无需标注数据集,自监督注意力机制就能搞定目标跟踪
作者:Rishab Sharma
机器之心编译
编辑:陈萍、杜伟
深度学习的蓬勃发展得益于大规模有标注的数据驱动,有监督学习推动深度模型向着性能越来越高的方向发展。但是,大量的标注数据往往需要付出巨大的人力成本,越来越多的研究开始关注如何在不获取数据标签的条件下提升模型的性能,这其中就包括自监督注意机制。



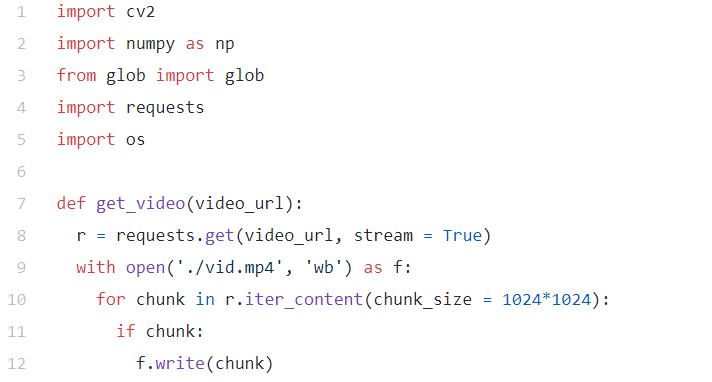

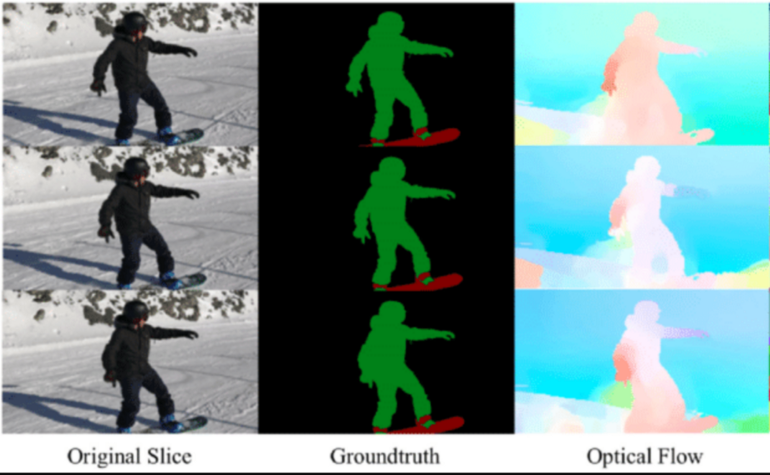
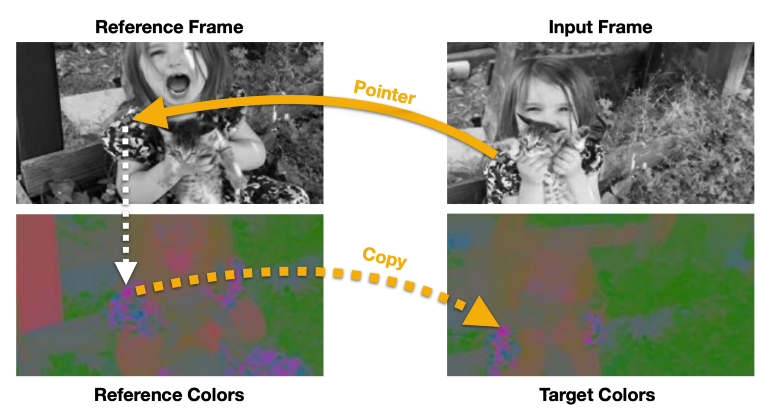
必须防止模型学习这个任务无效解(trivial solution),例如基于低级颜色特征匹配连续帧;
必须使跟踪器飘移不那么严重。跟踪器漂移(tracker drifting, TD)主要是由目标遮挡、复杂的目标变形和随机光照变化引起的。跟踪器飘移问题通常是在长时间窗口上训练递归模型来解决,该窗口具有周期一致性和定时采样特点。

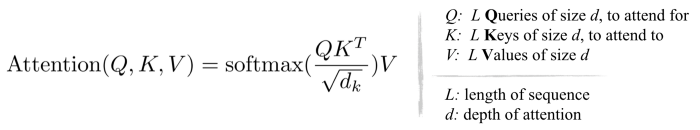



© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
58+阅读 · 2019年12月2日
专知会员服务
93+阅读 · 2019年11月15日
Arxiv
3+阅读 · 2018年11月27日
Arxiv
8+阅读 · 2018年2月7日
Arxiv
13+阅读 · 2018年1月6日





相关VIP内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
58+阅读 · 2019年12月2日
专知会员服务
93+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
3+阅读 · 2018年11月27日
Arxiv
8+阅读 · 2018年2月7日
Arxiv
13+阅读 · 2018年1月6日