xu B, Wang N, Chen T, et al. Empirical Evaluation of Rectified Activations in Convolutional Network. 2015.”
Others
Activation Function 是一个比较发散的课题,在不同的任务中有不同的选择,暂时先不做更多的介绍。其它的 Activation Function 比如 Maxou、ELU 等,有兴趣的同学可以自己查找相关资料。
Cost Function
Softmax + Cross Entropy
在 DNN 中进行多类分类时,使用的最多的 Cost Function 就是 Cross Entropy Loss,这里我们也主要介绍它。
首先,对于两个分布 与 ,交叉熵的定义为:
交叉熵用于衡量两个分布的相似性。当 与 的分布完全一致时, 最小。
对于分类问题,假设进行 类分类,我们将某个样本 的真实的类别标记 用向量 描述,其中
于是, 可以被理解为 为第 类的概率。因此,DNN的输出 应该也是一个向量 ,且需要与 尽可能的接近。为了描述这两个分布的相似性,于是就引入了Cross Entropy Loss,其定义如下:
对于两类分类, , 可以简化为:
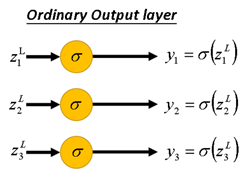
还有一点需要注意,在上一章介绍 DNN 时,我们假设了 Output Layer 中从
的变换是普通的 Activation Function,即
函数,如图
但是在多类分类时, 表示的样本属于第 类的概率。此时将 转换为 的操作即 Sotfmax,其公式如下
用图像来表述,如下
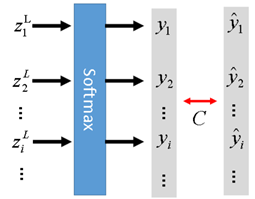
其实使用 Cross Entropy Loss 作为损失函数不是 DNN 的专属,GBDT 在进行多类分类的时候就是使用的 Softmax + Cross Entropy,只是当时它被称为对数损失函数(Log-Likehood Loss)。有兴趣的同学可以回去看看那个部分。
最后需要说明的是,当我们使用 MSE(均方误差)作为 Cost Function ,会导致 的更新速度依赖于 Activation Function 的导数,在 Activation Function 为 Sigmoid 函数时很容易更新缓慢;而使用 Softmax + Cross Entropy Loss,能够有效克服这个问题。这也是 Cross Entropy Loss 在分类问题中使用较多的原因之一。这里先不展开介绍了,以后有机会再补充。
Regularization 与 Weight Decay
上面讲完 Cost Function,按照套路,这个时候就要开始预防过拟合了,这里我们再讲一下 Regularization 相关。
Weight Decay
假设我们使用的是 L2 Regularization,则对应的公式如下:
其中, ,即所有 的集合,注意这里只考虑了 没有考虑 (原因似乎是因为实验表明 的约束对结果并没有太大的提升,不过暂时还没找到出处,以后看到再补充); ,即所有 的平方和; 用于控制 Regularization 的程度,也叫 Weight Decay,越大则模型越倾向于简单。
在用 BP 更新参数时,有
于是在更新 时,更新式为
可以看出,更新式比没有 Weight Decay 多了 这一项;且由于它小于 1, 会在进行梯度下降的同时会被持续减小,这也是 Weight Decay 这个名称的由来。
Regularization 的理解
既然谈到了 Regularization,顺带谈一个经常被提及的问题——Regularization 的解释,即它到底是为什么会带来正则化的效果的。
「第一种,是从
中看到的」
对于 L1、L2 Regularization,他们的 Cost Function 分别可以写作
于是,我们可以写出它们的等价形式,如下
可以看出,我们其实是通过 L1 或 L2 约束将 限制在一个空间中,在此基础上求出使 Cost Function 最小的 。
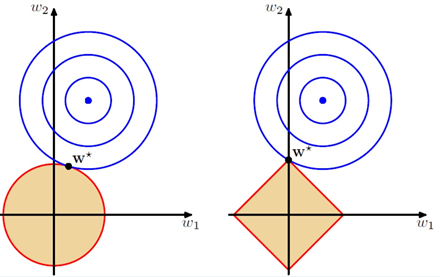
假设现在考虑
有两维,如下图。其中黄色区域分别是 L2 和 L1 约束,蓝色是 Cost Function 的等高线。蓝色与红色的切点即求出的
,可以看出对于 L1 约束,
更容易出现在坐标轴上,即只有一个维度上有非 0 值;而对于 L2 约束,则可能出现在象限的任何位置。这也是 L1 正则会带来稀疏解的解释之一。
「第二种,是从概率的角度」
假设给定观察数据为
,贝叶斯方法通过最大化后验概率估计参数
,即
其中, 是似然函数, 是参数的先验。
当 服从 维 0 均值高斯分布,即
代入上式,有
其中,第一项就是我们平时所定义的 Cost Function;第二项就是 L2 正则项;第三项当给定了 那么就是常数了。所以我们可以看出,L2 正则本质其实是给模型参数 添加了一个协方差为 的零均值高斯分布先验。而 越小,则协方差 越大,表明先验对 的约束越弱,模型的 variance 越大;反之,而 越大,则协方差 越小,表明先验对 的约束越强,模型越稳定。这与我们平时的理解是吻合的。
当 服从 维 0 均值同分布 Laplace 分布时,即
代入上式,有
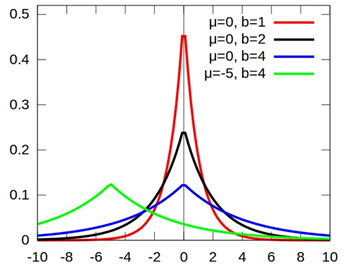
同样,第一项就是我们平时所定义的 Cost Function;第二项就是 L1 正则项;第三项当给定了 那么就是常数了。一维 Laplace 分布如下:
其概率密度如下图所示,可以看出它取值的特点是很大概率落在一个小范围内。当
时,它会以很大概率取值在 0 的附近,这也就是 L1 约束会出现稀疏解的原因。
尾巴
在梳理 DNN 相关知识时,感觉现阶段 DNN 相关的信息有一些特点:首先是涉及到的知识很广泛,却都比较零碎;其次,DNN 中对于参数的解释更多地需要意会,理论上能解释的特别好的并不太多。这种特点某种程度上也体现在了这篇文章中,可能也会体现在整个 DNN 系列中。同时,由于事情较多,每日写 BLOG 时间很有限,如果文章有什么错误或者建议,也欢迎指出。
本文参考资料
Kaggle NDSB: https://link.zhihu.com/?target=https%3A//www.kaggle.com/c/datasciencebowl
- END -

推荐阅读
超赞!百度词法分析工具 LAC 全面升级,2.0 版在线极速体验
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇

