CVPR 2020 |商汤团队提出应对尺度变化的检测新算法
【导读】在CVPR 2020上,为了更好的解决物体检测中的尺度问题,商汤EIG算法中台团队重新设计了经典的单阶段检测器的FPN【1】以及HEAD结构,通过构造更具等变性的特征金子塔,以提高检测器应对尺度变化的鲁棒性,可以使单阶段检测器在coco上提升~4mAP,完整代码已开源。

动机
文章提出了一个针对物体具有大尺度变化数据集的检测算法。工作的研究动机在于:
-
当前所有基于 RetinaNet 的单阶段检测器,都采用了共享权重的分类 HEAD 以及回归 HEAD 在特征金字塔上滑动从而检测不同大小的物体,相应的最为适应这种结构的特征金子塔对于尺度变化应当具有等变性。 -
经典的底层特征提取算法如 SIFT,其高斯金字塔具有很好的尺度等变性,我们思考了深度神经网络中特征金字塔与高斯金字塔的区别,从而提出了提高其等变性的算法。
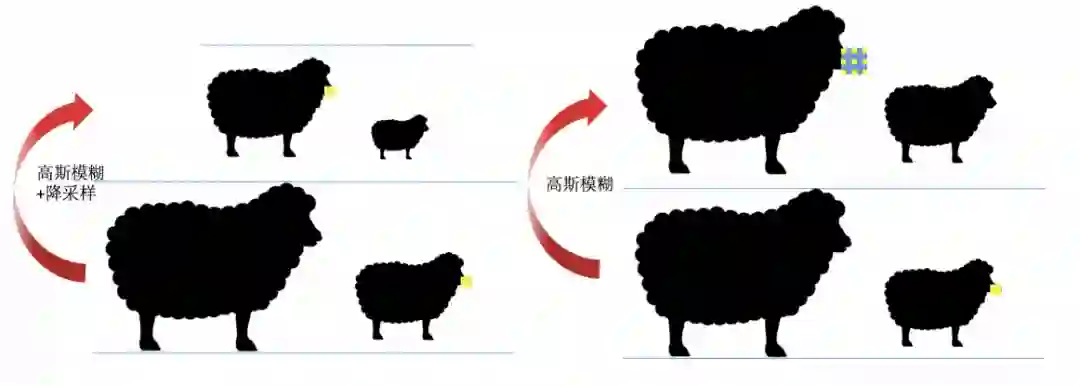 图2(左):对羊嘴边缘具有高相应的特征提取算子;图3(右):带 dilation 的羊嘴边缘提取算子
图2(左):对羊嘴边缘具有高相应的特征提取算子;图3(右):带 dilation 的羊嘴边缘提取算子
-
如图 2,可以用一个高斯卷积核去除高频后降采样一次,使得大羊的羊嘴特征跟小羊在同一尺度,从而在降采样的图上进行大羊羊嘴的检测。 -
如图 3,可以用一个高斯卷积核去除高频后,将特征提取算子变为变为空洞卷积,亦可以进行大羊的羊嘴检测。
