CCMT2019最佳论文奖:在远距离语言对上提升双语词典推断的质量
“ CCMT2019的最佳论文由程序委员会按照双盲评审意见推荐候选,由五位资深专家构成的评奖委员会进行独立评审,评选出中英文最佳论文各一篇。南京大学NLP组与中兴通讯有限公司合作的论文《Improving Bilingual Lexicon Induction on Distant Language Pairs》被评为CCMT2019最佳英文论文。论文作者朱文昊同学本科毕业于南京大学,在校期间曾获得多项奖学金,被评为2019届南京大学优秀毕业生,现为南京大学计算机科学与技术系19级直博生,研究方向主要是机器翻译。”


01
—
背景介绍
双语词典是机器翻译(Machine Translation,MT)的重要组成部分。传统上,编纂一份词典需要借助大量的人力物力和专家知识。Mikolov等人2013年提出可以通过一个线形映射对齐两种语言的词向量空间,进而推断双语词典(图1),这大大提升了生成词典的效率。近年来,双语词典推断模型(Blingual Lexicon Induction,BLI)不断发展,在欧洲语言对上取得了非常好的效果。
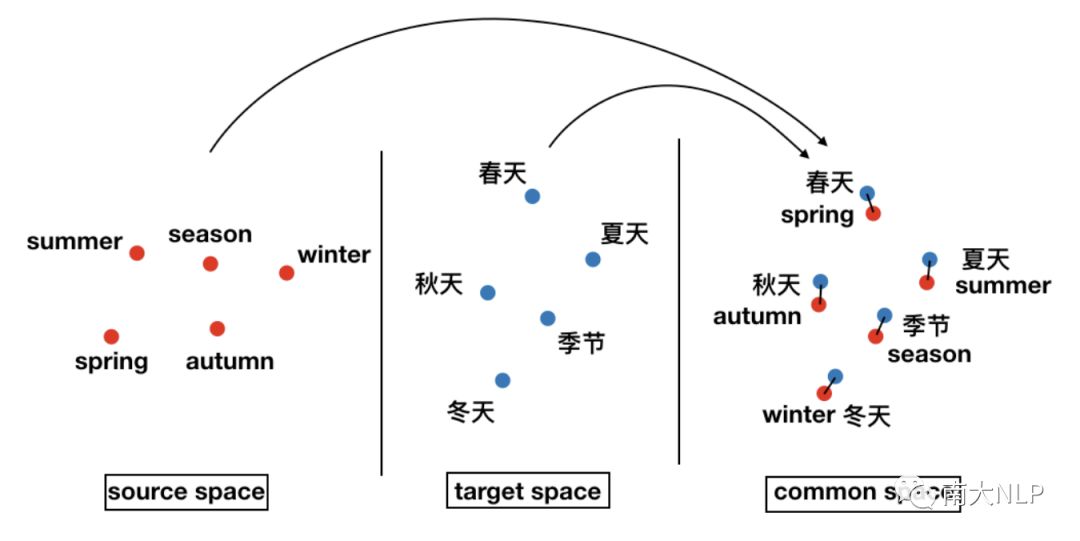
图1 双语词典推断示例
然而当有监督双语词典推断方法被迁移到远距离语言对上时(如En-Zh, En-Ja),性能将出现巨大的衰减。之前这个问题并没有得到广泛的关注,本文希望深入分析并解决这个问题。
