教程 | 理解XGBoost机器学习模型的决策过程
选自Ancestry
作者:Tyler Folkman
机器之心编译
参与:刘晓坤、李泽南
使用 XGBoost 的算法在 Kaggle 和其它数据科学竞赛中经常可以获得好成绩,因此受到了人们的欢迎(可参阅:为什么 XGBoost 在机器学习竞赛中表现如此卓越?)。本文用一个具体的数据集分析了 XGBoost 机器学习模型的预测过程,通过使用可视化手段展示结果,我们可以更好地理解模型的预测过程。
随着机器学习的产业应用不断发展,理解、解释和定义机器学习模型的工作原理似乎已成日益明显的趋势。对于非深度学习类型的机器学习分类问题,XGBoost 是最流行的库。由于 XGBoost 可以很好地扩展到大型数据集中,并支持多种语言,它在商业化环境中特别有用。例如,使用 XGBoost 可以很容易地在 Python 中训练模型,并把模型部署到 Java 产品环境中。
虽然 XGBoost 可以达到很高的准确率,但对于 XGBoost 如何进行决策而达到如此高的准确率的过程,还是不够透明。当直接将结果移交给客户的时候,这种不透明可能是很严重的缺陷。理解事情发生的原因是很有用的。那些转向应用机器学习理解数据的公司,同样需要理解来自模型的预测。这一点变得越来越重要。例如,谁也不希望信贷机构使用机器学习模型预测用户的信誉,却无法解释做出这些预测的过程。
另一个例子是,如果我们的机器学习模型说,一个婚姻档案和一个出生档案是和同一个人相关的(档案关联任务),但档案上的日期暗示这桩婚姻的双方分别是一个很老的人和一个很年轻的人,我们可能会质疑为什么模型会将它们关联起来。在诸如这样的例子中,理解模型做出这样的预测的原因是非常有价值的。其结果可能是模型考虑了名字和位置的独特性,并做出了正确的预测。但也可能是模型的特征并没有正确考虑档案上的年龄差距。在这个案例中,对模型预测的理解可以帮助我们寻找提升模型性能的方法。
在这篇文章中,我们将介绍一些技术以更好地理解 XGBoost 的预测过程。这允许我们在利用 gradient boosting 的威力的同时,仍然能理解模型的决策过程。
为了解释这些技术,我们将使用 Titanic 数据集。该数据集有每个泰坦尼克号乘客的信息(包括乘客是否生还)。我们的目标是预测一个乘客是否生还,并且理解做出该预测的过程。即使是使用这些数据,我们也能看到理解模型决策的重要性。想象一下,假如我们有一个关于最近发生的船难的乘客数据集。建立这样的预测模型的目的实际上并不在于预测结果本身,但理解预测过程可以帮助我们学习如何最大化意外中的生还者。
import pandas as pd
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import operator
