送书 | 深入浅出,一起学习贝叶斯!

参与方式:如果你对哪本书感兴趣,可在评论区分享你的贝叶斯学习经验或者遇到的问题,根据留言质量,营长将从中选出三名同学送出图书。
中奖者随机生成,关键看你的留言价值是否能给其他同学一些借鉴,也便于营长将书送给真正需要的同学。
其他福利:没有获得赠书的小伙伴凭借异步社区的优惠码购买这 3 本书,可以享受 75 折的优惠!优惠码:epubitAI(有效期至 2018-02-28)
截止时间:2月6号22点
概率思维——概率与不确定性
尽管概率论是数学中一个相当成熟和完善的分支,但关于概率的诠释仍然有不止一种。对于贝叶斯派而言,概率是对某一命题不确定性的衡量。
假设我们对硬币一无所知,同时没有与抛硬币相关的任何数据,那么可以认为正面朝上的概率介于0到1之间,也就是说,在缺少信息的情况下,所有情况都是有可能发生的,此时不确定性也最大。
假设现在我们知道硬币是公平的,那么我们可以认为正面朝上的概率是0.5或者是0.5附近的某个值(假如硬币不是绝对公平的话),如果此时收集数据,我们可以根据观测值进一步更新前面的先验假设,从而降低对该硬币偏差的不确定性。
按照这种定义,提出以下问题都是自然而且合理的:火星上有多大可能存在生命?电子的质量是9.1×10−31kg的概率是多大?1816年7月9号是晴天的概率是多少?
值得注意的是,类似火星上是否有生命这种问题的答案是二值化的,但我们关心的是,基于现有数据以及我们对火星物理条件和生物条件的了解,火星上存在生命的概率有多大。该命题取决于我们当前所掌握的信息而非客观的自然属性。我们使用概率是因为我们对事件不确定,而不代表事件本身是不确定的。
由于这种概率的定义取决于我们的认知水平,有时也被称为概率的主观定义,这也就解释了为什么贝叶斯派总被称作主观统计。然而,这种定义并不是说所有命题都是同等有意义的,仅是承认我们对世界的理解是基于现有的数据和模型,是不完备的。不基于模型或理论去理解世界是不可能的。
即使我们能脱离社会预设,最终也会受到生物上的限制:受进化过程影响,我们的大脑已经与世界上的模型建立了联系。我们注定要以人类的方式去思考,永远不可能像蝙蝠或其他动物那样思考。而且,宇宙是不确定的,总的来说我们能做的就是对其进行概率性描述。需要注意的是,不管世界的本原是确定的还是随机的,我们都将概率作为衡量不确定性的工具。
逻辑是指如何有效地推论,在亚里士多德学派或者经典的逻辑学中,一个命题只能是对或者错,而在贝叶斯学派定义的概率中,确定性只是概率上的一种特殊情况:一个正确命题的概率值为1,而一个错误命题的概率值为0。只有在我们拥有充分的数据表明火星上存在生物生长和繁殖时,我们才认为“火星上存在生命”这一命题为真的概率值为1。
不过,需要注意的是,认定一个命题的概率值为0通常是比较困难的,这是因为火星上可能存在某些地方还没被探测到,或者是我们的实验有问题,又或者是某些其他原因导致我们错误地认为火星上没有生命而实际上有。与此相关的是克伦威尔准则(Cromwell’s Rule),其含义是指在对逻辑上正确或错误的命题赋予概率值时,应当避免使用0或者1。
有意思的是,考克斯(Cox)在数学上证明了如果想在逻辑推理中加入不确定性,我们就必须使用概率论的知识,由此来说,贝叶斯定理可以视为概率论逻辑上的结果。因此,从另一个角度来看,贝叶斯统计是对逻辑学处理不确定性问题的一种扩充,当然这里毫无对主观推理的轻蔑。现在我们已经熟悉了贝叶斯学派对概率的理解,接下来就了解下概率相关的数学特性吧。如果你想深入学习概率论,可以参考阅读Joseph K Blitzstein和Jessica Hwang写的《概率导论》(Introduction to Probability)。
概率值介于[0,1]之间(包括0和1),其计算遵循一些法则,其中之一是乘法法则:
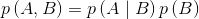
上式中,A和B同时发生的概率值等于B发生的概率值乘以在B发生的条件下A也发生的概率值,其中,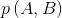
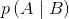
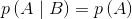
条件概率是统计学中的一个核心概念,接下来我们将看到,理解条件概率对于理解贝叶斯理论至关重要。这里我们换个角度来看条件概率,假如我们把前面的公式调整下顺序,就可以得到下面的公式:
