关于 K means 聚类算法,你需要知道这些东西

本文为AI研习社编译的技术博客,原标题 K-Means Clustering: All You Need to Know,作者为 Uday Keith 。
翻译 | 李锋 周静 校对 | 余杭 整理 | MY

在机器学习中,我们经常处于函数逼近的范畴。也就是说,我们有特定的真实值(y)和相关变量(x) 并且我们的目标是使用标识一个函数来封装我们的变量,以及函数的结果非常接近真实值。这个函数近似的练习也被称为监督学习。
另一方面,无监督学习有稍微的不同。我们的数据不包括真实值,而是只有变量。让我们来详细说明下无监督学习与监督学习的不同。
因为我们没有真实值,那么我们的任务不是预测或者接近任何结果。因此,没有损失/代价函数提供关于我们的函数输出与真实值是否接近的反馈。这很复杂吗?如果没有关于输出好坏的反馈,那么怎样知道我们的输出是令人满意的还是完全无用呢?
在本教程中,我们将了解什么是无监督学习,全面理解并执行一个常见的无监督学习任务,即集群。
聚类
在没 teacher/真实值的情况下,我们能用变量做什么呢?让我们用在线零售数据集来举例吧。这是一个包含英国在线零售商在 2010-2011 年期间所有交易的数据集。接下来用 pandas 库来看看数据。
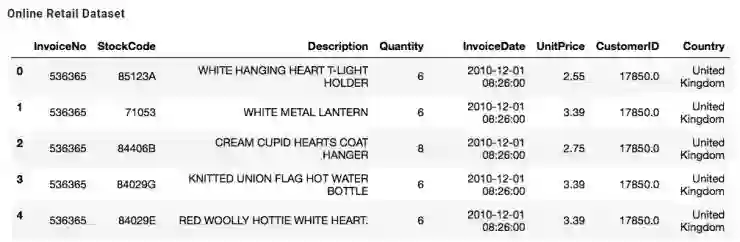
K-means 数据集中有 8 个列表以及 50 多万行数据
现在,假如你是个在线零售商,这个数据能用来干什么呢?可以用来尝试识别客户类型,那么我能得到多少种客户类型呢?这就是电子商务中常见的客户细分任务。客户细分指的是将客户群划分为与市场营销相关的、在特定方面类似的个人群体,例如年龄,性别,兴趣爱好和消费习惯。所以这里的任务是识别互相相似的客户,划分到同一个组,接着寻找其他类似的组或段。
在机器学习中,识别相似度的任务称为聚类。K-Means 中最常用的聚类技术。
K 均值算法
K-Means 是一种迭代聚类算法,它试图将数据中的同构或相似的子组聚类。我们要做的第一件事情就是明确地定义相似性和差异性。在我们的观测中,简单来说,可以通过数据点之间的欧几里得距离来定义相似性。用下面的例子来说明,根据个人的身高和体重图表,绿色的数据点(个人)比红色的数据点更相似。
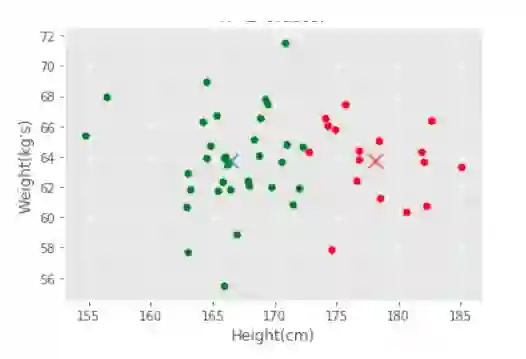
相似性的简单案例:身高和体重
因此,如果两个数据点很相似,就将它们视为一个集群的。理想的情况下,我们倾向于一个集群的数据点彼此间尽可能的接近。然后,我们可以正式地描述集群的目标:使一个集群内,所有集群之间的观察距离最小。我们可以用一个函数来表示:
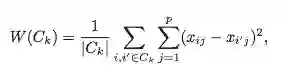
K-means 函数里的 W(Ck), Σ(xij-xi'j) 指的是,「变量 x 在第 k 个簇中观测到的欧几里得距离的平方和」. 外面的Σ 计算了跨集群间欧几里得距离的总和(从第 1 个到第 K 个集群,故叫 K 均值)。
我们的目的是使函数 W(Ck) 最小化,那么怎么做呢? 实现这种最小化的迭代算法 (步骤) 是:
在 1 到 K 中随机选取一个数字给数据中的每一行(稍后说明如何选择这个数)。这是初始的集群分配。
对每一个集群计算它的质心,这是每个 K 集群观测时的特征向量。向量大小由数据集中特征的数量 (p)来决定。对于在线零售来说,向量大小为 8。
重新访问初始的集群分配,并将每一行重新分配给其质心第 p 个特性的集群。
迭代 (重复步骤 1-3),直到集群分配停止变化或处于可容忍的水平 (稍后将对此进行详细介绍)。
下面的 K-means 类是上述步骤的实现。阅读注释可以帮助你理解步骤。

在线零售数据集中,如果我们将客户分成两个区段,并根据他们的簇分配类别向每个客户发送营销材料,我们可能过于笼统地推销市场了。因此,客户可能不会重回我们的电子商务网站。另外,如果我们把客户分成 100 个区段,我们可能在每段上只有少数客户,发送 100 种不同的营销材料将会是一场噩梦。因此,虽然对于 K 的选择是一个商业决策,但我们确实有指导我们最终决定的技巧。在将我们的算法应用到我们的数据之前,有几点需要解释。首先,我们如何选择数据中有需要多少簇? 好,这真是聚类问题的核心所在。根据我们的数据,我们不知道是否有 4 或者 7 种类型的客户(簇),因为这确实是一个无监督的问题。因此我们的问题是确定最适合的 K 个簇来分割我们的数据。然而,并没有「正确「答案,因为没有真实值。事实上,选择 K 值的过程通常是一个商业决策。
选择正确的 K 值
弯管法
弯管法允许我们通过视觉辅助对 K 值做出判定。我们试着将我们的数据分解成不同数量的 K 簇,并根据相应的 W(Ck)画出每个 K 簇类型。下面是一个例子。
原文链接:https://byteacademy.co/blog/k-means-clustering/
点击文末【阅读原文】即可观看更多精彩内容:
最常见的 35 个 Python 面试题及答案(2018 版)
基于 Keras 对深度学习模型进行微调的全面指南
理解Python数据类
手把手教你用 Keras 实现 LSTM 预测英语单词发音
等你来译:
针对嵌入式系统的函数编程
为何选择Scala
Python学习:从新手到高手
为啥2018年要学Dart
如何从头教授学生用 python 编写 t-Test 代码