import matplotlib.pyplot as plt
import seaborn as sns
import lime.lime_tabular
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import Imputer
import numpy as np
from sklearn.grid_search import GridSearchCV
%matplotlib inline
我们要做的首件事是观察我们的数据,你可以在 Kaggle 上找到(https://www.kaggle.com/c/titanic/data)这个数据集。拿到数据集之后,我们会对数据进行简单的清理。即:
清除名字和乘客 ID
把分类变量转化为虚拟变量
用中位数填充和去除数据
这些清洗技巧非常简单,本文的目标不是讨论数据清洗,而是解释 XGBoost,因此这些都是快速、合理的清洗以使模型获得训练。
data = pd.read_csv("./data/titantic/train.csv")
y = data.Survived
X = data.drop(["Survived", "Name", "PassengerId"], 1)
X = pd.get_dummies(X)
现在让我们将数据集分为训练集和测试集。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
并通过少量的超参数测试构建一个训练管道。
pipeline = Pipeline([('imputer', Imputer(strategy='median')), ('model', XGBClassifier())])
parameters = dict(model__max_depth=[3, 5, 7],
model__learning_rate=[.01, .1],
model__n_estimators=[100, 500])
cv = GridSearchCV(pipeline, param_grid=parameters)
cv.fit(X_train, y_train)
接着查看测试结果。为简单起见,我们将会使用与 Kaggle 相同的指标:准确率。
test_predictions = cv.predict(X_test)
print("Test Accuracy: {}".format(accuracy_score(y_test, test_predictions)))
Test Accuracy: 0.8101694915254237
至此我们得到了一个还不错的准确率,在 Kaggle 的大约 9000 个竞争者中排到了前 500 名。因此我们还有进一步提升的空间,但在此将作为留给读者的练习。