02
—
解决方案
有监督方法主要由三个步骤组成:预处理,映射和推断。
预处理指在映射前对词向量空间做变换,比如说’’单位化’’和’’中心化’’等(图2)。然而这些预处理方法都是在欧洲语言对上提出的,在远距离语言对上如何选择使用这些方法是一个疑问。我们猜想’’单位化’’和’’中心化’’是针对远距离对的最优组合,其他的预处理方法并不能再带来更多的增益。我们在之后的实验部分做了对比分析。
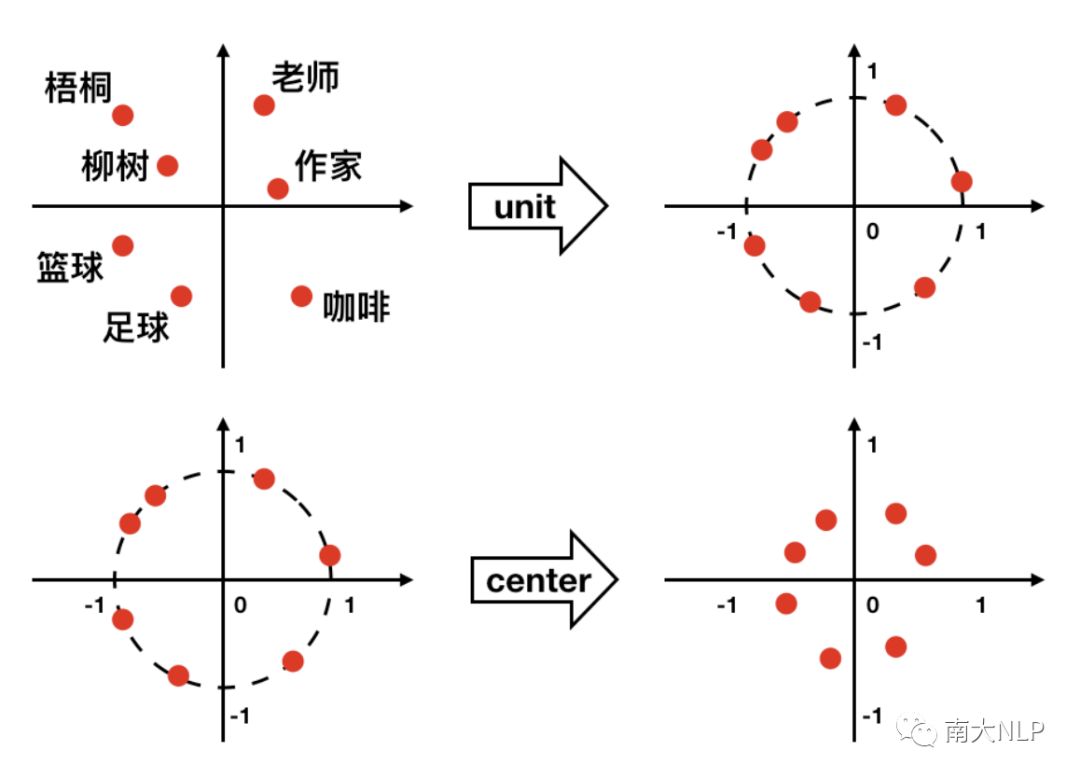
图2 单位化,中心化示意图
预处理之后需要进行映射,将两个语言空间映射到公共空间。主要是使用一个矩阵W作为映射矩阵。后来研究者提出需要限制W为正交矩阵。也有研究尝试非线性映射,但是效果并不好。使用正交矩阵作为映射已经成了一种标准的做法(图3)。然而使用单个线形映射是基于一种理想的假设:两个语言空间的几何分布相似。但我们通过观察发现这种假设在远距离对上并不成立。这种假设可能只发生在局部(图4),使用多个局部映射效果会比一个全局映射效果更好。
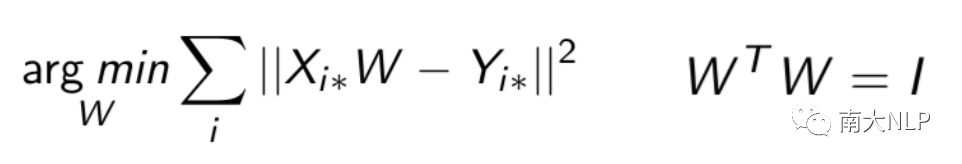
图3 计算映射函数
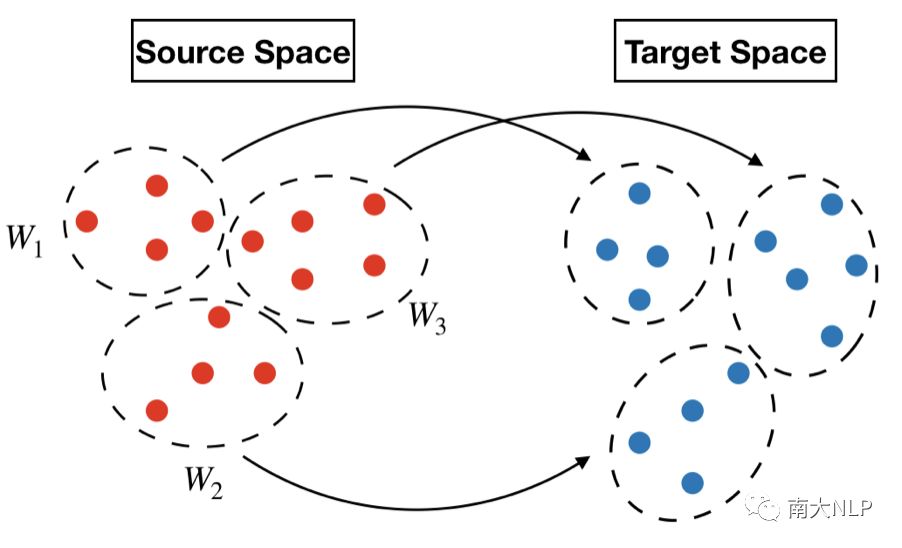
图4 使用多个局部映射
