2017上半年无监督特征学习研究成果汇总
全球人工智能:一家人工智能技术学习平台。旗下有:Paper学院、商业学院、科普学院,技术学院和职业学院五大业务。拥有十几万AI开发者和学习者用户,1万多名AI技术专家。
特征学习在无监督学习方式下的趋势:回归到多元学习的随机目标,利用因果关系来表征视觉特征,以及在强化学习中,通过辅助控制任务增加目标,并通过自发进行预训练。从未标记的数据中学到很多东西,似乎我们只用标签撇去了它的表面。

在这篇文章中,我将向你展示,2017年无监督学习领域发生了什么变化。
无监督学习是机器学习中长期存在的挑战,它被认为是人工智能的重要组成部分。在没有标签的数据中有很多信息,我们并没有完全的使用它,而值得注意的是,大脑的学习机理大多是无监督的学习方式。
为了模拟人脑的终极目标,无监督学习成为了很多研究人员的研究热点。接下来我们就介绍一些近期无监督学习的成果。
第一个成果:多元学习的随机目标
Unsupervised learning by predicting the noise[Bojanowski&Joulin ICML17];这篇论文,今年在ICML中排名第一。想法如下:从超球体采样均匀的随机向量,数值为数据点的数量级。这些将成为回归目标的替代者。事实上,通过以最小化损失进行监督式学习,在深层卷积网络中学习视觉特征,可以将图像与随机向量相匹配。大致过程如图所示:
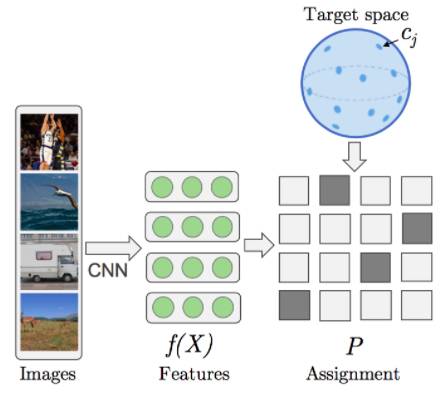
特别地,在训练过程网络参数的梯度下降交替之间,将伪目标重新分配给不同的图像,以便最小化损失函数。这里是ImageNet的视觉特征的结果;他们都是在ImageNet上训练AlexNet的结果,左边是目标,右边是提出无监督的方法。

在论文中探讨的转移学习,似乎是最先进的。但为什么要这样工作呢?因为神经网络正在学习一个新的特征空间,这是一种隐含的多元学习。通过混合分配进行优化可能是至关重要的,因为不良匹配将不允许将类似图像映射给彼此。此外,网络必须作为信息瓶颈(information bottleneck)。否则,在无限容量的情况下,模型将简单地学习一个不知情的1对1图像到噪声图(Noise map)。
第二个成果:因果关系的重要性
Discovering causal signals in images[Lopez-Paz et al。CVPR17]我从同LéonBottou鼓舞人心的谈话中发现了第二个成果:looking for missing signal,接下来要介绍的是他们的WGAN。这里的讨论重点是关于因果关系。但在谈论之前,让我们再回一下,看看因果关系。
如果你站在机器学习视角中去了解因果关系,你会很快得出结论:整个领域在其基础上缺少一些相当重要的东西。我们创造了一个完整的解决行业问题的方法,那就是只考虑相关性,联想和预测只是考虑训练数据中的相关性,但这在许多情况下不会起到真正的作用。如果我们能够在学习决策中考虑上因果关系的模型会不会有所好转?基本上,我们可以避免卷积网络告诉我们,图片中的动物是狮子,因为背景显示了的Savanna(美国东南部的大草原,有狮子)。