我们继续关于理解模型学习到什么的讨论。常用的方法是使用 XGBoost 提供的特征重要性(feature importance)。特征重要性的级别越高,表示该特征对改善模型预测的贡献越大。接下来我们将使用重要性参数对特征进行分级,并比较相对重要性。
fi = list(zip(X.columns, cv.best_estimator_.named_steps['model'].feature_importances_))
fi.sort(key = operator.itemgetter(1), reverse=True)
top_10 = fi[:10]
x = [x[0] for x in top_10]
y = [x[1] for x in top_10]
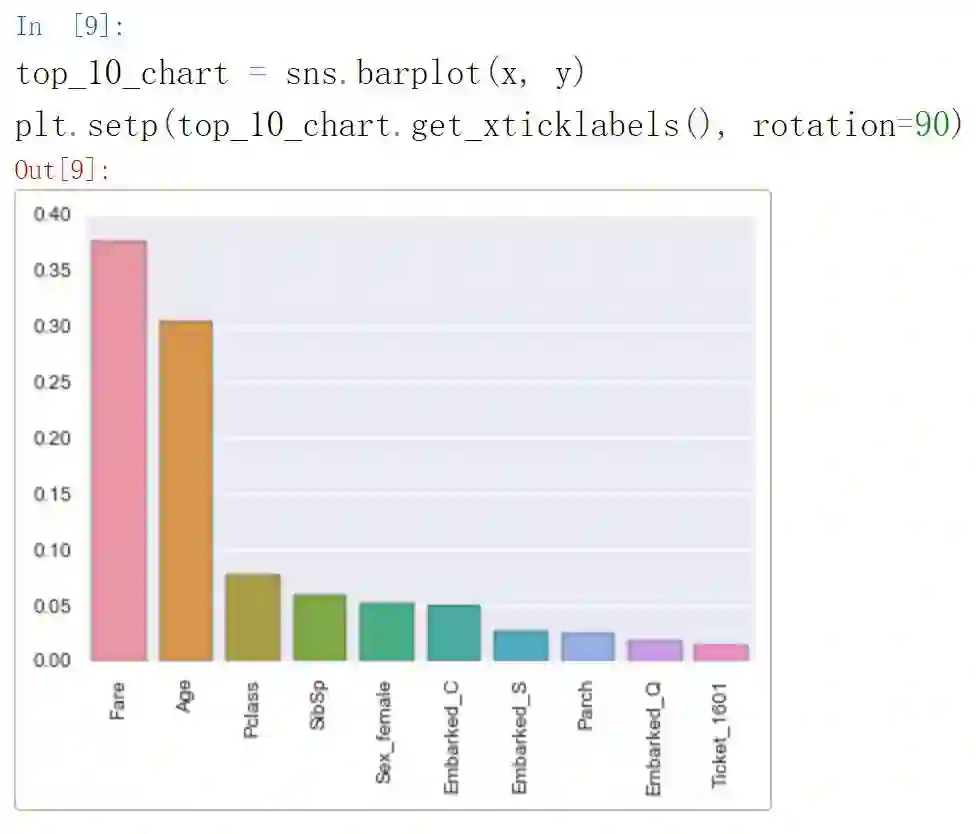
从上图可以看出,票价和年龄是很重要的特征。我们可以进一步查看生还/遇难与票价的相关分布:
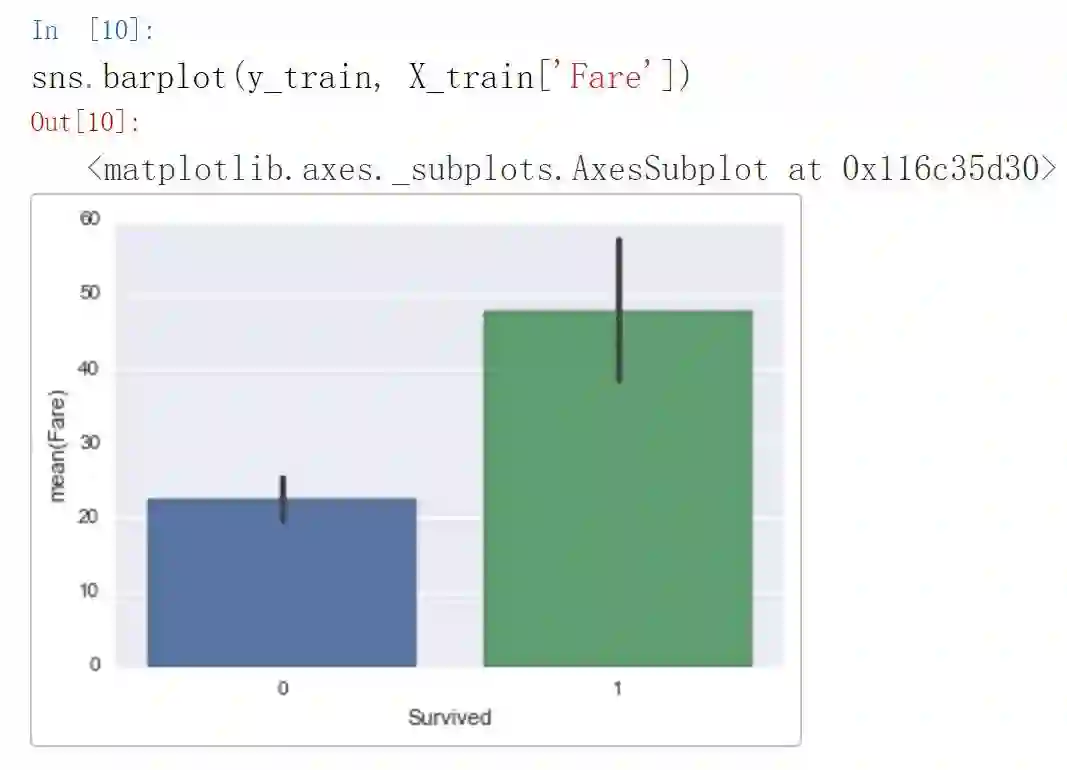
我们可以很清楚地看到,那些生还者相比遇难者的平均票价要高得多,因此把票价当成重要特征可能是合理的。
特征重要性可能是理解一般的特征重要性的不错方法。假如出现了这样的特例,即模型预测一个高票价的乘客无法获得生还,则我们可以得出高票价并不必然导致生还,接下来我们将分析可能导致模型得出该乘客无法生还的其它特征。
这种个体层次上的分析对于生产式机器学习系统可能非常有用。考虑其它例子,使用模型预测是否可以某人一项贷款。我们知道信用评分将是模型的一个很重要的特征,但是却出现了一个拥有高信用评分却被模型拒绝的客户,这时我们将如何向客户做出解释?又该如何向管理者解释?
幸运的是,近期出现了华盛顿大学关于解释任意分类器的预测过程的研究。他们的方法称为 LIME,已经在 GitHub 上开源(https://github.com/marcotcr/lime)。本文不打算对此展开讨论,可以参见论文(https://arxiv.org/pdf/1602.04938.pdf)
接下来我们尝试在模型中应用 LIME。基本上,首先需要定义一个处理训练数据的解释器(我们需要确保传递给解释器的估算训练数据集正是将要训练的数据集):
X_train_imputed = cv.best_estimator_.named_steps['imputer'].transform(X_train)
explainer = lime.lime_tabular.LimeTabularExplainer(X_train_imputed,
feature_names=X_train.columns.tolist(),
class_names=["Not Survived", "Survived"],
