公平与精确同样重要!CMU提出学习公平表征方法,实现算法公平

作者 | 赵晗
编译 | Mr Bear
编辑 | 丛末
所有方法的共同之处在于,为了降低依赖性,在一定程度上必须牺牲准确性。
——Calders et al
「Building Classifiers with Independency Constraints」
在人工智能发展的初期,人们对算法的要求往往停留于「准」的层面,预测结果越精确似乎越好。然而,随着人工智能技术逐渐融入日常生活,人们对于算法「公平性」的要求与日俱增。在本文中,来自 CMU (卡内基 · 梅隆大学)的研究人员赵晗提出了一种通过学习公平表征来实现算法公平的方法。(相关论文发表在ICLR 2020上)
第一个概念是「个体公平」。简而言之,它要求公平的算法以类似的方式对待相似的个体。然而,在实践中,通常很难找到或设计一种被社会所认可的距离度量标准,该标准用于衡量个体在面对特定任务时的相似度。
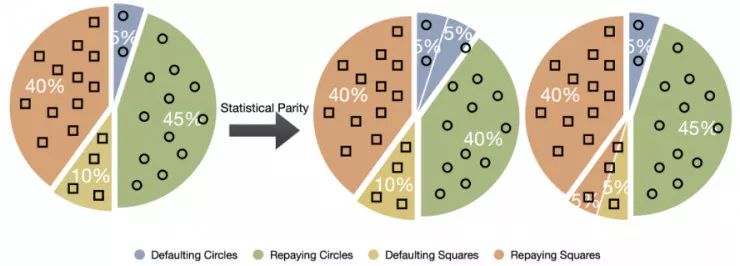
第二个概念是「群体公平」,这是本文重点讨论的问题。更具体地说,就是所谓的统计均等,它本质上是要求预测器对于不同子群输出的结果相同。
举例而言,我们不妨考虑一下下面的贷款核准问题。假如这个虚拟设定的环境中有通过圆形和方形代表的两组贷款申请人。
自动贷款核准系统 C 的目标是预测:如果某位贷款申请人被批准放贷,在给定对于申请人的描述信息 X 时,他是否会按期还款,C(x)=1 代表会按期还款,C(x)=0 代表不会按期还款。
一、学习公平的表征
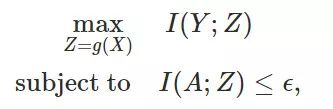
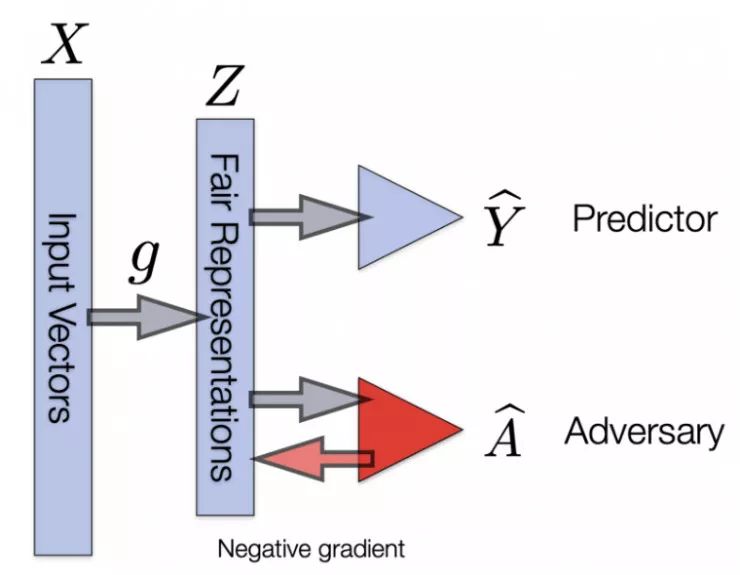
二、公平性和效用间的权衡
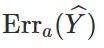 为由群体属性为
为由群体属性为
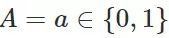 的
的
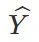 产生的 0-1 二分类误差。我们定义:
产生的 0-1 二分类误差。我们定义:
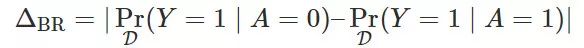 ,
,
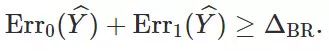
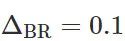 。请注意,上述两种公平分类器针对圆形申请者和方形申请者的的误差率都为 0.1。
。请注意,上述两种公平分类器针对圆形申请者和方形申请者的的误差率都为 0.1。
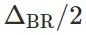 的误差率。此外,该结论是预算法无关的,它在群体层面上成立(即使用大的训练集并不能有所帮助)。接下来,让我们深入分析
的误差率。此外,该结论是预算法无关的,它在群体层面上成立(即使用大的训练集并不能有所帮助)。接下来,让我们深入分析
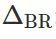 这个量:
这个量:
如果 A⊥Y,那么Pr(Y=1 | A=0) = Pr(Y=1 | A=1),这意味着
。也就是说,如果群体属性与目标无关,那么上述下界为 0,因此此时不存在效用和公平性的权衡。
如果基于可以确定 A=Y 或 A=1-Y,那么
将取到其最大值 1。在这种情况下,任何公平分类器都必然会在至少一个群体上产生至少为 0.5 的误差。
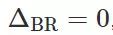 取介于 0 和 1 之间的值,正是这个值表示了在二分类情况下对于公平性和效用的权衡。
取介于 0 和 1 之间的值,正是这个值表示了在二分类情况下对于公平性和效用的权衡。
三、公平表征学习的权衡