许多人正在努力实现这一想法。这篇论文旨在通过实验验证“图像数据集的高阶统计信息可以告知因果关系”。更准确地说,作者猜测,对象特征和反效应特征是密切相关的,反之亦然,上下文特征和因果特征不一定相关。上下文特征给出了背景,而对象特征是通常在图像数据集中的边界框内,分别是大草原和狮子的鬃毛。
“因果特征是导致图像中对象存在的原因,而抗因素特征是由图像中对象的存在产生的”在我们的例子中,一个因果关系确实是Savanna的视觉模式,而一个反作用的特征将是狮子的鬃毛。
他们是如何进行实验的?首先,我们需要训练一个检测器作为因果方向。这个想法是基于以前的许多工作,实验表明“加性因果模型”可能会在关于因果关系方向的观察数据中留下统计学意义,这反过来可以通过研究高阶矩来检测。(如果这些听起来很陌生,我建议你阅读本文的参考资料)。这个想法是学习如何通过神经网络来捕获这个统计轨迹,该神经网络的任务是区分因果/反效应。
训练这种网络的唯一方法就是对关于因果关系的事实进行标注。这些数据集中并不多。但事实是,这些数据可以很容易地合成,通过采样变量原因-效应和指示方向进行人工标注。
第二,两个版本的图像,无论是对象还是背景消隐,都被标准的深度残留网络特征化。一些对象和上下文被设计在这些特征之上,作为图像是否可能是关于对象或其上下文的信号。

最后我们可以将对象和上下文与形象中的因果关系或反作用关联起来。
通过实验证明了上述猜想,这个实验意味着图像中的因果关系实际上与对象及其上下文之间的差异有关。结果有希望开辟新的研究途径,因为更好的因果方向的算法在原则上将有助于学习在数据分布发生变化时更好的学习特征。因果关系应该有助于通过了解数据生成过程来构建更强大的功能。
第三个成果:使用无监督辅助任务的强化学习
Reinforcement learning with unsupervised auxiliary tasks[Jaderberg et al。ICLR17]根据现行的标准,本文显得有点古老,因为在撰写本文时已经有60篇引文。实际上有一些更新的工作已经建立在这个想法上。我选择这一点,正是因为它具有新颖的洞察力,而不是基于它来讨论更复杂的方法。
第三个成果主角是强化学习。强化学习的研究人员的主要困难是稀缺/延迟奖励。那么为什么不通过引入辅助任务来增强训练信号呢?当然,伪奖励必须与真正的目标相关,而不是借助于人类的监督。
这篇论文的建议是:通过辅助任务的性能总和来增加目标函数(最大化的奖励)。实际上,将有一些模型近似于主要策略和其他完成附加任务的策略;那些模型分享他们的一些参数,例如底层可以共同学习来模拟原始的视觉特征。代理函数必须提高其在奖励方面的绩效,从而提高辅助任务的表现。
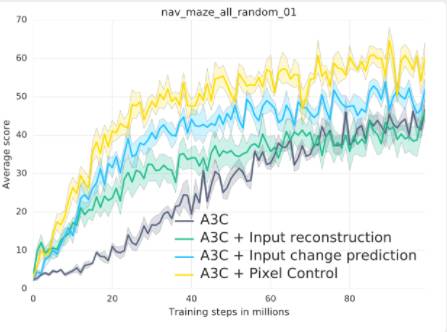
论文探讨的辅助任务:首先,像素控制。代理学习是一个单独的策略,以最大限度地改变输入图像上的像素网格。理由是“感知流中的变化通常与环境中的重要事件相对应”,因此学习控制变化是有益的。二,功能控制。训练该代理以预测策略/价值网络的某些中间层中的隐藏单元的激活值。这个想法很有意思,因为代理的策略或价值网络会提取与环境相关的高级功能的任务。三,奖励预测。代理学会预测即将来临的回报。这三个辅助任务可以通过从之前的代理经验的缓冲区经验回放学习。缩短其他细节,整个方法称为UNREAL。它被应用在Atari游戏和Labyrint上学习更快更好的策略。
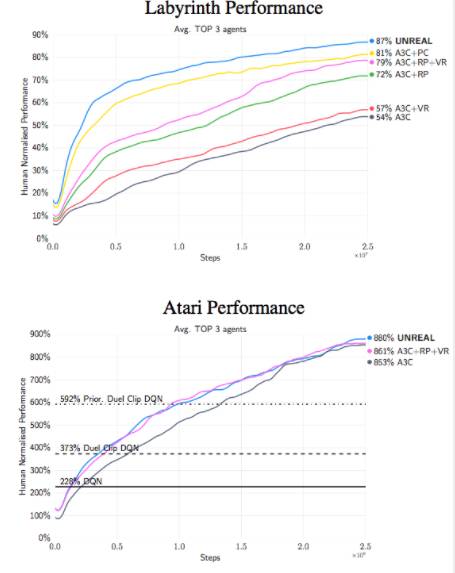
论文中的最终洞察力在于对像素控制的有效性,而不是简单地预测具有重建损耗或像素输入变化的像素。它们都可以被视为视觉自我监督学习的形式。“学习重建只是导致更快的初步学习,实际上会使得最后的成绩更糟。我们的假设是,输入重建会损害最终的表现,因为它将过多的重点放在重建视觉输入的不相关部分而不是视觉线索的奖励。
第四个成果:Self-Play让学习过程更快
Intrinsic motivation and automatic curricula via asymmetric self-play[Sukhbaatar et al。arXiv17].我想强调的最后一个论文与上述强化学习辅助任务的想法有关。但是,至关重要的是,不是明确地调整目标函数,而是在一定程度上对代理进行了训练,以完成自我优化,更简单的自动完成任务。
通过将代理分解为“两个独立的头脑”,Alice 和Bob,建立了Self-Play的初始阶段。论文作者提出Self-Play,假设环境必须可逆或重新设定为初始状态。在这种情况下,Alice执行一个任务,并要求Bob执行相同操作,等到Alice最终达到我们可观察的状态。例如,Alice可以拿起钥匙,打开一扇门,在某个地方关上灯光和停止,Bob必须遵循相同的行动清单并停在同一个地方。最后,你可以想象,这个简单的环境的原始任务是在房间里的一个灯点亮:
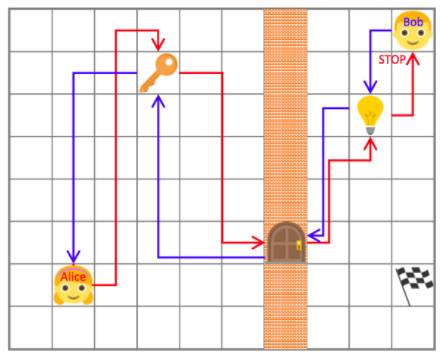
这些任务由Alice设计,迫使Bob学习与环境的互动。而且Alice和Bob有其独特的奖励功能:如果Bob在最短的时间内完成,Bob就会得到回报;而当Bob花费更多的时间,同时能够实现目标时,Alice就会得到回报。这些策略之间的相互作用允许他们“自动构建探索课程”。
他们在星际争霸的上测试了这个想法,没有敌人打架。“目标任务是建造海事单位。为此,代理必须遵循具体的操作顺序:(i)矿工与工人;(ii)积累足够的矿物质供应,建造军营。(iii)军营一旦完成后,将海洋单位列入其中。代理可以训练新的工人来进行更快的采矿,或者建造供应仓库以容纳更多的单元。经过200个步骤,代理为每个海军建造+1。