将两个词向量空间映射到公共空间之后,需要通过推断函数将单词一一配对生成词典(图5)。最先使用的推断函数是最近邻(nearest neighbour, NN),但是遭遇一个非常严重的问题,叫做“hubness”(图6)。“hubness”是指一些无意义的目标端单词(如1988-03, aaaa)在映射后会成为非常多源语言单词的最近邻。后来CSLS公式被提出解决这个问题,它在NN的基础上通过计算词语与周围K(论文作者推荐设置K为10)近邻词语的平均相似度来进行惩罚,避免hub word成为翻译。但是我们观察到语言空间中还有另一种词与hub word具有相似的特性,叫做topic word(图6)。这类词代表了很广泛的一类词,因此也和周围的词也具有非常高的平均相似度。因此CSLS经常会将topic word当成hub word错误地惩罚。幸运的是,我们发现调节CSLS中的超参数K可以有效的解决这种问题。解释如下:当K很小时,两种单词与周围K近邻单词都具有非常高的平均相似度(图7)。而当K逐步增大时,topic word与周围词的平均相似度会下降,hub word则依然与周围词保持很高的平均相似度,这种情况下就可以分辨出两者了。我们提出了一种近似搜索K值的算法:以10为步长增大K,直到模型在训练集上的性能出现衰减,就以上一步的K值作为CSLS的超参数。
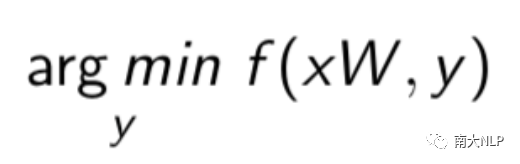
图5 推断函数