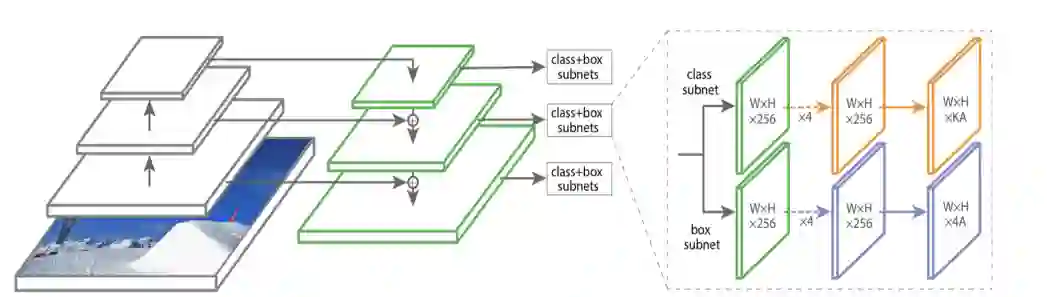
回想单阶段检测器(如RetinaNet),
分析
-
相比于图像处理中 low level 的特征,深度神经网络提取的特征往往经过足够多基础特征的组合,其特征往往有更为复杂的高级语义,并且由于我们用相同的 backbone 进行特征的提取不同尺度的物体的特征会有相互竞争的现象。 -
深度神经网络中,因为足够多的卷积与非线性激活单元,其不同 stage 感受野的变化在特征图的不同位置具有不一致的现象,使得金子塔的两层间很难有高斯金字塔一样,不同大小物体的特征在 downsample 一次,或者增大特征提取算子的 dilation 这样的处理后具有一致性。
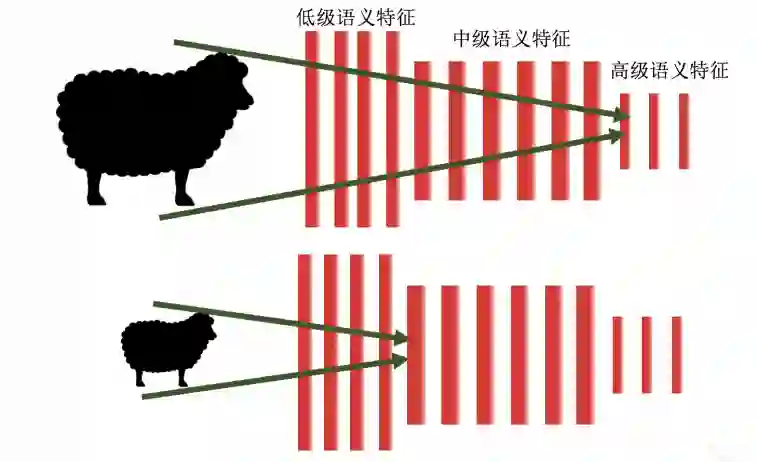
物体检测中,我们需要特征图同时具有较高的语义信息完成分类,又需要较好的保留原图信息用于定位,单一尺度的物体,在 backbone 中的不同 stage 可以提取出不同级别的语义,但是在处理另一尺度的物体时,则会出现不匹配的现象,如小物体用到的特征提取算子可能只是大物体提取低级特征算子,从而很难提取高级语义进行分类,这也启发了后来的 FPN 的 Top-down 结构,以及后续的一系列 feature fusing 的结构。
网络设计
如何改进特征金子塔使其具有更好的等变性质呢?