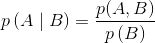
需要注意的是,我们不对0概率事件计算条件概率,因此,分母的取值范围是(0,1),从而可以看出条件概率大于或等于联合概率。为什么要除以p(B)呢?因为在已经知道事件B发生的条件下,我们考虑的可能性空间就缩小到了事件B发生的范围内,然后将该范围内A发生的可能性除以B发生的可能性便得到了条件概率
需要强调的是,所有的概率本质上都是条件概率,世间并没有绝对的概率。不管我们是否留意,在谈到概率时总是存在这样或那样的模型、假设或条件。比如,当我们讨论明天下雨的概率时,在地球上、火星上甚至宇宙中其他地方明天下雨的概率是不同的。同样,硬币正面朝上的概率取决于我们对硬币有偏性的假设。在理解概率的含义之后,接下来我们讨论另一个话题:概率分布。
▌概率分布
概率分布是数学中的一个概念,用来描述不同事件发生的可能性,通常这些事件限定在一个集合内,代表了所有可能发生的事件。在统计学里可以这么理解:数据是从某种参数未知的概率分布中生成的。由于并不知道具体的参数,我们只能借用贝叶斯定理从仅有的数据中反推参数。概率分布是构建贝叶斯模型的基础,不同分布组合在一起之后可以得到一些很有用的复杂模型。
本书会介绍一些概率分布,在第一次介绍某个概率分布时,我们会先花点时间理解它。最常见的一种概率分布是高斯分布,又叫正态分布,其数学公式描述如下:
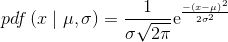
上式中,μ和σ是高斯分布的两个参数。第1个参数μ是该分布的均值(同时也是中位数和众数),其取值范围是任意实数,即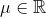
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
import seaborn as sns
mu_params = [-1, 0, 1]
sd_params = [0.5, 1, 1.5]
x = np.linspace(-7, 7, 100)
f, ax = plt.subplots(len(mu_params), len(sd_params), sharex=True, sharey=True)
for i in range(3):
for j in range(3):
mu = mu_params[i]
sd = sd_params[j]
y = stats.norm(mu, sd).pdf(x)
ax[i,j].plot(x, y)
ax[i,j].plot(0, 0,
label="$\\mu$ ={:3.2f}\n$\\sigma$ = {:3.2f}".format (mu, sd), alpha=0)
ax[i,j].legend(fontsize=12)
ax[2,1].set_xlabel('$x$', fontsize=16)
ax[1,0].set_ylabel('$pdf(x)$', fontsize=16)
plt.tight_layout()
上面代码的输出结果如下:
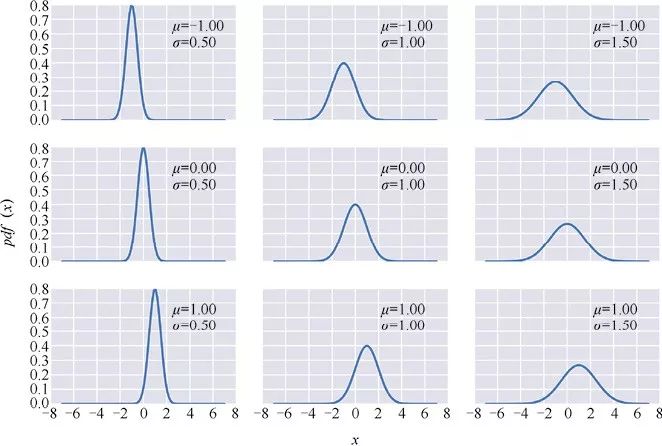
由概率分布生成的变量(例如x)称作随机变量,当然这并不是说该变量可以取任意值,相反,我们观测到该变量的数值受到概率分布的约束,而其随机性源于我们只知道变量的分布却无法准确预测该变量的值。通常,如果一个随机变量服从在参数μ和σ下的高斯分布,我们可以这样表示该变量:
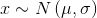
其中,符号~读作服从于某种分布。
随机变量分为两种:连续变量和离散变量。连续随机变量可以从某个区间内取任意值(我们可以用Python中的浮点型数据来表示),而离散随机变量只能取某些特定的值(我们可以用Python中的整型数据来表示)。
许多模型都假设,如果对服从于同一个分布的多个随机变量进行连续采样,那么各个变量的采样值之间相互独立,我们称这些随机变量是独立同分布的。用数学语言描述就是,如果两个随机变量x和y对于所有可能的取值都满足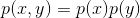
时间序列是不满足独立同分布的一个典型例子。在时间序列中,需要对时间维度的变量多加留心。下面的例子是从http://cdiac.esd.ornl.gov中获取的数据。这份数据记录了从1959年到1997年大气中二氧化碳的含量。我们用以下代码将它写出来:
data = np.genfromtxt('mauna_loa_CO2.csv',delimiter=',')
plt.plot(data[:,0], data[:,1])
plt.xlabel('$year$', fontsize=16)
plt.ylabel('$CO_2 (ppmv)$', fontsize=16)
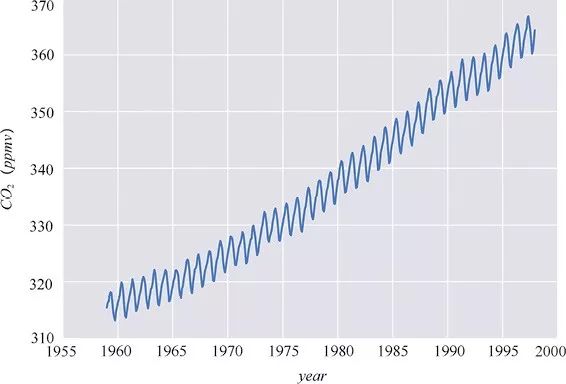
图中每个点表示每个月空气中二氧化碳含量的测量值,可以看到测量值是与时间相关的。我们可以观察到两个趋势:一个是季节性的波动趋势(这与植物周期性生长和衰败有关);另一个是二氧化碳含量整体性的上升趋势。
▌贝叶斯定理与统计推断
到目前为止,我们已经学习了一些统计学中的基本概念和词汇,接下来让我们首先看看神奇的贝叶斯定理:
看起来稀松平常,似乎跟小学课本里的公式差不多,不过这就是关于贝叶斯统计你所需要掌握的全部。首先看看贝叶斯定理是怎么来的,这对我们理解它会很有帮助。事实上,我们已经掌握了如何推导它所需要的全部概率论知识。
根据前面提到的概率论中的乘法准则,我们有以下式子:
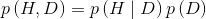
上式还可以写成如下形式:
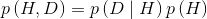
由于以上式子的左边相等,于是可以得到:
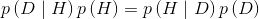
对上式调整下顺序,便得到了贝叶斯定理:
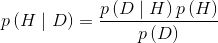
现在,让我们看看这个式子的含义及其重要性。首先,上式表明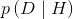
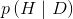
在前面的式子中,如果我们将H理解为假设,D理解为数据,那么贝叶斯定理告诉我们的就是,在给定数据的条件下如何计算假设成立的概率。不过,如何把假设融入贝叶斯定理中去呢?答案是概率分布。换句话说,H是一种狭义上的假设,我们所做的实际上是寻找模型的参数(更准确地说是参数的分布)。因此,与其称H为假设,不如称之为模型,这样能避免歧义。
贝叶斯定理非常重要,后面会反复用到,这里我们先熟悉下其各个部分的名称:
p(H ):先验;
p(D | H ):似然;
p(H | D):后验;
p(D):证据。
先验分布反映的是在观测到数据之前我们对参数的了解,如果我们对参数一无所知(就跟《权力的游戏》中的雪诺一样),那么可以用一个不包含太多信息的均匀分布来表示。由于引入了先验,有些人会认为贝叶斯统计是偏主观的,然而,这些先验不过是构建模型时的一些假设罢了,其主观性跟似然差不多。
似然是指如何在实验分析中引入观测数据,反映的是在给定参数下得到某组观测数据的可信度。
后验分布是贝叶斯分析的结果,反映的是在给定数据和模型的条件下我们对问题的全部认知。需要注意,后验指的是我们模型中参数的概率分布而不是某个值,该分布正比于先验乘以似然。有这么个笑话:贝叶斯学派就像是这样一类人,心里隐约期待着一匹马,偶然间瞥见了一头驴,结果坚信他看到的是一头骡子。当然了,如果要刻意纠正这个笑话的话,在先验和似然都比较含糊的情况下,我们会得到一个(模糊的)“骡子”后验。不过,这个笑话也讲出了这样一个道理,后验其实是对先验和似然的某种折中。从概念上讲,后验可以看做是在观测到数据之后对先验的更新。事实上,一次分析中的后验,在收集到新的数据之后,也可以看做是下一次分析中的先验。这使得贝叶斯分析特别适合于序列化的数据分析,比如通过实时处理来自气象站和卫星的数据从而提前预警灾害,更详细的内容可以阅读在线机器学习方面的算法。
最后一个概念是证据,也称作边缘似然。正式地讲,证据是在模型的参数取遍所有可能值的条件下得到指定观测值的概率的平均。不过,本书的大部分内容并不关心这个概念,我们可以简单地把它当作归一化系数。我们只关心参数的相对值而非绝对值。把证据这一项忽略掉之后,贝叶斯定理可以表示成如下正比例形式:
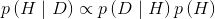
理解其中的每个概念可能需要时间和更多的例子,本书也将围绕这些内容展开。
本文节选自异步社区图书《Python贝叶斯分析》,转载已获授权,如需转载请联系异步社区。
▌福利来了!