图6 hub word和topic word示意图

图7 当K较小时
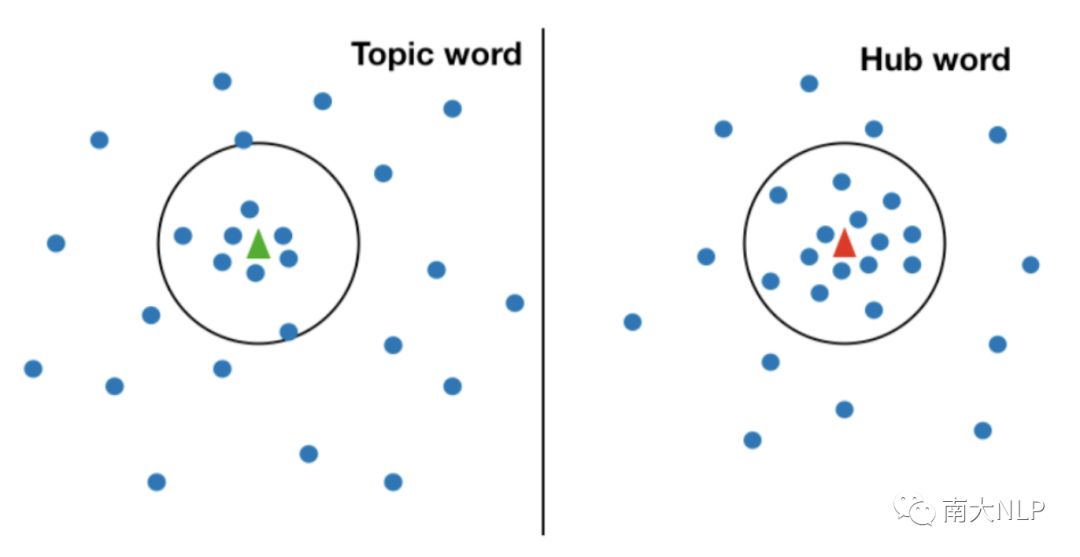
图8 当K增大时
03
—
实验分析
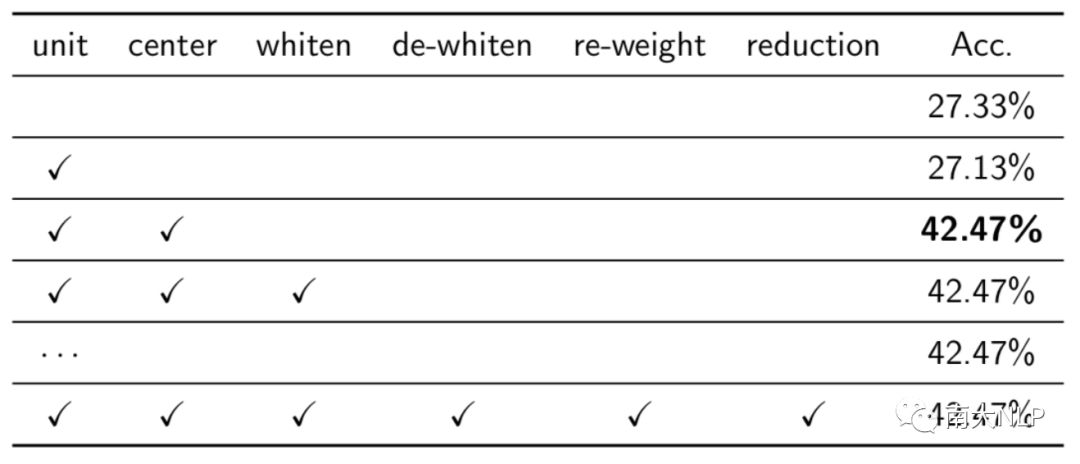
我们在Fasttext数据集上进行了实验。在预处理部分(表1),我们发现中心化和单位化是最优的组合,并且中心化为模型带来了最大的增益。
表1 预处理方法对比结果
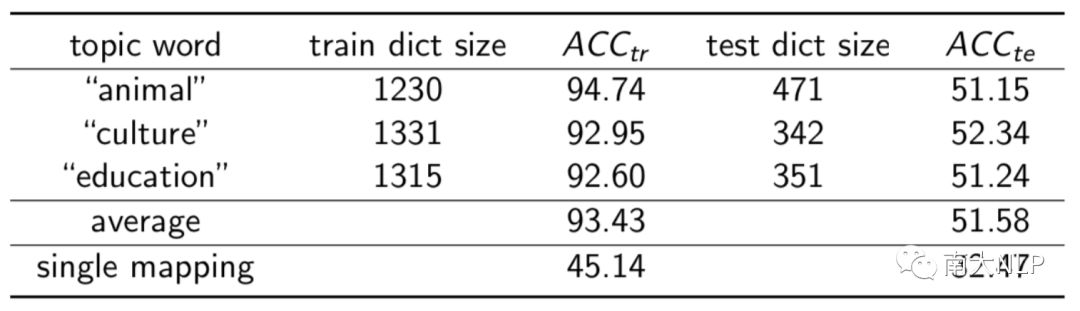
在局部映射部分我们手动选择了一些话题,根据话题对训练集进行切分,训练局部映射。表2列出三个有代表性的例子,可以看出局部映射的质量远远高于单个全局映射。这里需要注意的是,局部映射个数的确定,话题选择,依然是难点。因此本文并没有将局部映射方法纳入最终的改进框架。
表2 局部映射的结果展示
映射部分观察K值与准确率的关系(图7)可以发现:作者推荐的K=10远远不是最佳设定。我们的搜索算法所确定的K值是更好的,并且克服了topic word被错误翻译的现象。
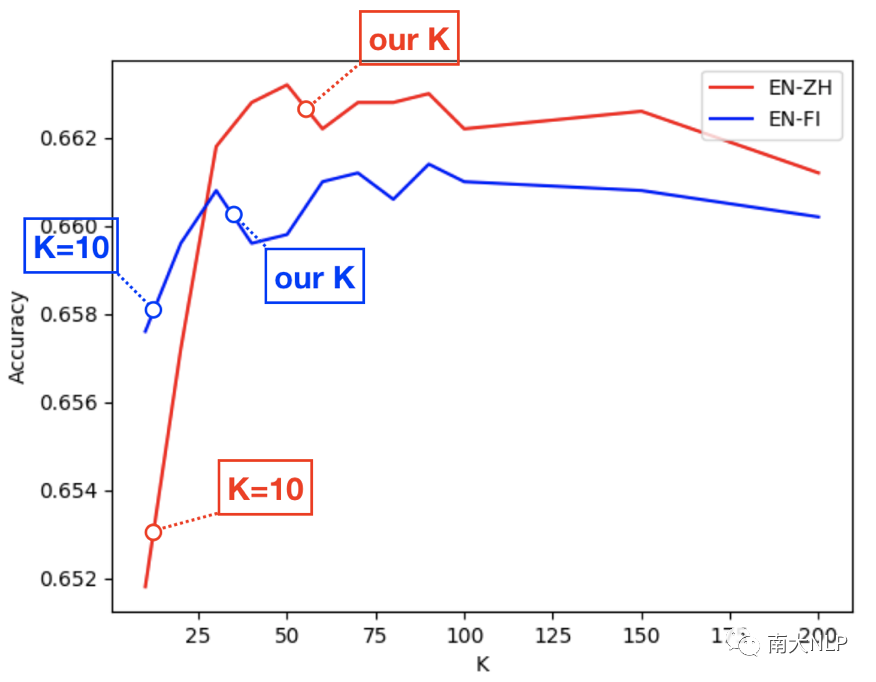
图7 准确率曲线随K值的变化情况
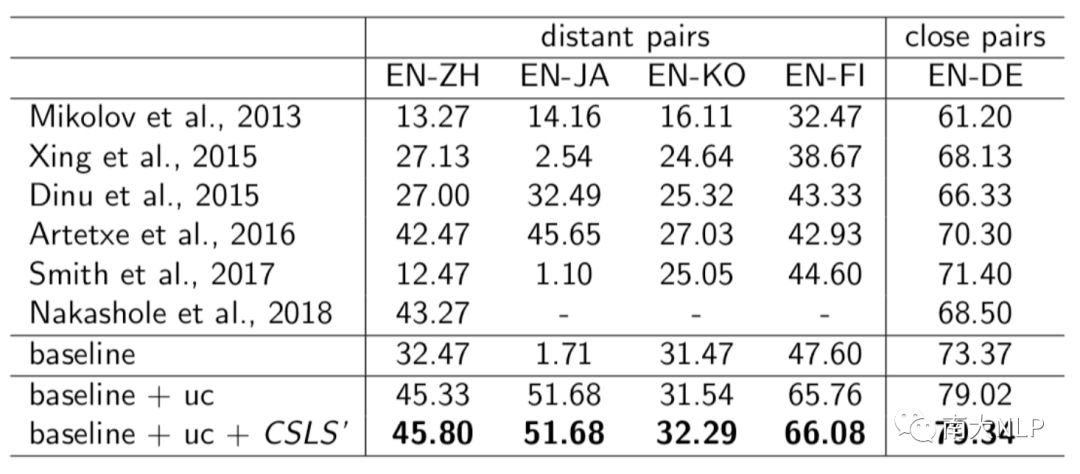
