SuMa++:基于激光雷达的语义SLAM
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文授权转载自:泡泡机器人SLAM
标题:SuMa++: Efficient LiDAR-based Semantic SLAM
作者:Xieyuanli Chen, Andres Milioto, Emanuele Palazzolo, Philippe Giguere, Jens Behley, Cyrill Stachniss
来源:IROS 2019
编译:任乾 | 审核:Camel

摘要

可靠的高精度定位和建图是自动驾驶系统的关键环节。除了高精度的几何信息以外,地图中还应该包含语义信息,为载体的智能行为提供依据。但在实际环境中,移动物体的存在会使建图过程变得更加复杂,因为它会污染地图并影响定位效果。在这篇文章里,我们在基于曲面建图(surfelbased mapping)传统方法的基础上,增加语义信息的融合以解决上述问题。基于神经网络提取语义信息,对点云中所有的点都打上类别标签,从而在曲面建图时,得到的是带有标签的曲面。通过这种方法,不仅可以滤除动态物体,而且可以使用语义信息对里程估计进行约束,以提高地图精度。为了验证该方法的效果,我们使用KITTI数据集中的高速公路场景进行实验,结果表明,它的效果要优于传统的仅使用集合信息的方法。
主要贡献
对点云进行语义分割,根据语义信息识别动态物体,并在地图中去除。
-
把带有语义标签的物体进行数据关联,和几何信息一起建立约束关系,从而提高建图精度。
主要算法
1、整体思路
本论文所提出的整体网络结构如图1所示,从图中我们可以看出该算法的主要流程:
1)通过网络对点云进行语义分割
2)使用漫水填充(flood-fill)方法消除错误的类别标签
3)使用滤波器进行动态物体检测,并移除动态物体
4)建立带语义信息约束的ICP模型,优化里程精度
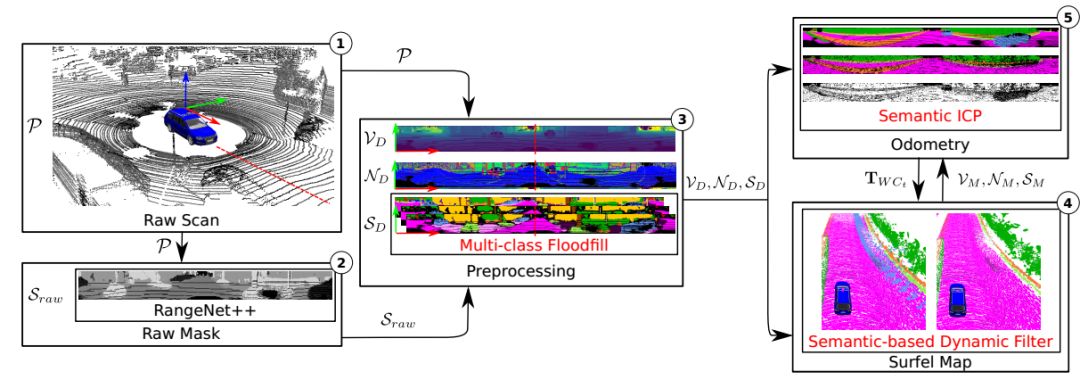
图1 网络整体结构
2、语义分割
语义分割使用的是RangeNet++方法,它的主要内容在另一篇论文里,该论文并没有对这个方法进行太多的改进,下图是RangeNet++的网络结构图
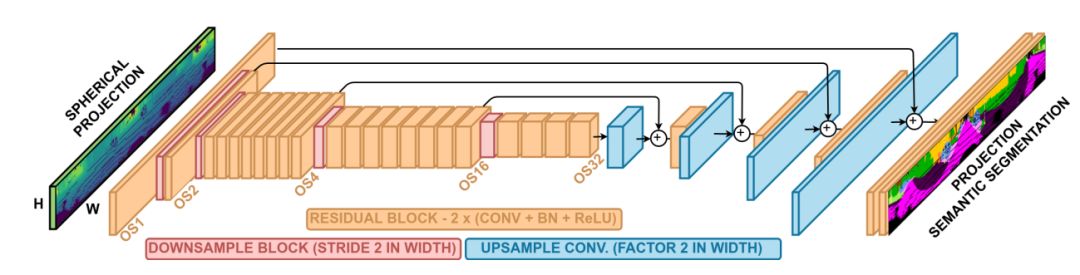
图2 RangeNet++网络结构图
3、漫水填充(flood-fill)
由于网络对点云进行的语义分割必然包含正确分类和错误分类,而这里面的错误会对后续环节产生不好的影响,因此有必要对其进行消除。这一环节的主要流程如下图所示。
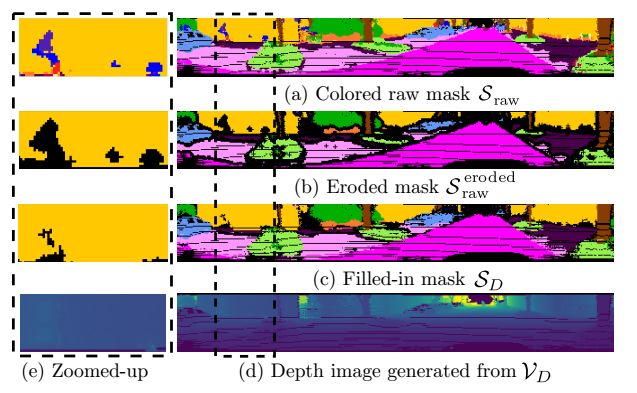
图3 flood-fill方法示意图
上图中左侧是右侧图中虚线框方法的部分,先对(a)中的错误识别结果进行剔除,得到(b),然后利用周围的标签点云对他进行填充,得到(c)。最后(d)中显示的是(c)对应的深度图。
4、移除动态物体
动态物体的识别是根据物体在同一位置出现的概率实现的。具体来讲,就是说如果在这一帧中,某个位置出现了物体,在下一帧中,它还在,如果连续很多帧它都出现在同一个位置,那么它就是静止的,反之,在每一帧中检测到的位置都发生变化,那么它就是移动的。当然,此处位置指的是地图中的位置,而不是相对于当前帧点云的位置。上面是为了方便理解采用的通俗的解释,实际算法实现是用下面的公式
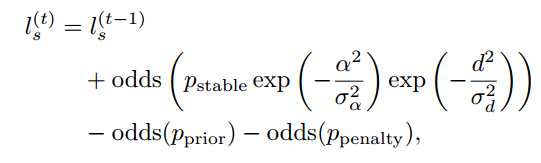
这个公式就是用来计算概率的。如果有对cartographer比较熟悉的读者,会发现这个公式其实和cartographer移除动态物体的公式很像,其实他们的核心思想确实是一样的。
5、基于语义信息的ICP
我们知道ICP对两帧点云匹配其实就是让两帧点云对应点的距离达到最小,越小说明位姿估计的越准。但它仅使用几何信息,鲁棒性不是很好。此处作者为了改进这一问题,把语义信息也加入了ICP的数据关联当中,每一个物体对应一个关联关系,进行位姿估计时,除了点云要尽量接近,带语义标签的各个物体也要尽量接近。
实验
作者在KITTI数据集上进行了测试,而且专门挑的移动物体特别多的路段,实际效果如下图所示。
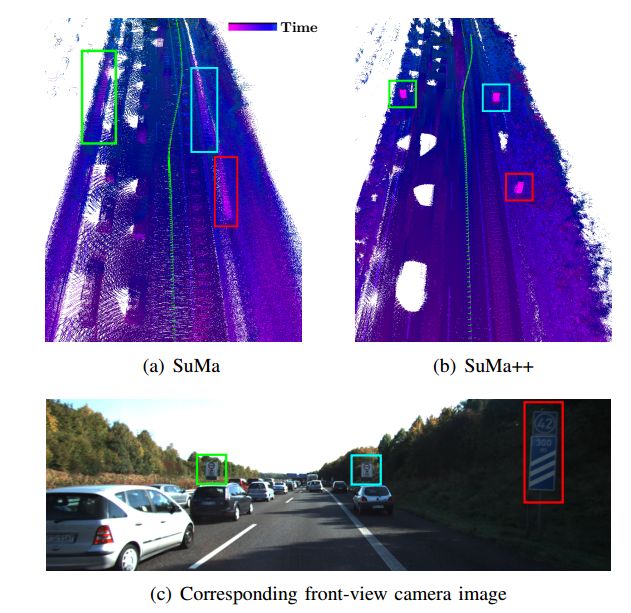
图4 对比效果图
在上图中,(c)是真实的环境,这里的图片只是为了向读者展示环境里有什么,算法并没有用到图片信息。(a)和(b)分别是不结合语义信息和结合语义信息建立的地图,从图中明显可以看出,不使用语义信息时,周围的车辆造成的拖尾现象就特别严重。但我们同样也发现了另一个现象,就是在考虑语义信息以后,虽然没有拖尾,但是车辆仍然在里面,也就是说如果建图的时候有堵车,那么公路的地图中仍然会有车辆,而这对地图来讲也是不友好的。因此,不仅需要移除动的物体,而且有必要移除一些可能动的物体。
结论
本文提出了一种基于语义信息的激光SLAM系统,通过语义分割,识别出周围环境中的物体,以物体为单位,构建和带有语义约束的ICP模型,提高了定位的稳定性,同时对动态物体进行了识别并剔除,提高了地图的质量。

Abstract
Reliable and accurate localization and mapping are key components of most autonomous systems. Besides geometric information about the mapped environment, the semantics plays an important role to enable intelligent navigation behaviors. In most realistic environments, this task is particularly complicated due to dynamics caused by moving objects, which can corrupt the mapping step or derail localization. In this paper, we propose an extension of a recently published surfelbased mapping approach exploiting three-dimensional laser range scans by integrating semantic information to facilitate the mapping process. The semantic information is efficiently extracted by a fully convolutional neural network and rendered on a spherical projection of the laser range data. This computed semantic segmentation results in point-wise labels for the whole scan, allowing us to build a semantically-enriched map with labeled surfels. This semantic map enables us to reliably filter moving objects, but also improve the projective scan matching via semantic constraints. Our experimental evaluation on challenging highways sequences from KITTI dataset with very few static structures and a large amount of moving cars shows the advantage of our semantic SLAM approach in comparison to a purely geometric, state-of-the-art approach.
重磅!CVer-SLAM交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪&去雾&去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。一定要备注:研究方向+地点+学校/公司+昵称(如SLAM+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!