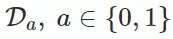 为给定 A=a 时的条件分布 D。对于特征转换函数
为给定 A=a 时的条件分布 D。对于特征转换函数
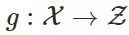 来说,令
来说,令
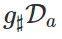 为 Da 在使用 g 转换后的前推分布(Pushforward Distribution)。此外,如果我们使用
为 Da 在使用 g 转换后的前推分布(Pushforward Distribution)。此外,如果我们使用
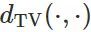 代表两个概率分布之间的总变分距离,那么下面的定理成立:
为一种特征变换。对于任意(随机的)假设
代表两个概率分布之间的总变分距离,那么下面的定理成立:
为一种特征变换。对于任意(随机的)假设
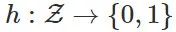 ,令
,令
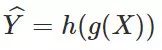 为一种预测器,则下面的不等式成立:
为一种预测器,则下面的不等式成立:
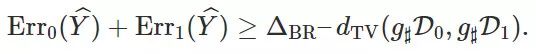
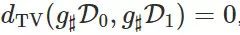 时,定理 2 退化到了定理 1 中的下界。
时,定理 2 退化到了定理 1 中的下界。
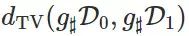 越小,则下界越大。因此,当
较大时,针对不同群体的表征对齐地越好,则不同群体上的误差之和也会越大。
越小,则下界越大。因此,当
较大时,针对不同群体的表征对齐地越好,则不同群体上的误差之和也会越大。
四、实际情况如何?
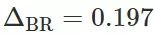 ,即在 1994 年男性年收入大于 50,000 的比率比女性高 19.7%。
,即在 1994 年男性年收入大于 50,000 的比率比女性高 19.7%。
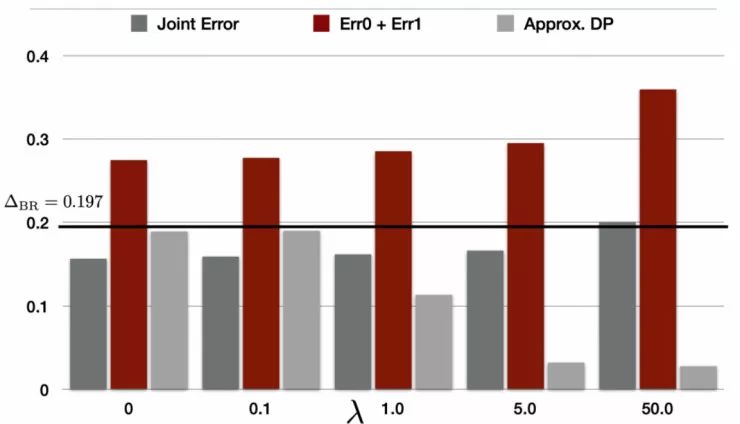
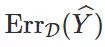 ),它是在成人数据集上的整体误差。第二个红色的竖条代表群体间误差率之和,这正是在我们的定理 1 和定理 2 中都出现了的下界。第三个灰色竖条对应于衡量
满足统计均等的程度的差异得分(gap score)。具体而言,灰色的竖条代表的是:
),它是在成人数据集上的整体误差。第二个红色的竖条代表群体间误差率之和,这正是在我们的定理 1 和定理 2 中都出现了的下界。第三个灰色竖条对应于衡量
满足统计均等的程度的差异得分(gap score)。具体而言,灰色的竖条代表的是:
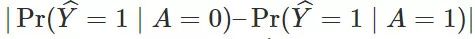 。简而言之,这个差异得分越小,预测器
越满足统计均等。
已经非常接近于满足统计均等。另一方面,我们也可以观察到,随着 λ 的增大,红色的竖条也迅速增大,最终群体间误差之和达到了大于 0.36 的水平。
,所有的红色薯条都超过了这个水平线,这与我们的理论分析结果是一致的。实际上,
是非常容易计算的,它可以在不实际训练公平分类器的情况下,限制它们所产生的误差之和。
。简而言之,这个差异得分越小,预测器
越满足统计均等。
已经非常接近于满足统计均等。另一方面,我们也可以观察到,随着 λ 的增大,红色的竖条也迅速增大,最终群体间误差之和达到了大于 0.36 的水平。
,所有的红色薯条都超过了这个水平线,这与我们的理论分析结果是一致的。实际上,
是非常容易计算的,它可以在不实际训练公平分类器的情况下,限制它们所产生的误差之和。
五、结语