discretize_continuous=True)
随后你必须定义一个函数,它以特征数组为变量,并返回一个数组和每个类的概率:
model = cv.best_estimator_.named_steps['model']
def xgb_prediction(X_array_in):
if len(X_array_in.shape) < 2:
X_array_in = np.expand_dims(X_array_in, 0)
return model.predict_proba(X_array_in)
最后,我们传递一个示例,让解释器使用你的函数输出特征数和标签:
X_test_imputed = cv.best_estimator_.named_steps['imputer'].transform(X_test)
exp = explainer.explain_instance(X_test_imputed[1], xgb_prediction, num_features=5, top_labels=1)
exp.show_in_notebook(show_table=True, show_all=False)

在这里我们有一个示例,76% 的可能性是不存活的。我们还想看看哪个特征对于哪个类贡献最大,重要性又如何。例如,在 Sex = Female 时,生存几率更大。让我们看看柱状图:
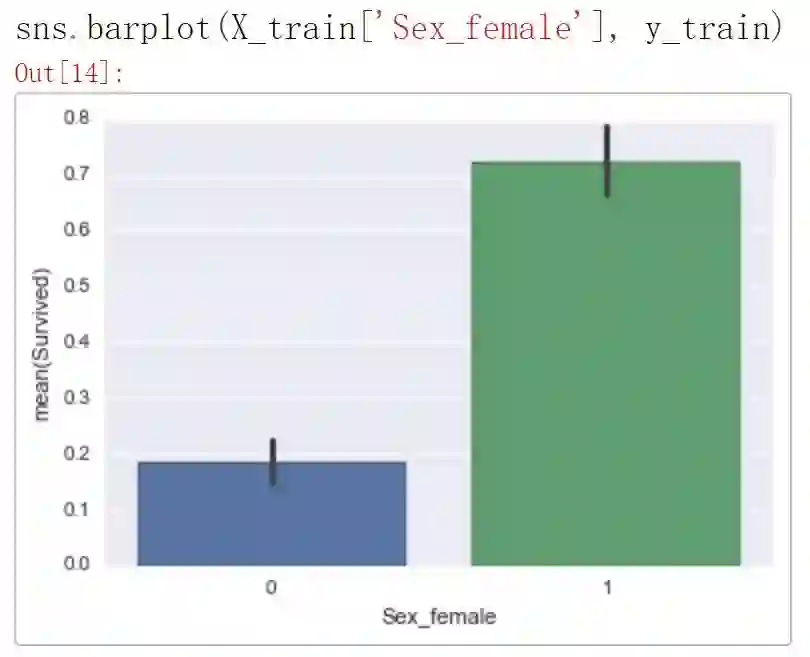
所以这看起来很有道理。如果你是女性,这就大大提高了你在训练数据中存活的几率。所以为什么预测结果是「未存活」?看起来 Pclass =2.0 大大降低了存活率。让我们看看:
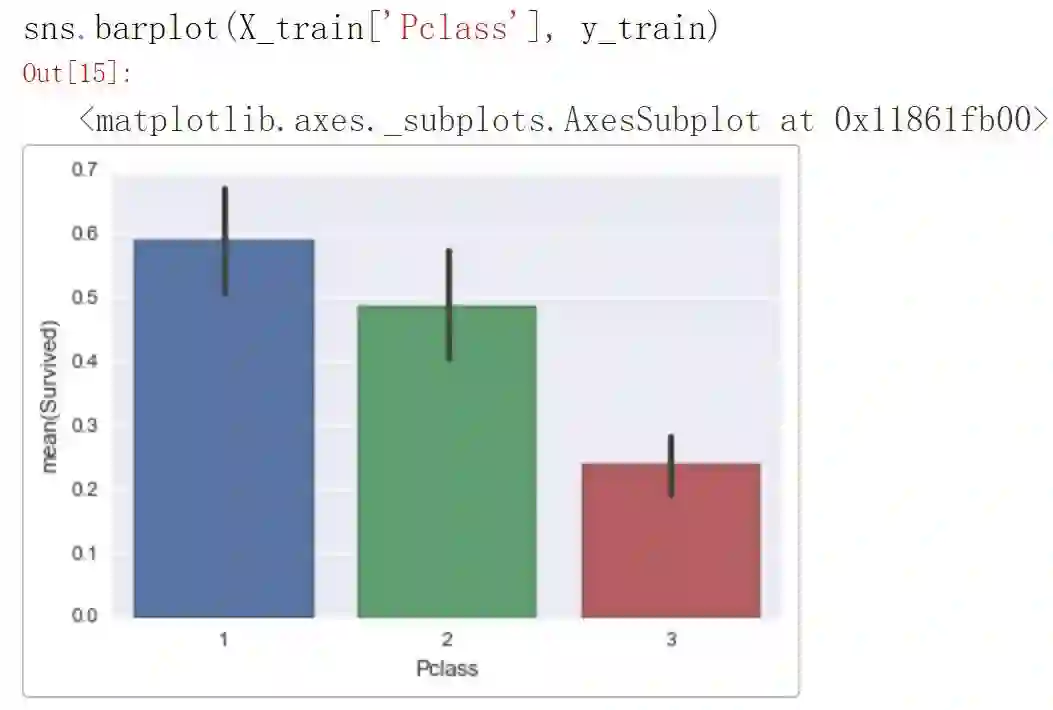
看起来 Pclass 等于 2 的存活率还是比较低的,所以我们对于自己的预测结果有了更多的理解。看看 LIME 上展示的 top5 特征,看起来这个人似乎仍然能活下来,让我们看看它的标签:
y_test.values[0]
>>>1
这个人确实活下来了,所以我们的模型有错!感谢 LIME,我们可以对问题原因有一些认识:看起来 Pclass 可能需要被抛弃。这种方式可以帮助我们,希望能够找到一些改进模型的方法。
本文为读者提供了一个简单有效理解 XGBoost 的方法。希望这些方法可以帮助你合理利用 XGBoost,让你的模型能够做出更好的推断。

原文地址:https://blogs.ancestry.com/ancestry/2017/12/18/understanding-machine-learning-xgboost/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