贝叶斯统计距今已经有超过 250 年的历史,是现代数据科学家运用的众多工具集中的一种,可以用来解决预测、分类、垃圾邮件检测、排序、推断等诸多问题。本次我们为大家准备了 3 本贝叶斯的精选好书!
福利一:根据留言质量,营长将从中选出三名同学送出图书。中奖者随机生成,关键看你的留言价值是否能给其他同学一些借鉴,也便于营长将书送给真正需要的同学。活动截止时间为2月6号22点。
福利二:我们为大家准备了异步社区的购书优惠码,没有获得赠书的小伙伴凭借优惠码购买这 3 本书,可以享受 75 折的优惠!优惠码:epubitAI(有效期至 2018-02-28)

《Python贝叶斯分析》
【阿根廷】Osvaldo Martin(奥斯瓦尔多·马丁)
贝叶斯统计距今已经有超过250年的历史,其间该方法既饱受赞誉又备受轻视。直到近几十年,得益于理论进步和计算能力的提升,贝叶斯统计才越来越多地受到来自统计学以及其他学科乃至学术圈以外工业界的重视。本书将从实用的角度来学习贝叶斯统计,不会过多地考虑统计学范例及其与贝叶斯统计之间的关系。本书的目的是借助Python做贝叶斯数据分析,尽管与之相关的哲学讨论也很有趣,不过受限于篇幅,这部分内容并不在本书的讨论范围之内,有兴趣的读者可以通过其他方式深入了解。无论你是数据科学的新手,还是有经验的专业人士,都可以从本书学到贝叶斯分析的方法。

《贝叶斯方法:概率编程与贝叶斯推断》
【加】Cameron Davidson-Pilon
简介:从20世纪80年代末到90年代,人工智能领域出现了3个最重要的进展:深度神经网络、贝叶斯概率图模型和统计学习理论。贝叶斯方法是一种常用的推断方法,是现代数据科学家运用的众多工具集中的一种,可以用来解决预测、分类、垃圾邮件检测、排序、推断等诸多问题。在下一个十年,掌握贝叶斯方法,就像今天掌握C/C++、Python一样重要。提到贝叶斯,就不能不提到这本书。这本书得到了国际著名机器学习专家余凯博士、腾讯专家研究员岳亚丁博士联合推荐。这本书基于PyMC语言以及一系列常用的Python数据分析框架,如NumPy、SciPy和Matplotlib,通过概率编程的方式,讲解了贝叶斯推断的原理和实现方法。无需复杂的数学分析,通过实例、从编程的角度介绍贝叶斯分析方法,大多数程序员都可以入门并掌握。

《贝叶斯思维:统计建模的Python学习法》
【美】Allen B.Downey
简介:在大数据和人工智能时代,贝叶斯方法正在变得越来越常见与重要。贝叶斯方法是一种常见的利用概率学知识去解决不确定性问题的数学方法,对于一个计算机专业的人士,应当熟悉其应用在诸如机器翻译,语音识别,垃圾邮件检测等常见的计算机问题领域。这本书基于Allen Downey在大学讲授的本科课程,帮助那些希望用数学工具解决实际问题的人们。全书在15章的篇幅中讨论了怎样解决十几个现实生活中的实际问题。本书适合懂得Python语言和有一点概率论知识的读者阅读。通过学习本书,读者可以利用Python代码处理实际工作中的贝叶斯统计问题,比如分析SAT考试成绩,模拟肾脏肿瘤分析等。
关于异步社区
异步社区(www.epubit.com.cn)是人民邮电出版社旗下IT专业图书旗舰社区,也是国内领先的IT专业图书社区,致力于优质学习内容的出版和分享,实现了纸书电子书的同步上架。

新一年,AI科技大本营的目标更加明确,有更多的想法需要落地,不过目前对于营长来说是“现实跟不上灵魂的脚步”,因为缺人~~
所以,AI科技大本营要壮大队伍了,现招聘AI记者和资深编译,有意者请将简历投至:gulei@csdn.net,期待你的加入!
如果你暂时不能加入营长的队伍,也欢迎与营长分享你的精彩文章,投稿邮箱:suiling@csdn.net
如果以上两者你都参与不了,那就加入AI科技大本营的读者群,成为营长的真爱粉儿吧!后台回复:读者群,加入营长的大家庭,添加营长请备注自己的姓名,研究方向,营长邀请你入群。




☟☟☟点击 | 阅读原文 | 查看更多精彩内容