综上:我们的改进框架是:使用“单位化”和“中心化”做预处理,使用正交矩阵作为映射,使用CSLS(使用我们的搜索算法确定超参K) 作为推断函数。我们将改进框架和baseline进行了对比(表3)。可以发现无论在近距离对还是远距离对上,我们的改进模型的性能都大幅提升,并且在远距离对上提升尤其明显。观察发现,我们改进的两个步骤都对性能提升产生了贡献。
表3 改进框架与之前研究的对比
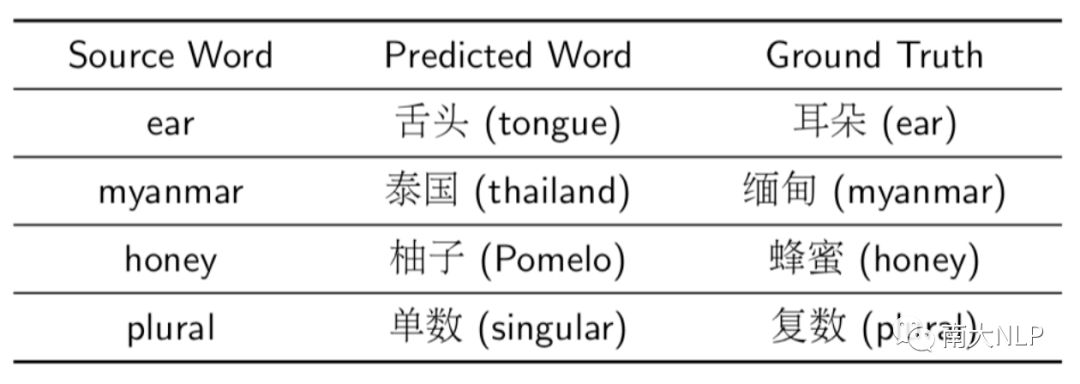
我们进一步分析了我们的改进框架,观察错误翻译样例发现,大部分剩余错误都属于同一个类型。在表4中列出了一些有代表性的例子(表4)。可以发现错误的原因都是无法区分两个上下文相似的词。词向量的训练方法决定了拥有相似上下文的单词在语言空间中的分布会十分接近,这大大增加了词典推断的难度。这也是未来我们希望解决的问题。
表4 错误翻译样例
04
—
总结
我们对现有有监督方法进行了深入的分析,提出了三种方法依次解决三个观察到的问题,最终提出了针对远距离对的改进的双语词典推断模型。未来希望继续完善局部映射的做法,以及解决拥有相似上下文的单词对词典推断造成的干扰。
参考文献:
Exploiting Similarities among Languages for Machine Translation. Mikolov et al. arXiv 2013.