“由于完全匹配游戏状态几乎是不可能的,Bob的成功只是基于游戏状态,包括每种类型(包括建筑物)的单位数量和积累的矿物资源。所以Bob的自我发挥的目的是在尽可能短的时间内与Alice一起制造尽可能多的单位和矿物。在这种情况下,Self-Play真的有助于加速学习过程,并且更好地融合Reinforce +一个更简单的预训练的基准方法:
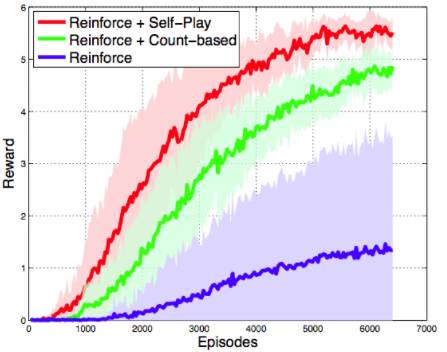
请注意,情节没有考虑到预训练策略所花费的时间。
总结:
无监督学习虽然很难,但是衡量其表现更加困难。在Yoshua Bengio的话中:“我们不知道什么是好的代表,我们没有一个很好的定义,即什么是正确的目标函数,即使衡量一个系统在无人值守学习方面做得很好。”
事实上,几乎所有在无监督学习的模型中都使用监督或强化学习来衡量这些特征是多么有用。
《全球人工智能》开始招人啦!
招聘职位:1名中文编辑(深圳),1名英文编译(深圳),1名课程规划(深圳),4名导师管理(深圳),10名渠道商务 简历发送:mike.yu@aisdk.com