我们发现,在特征金子塔的某一层为基准,其与上下两层间具有更好的相关性,直觉上可以推测其底部一层往往保留有更多的定位相关的信息,更高层往往具有更好的分类相关的信息,而以往的 feature fusing 的方法都遗漏了这种空间尺度(特征金子塔层间)的相关性。
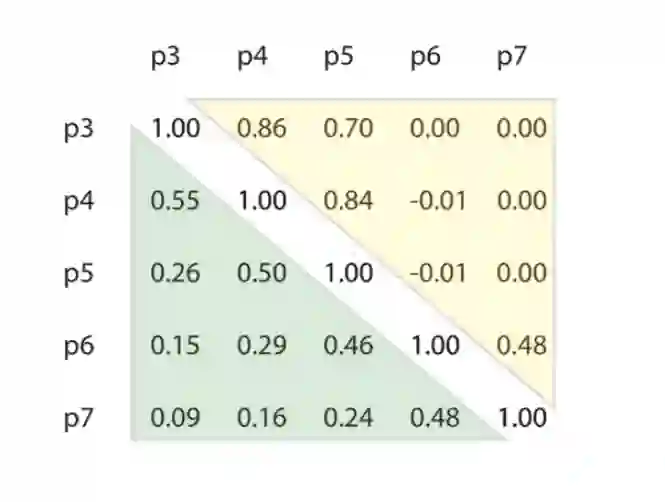
无论是形式上的分析还是实验发现的这种相关性暗示我们尺度空间上确实有值得提取的特征,我们希望通过在尺度空间上进行卷积来提取这种特征。
考虑到 FPN 的不同层的分辨率不同,我们由此提出金字塔卷积(Pconv)的结构。
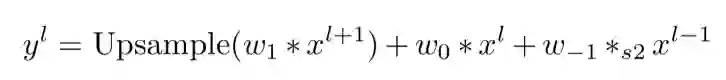
特征金字塔相邻三层(P3,P4,P5)举例,在 P3 上利用 stride 为 2 的 conv 进行卷积,在 P4 上利用普通 conv 卷积,P5 上普通 conv 卷积然后 upsample,得到相同大小的特征图然后相加,不难推导,其等效于在特征图上每一点在 HW 维度卷积后再在尺度空间(P3,P4,P5)进行一次卷积,因此其相当于一个 3-D 的卷积核。
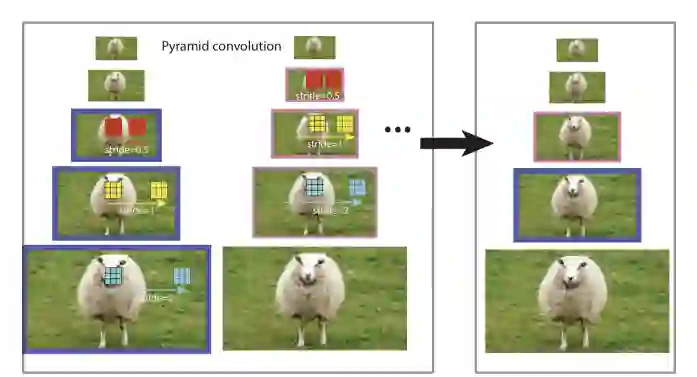 图 7 尺度空间卷积(Pconv) 示意图
图 7 尺度空间卷积(Pconv) 示意图
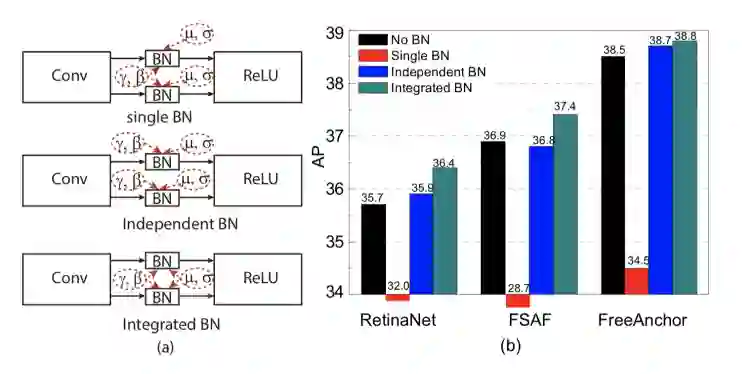 图 8 iBN 示意图
图 8 iBN 示意图