Improving zero-shot learning by mitigating the hubness problem. Dinu et al. ICLR 2015.
Word Translation Without Parallel Data. Conneau et al. ICLR 2018.
作者:朱文昊
编辑:何亮
南大NLP研究组

南京大学自然语言处理研究组从事自然语言处理领域的研究工作始于20世纪80年代。曾先后承担过该领域的18项国家科技攻关项目、863项目、国家自然科学基金和江苏省自然科学基金以及多项对外合作项目的研制。其中,承担的国家七五科技攻关项目“日汉机译系统研究”获七五国家科技攻关重大成果奖、教委科技进步二等奖以及江苏省科技进步三等奖。
分析理解人类语言是人工智能的重要问题之一,本研究组在自然语言处理的多个方向上做了大量、深入的工作。近年来集中关注文本分析、机器翻译、社交媒体分析推荐、知识问答等多个热点问题,结合统计方法和深度学习方法进行问题建模和求解,取得了丰富的成果。本研究组在自然语言处理顶级国际会议ACL上连续三年发表多篇论文,也在人工智能顶级国际会议IJCAI和AAAI上发表论文多篇,相关系统在机器翻译、中文分词、命名实体识别、情感计算等多个国际国内评测中名列前茅。
本实验室立志于研究和解决在传统文本和互联网资源的分析处理中面临的各项问题和挑战,并积极探索自然语言处理的各种应用。如果你也和我们有共同兴趣或目标,欢迎加入我们!