另一方面,高斯金子塔中特征相邻层降采样时有其相匹配的高斯模糊核,太大的模糊核会去除过多有用信息,太小的模糊核引入高频噪声。但是特征金字塔中相邻层之间间隔不同的卷积核与大量的非线性单元,这使得特征图上不同位置相邻层之间没有一个固定的理论高斯模糊核。因此我们由此基于以上提出的 Pconv 又将其改进为尺度等化的尺度空间卷积(SEPC)模块:当尺度空间卷积核在尺度空间上滑动时,最底层上用普通的 3X3 卷积,当相同的卷积核滑向高层特征图时用可变形卷积(Dconv)【3】实现像在高斯金字塔中一样的高层特征点与最底层的对齐。同时这个设计中可变形卷积只在高层特征图上采用,其引入的额外的 Dconv 的计算量开销以及推理速度损失其实是很小的。
 图 9 SEPC 示意图
图 9 SEPC 示意图
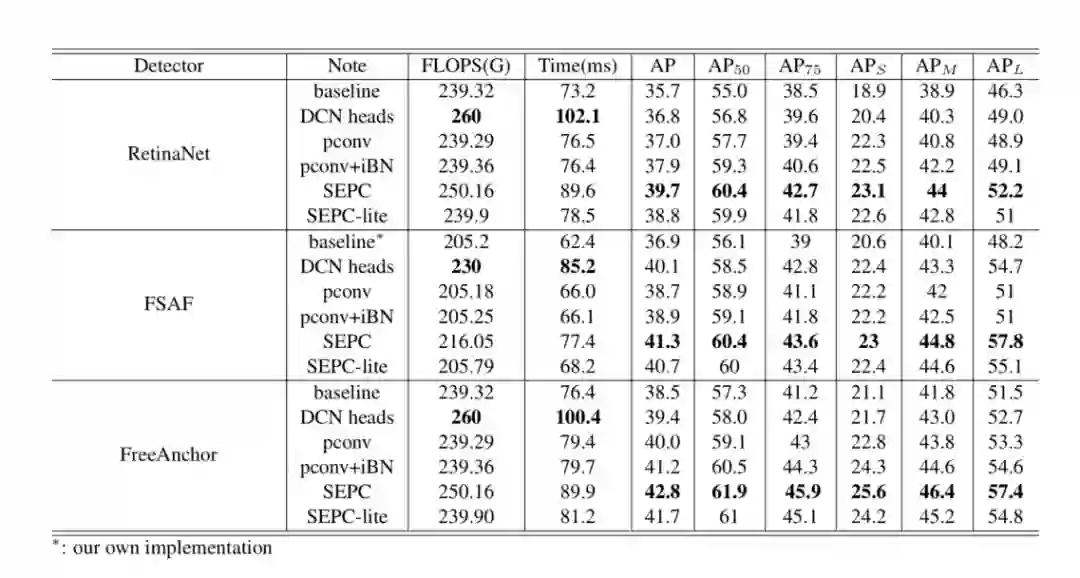
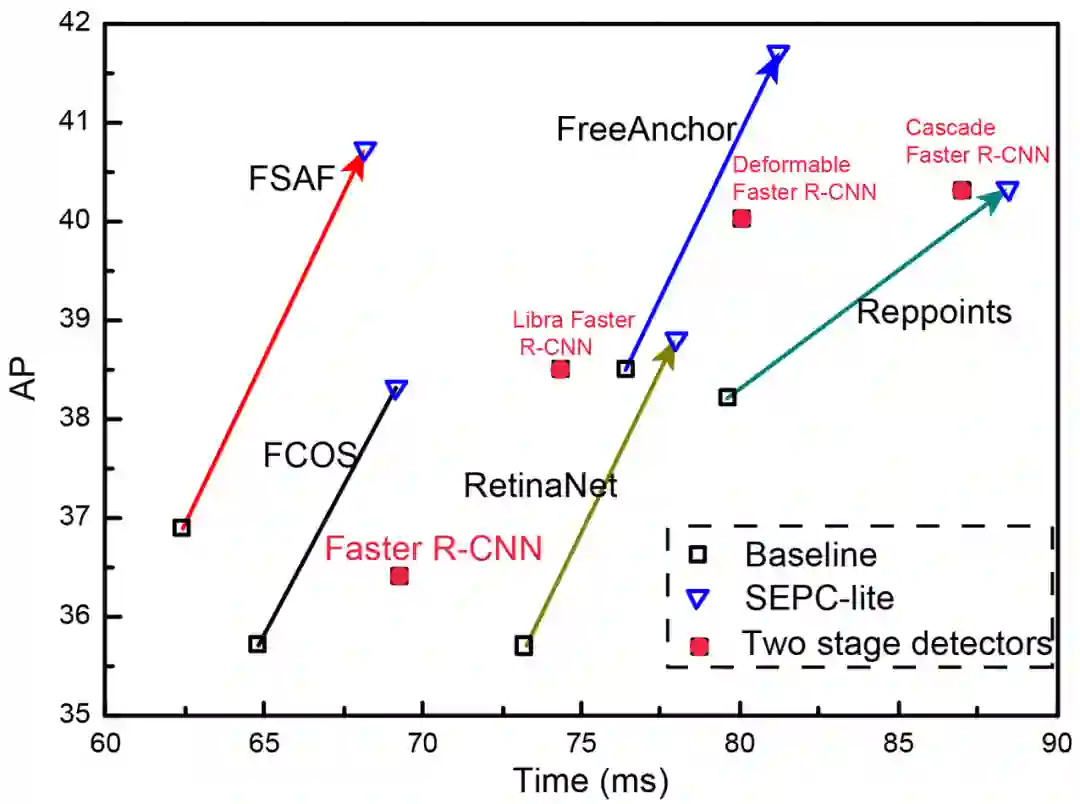
可以看到,我们提出的模块在三个 model 上均有稳定的提升,并且性能提升相比 flops 与 forward 速度的增加极具性价比,值得注意的是,虽然我们使用了 Dconv,但是性能的提升不仅仅是 Dconv 带来的,相比 head 结构全部更换为 Dconv,我们的 SEPC 在速度与性能上都体现出了绝对的优势。
同时我们选取了 FreeAnchor 为基础与当前 SOTA 检测器进行了比较。
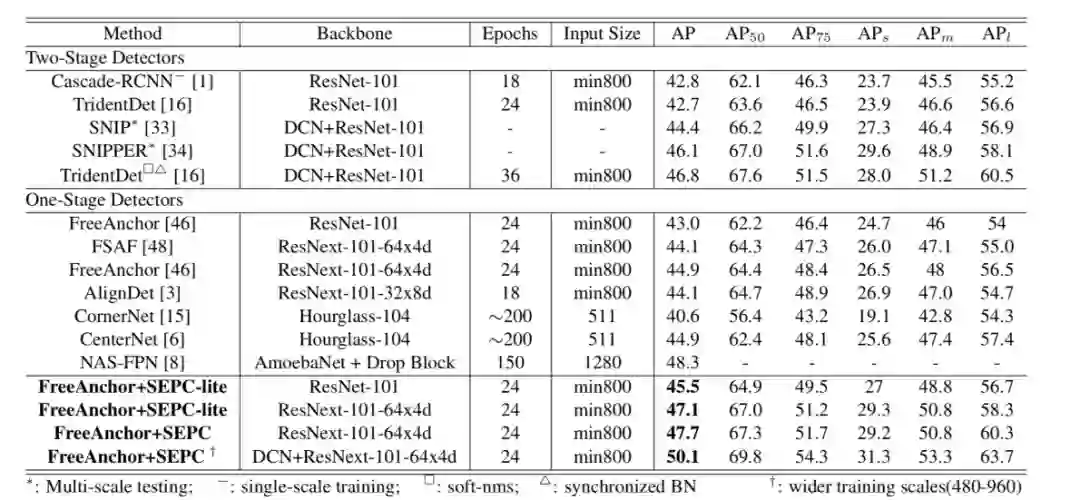
我们 SEPC 在 mAP45 左右的 baseline 上依然有接近 3mAP 的提升,我们在甚至在单尺度测试的条件下得到了一个 mAP 为 50.1 的单阶段检测器。
传送门
代码目前也已经开源,欢迎各位同学使用和交流。
论文地址: https://arxiv.org/pdf/2005.03101.pdf
代码地址: https://github.com/jshilong/SEPC
参考文献:
[1] Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
[2]Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In CVPR, 2019.
[3] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In ICCV, 2017.
[4] Chenchen Zhu, Yihui He, and Marios Savvides. Feature selective anchor-free module for single-shot object detection. In CVPR, 2019.
[5] Xiaosong Zhang, Fang Wan, Chang Liu, Rongrong Ji, and Qixiang Ye. FreeAnchor: Learning to match anchors for visual object detection. In NIPS, 2019.









点击阅读原文,查看更多精彩!