神经语言模型的多尺度分析
编者按:最近的研究表明,在单词级的语言建模中,经过良好调整的LSTM基准比复杂的结构表现要好。但是大规模的单词级和字符级的数据集都要训练数以亿计的token,这往往需要大规模的计算资源。那么有没有一种方法能让模型在单一GPU上运行,只需要几天甚至几小时就能达到良好效果呢?Salesforce的研究人员Stephen Merity用标准的LSTM/QRNN模型实现了这一目的。以下是论智对原论文的大致编译,如有不足之处请在文末留言。

语言建模的许多方法都具有新奇复杂的结构。我们采用现有的基于LSTM和QRNN的最先进的词级语言模型,并将它们扩展到更大的词汇表及字符级模型中。经过适当调整后,LSTM和QRNN分别在字符级数据集(Penn Tree-bank, enwik8)和单词级数据集(WikiText-103)上表现出了最佳结果。只用一个GPU,在12小时至2天的时间里即获得了结果。
项目介绍
语言建模(LM)是自然语言处理的基础任务之一,该任务的目的是给定的n个tokens,预测第n+1个token是什么。训练过的语言模型在许多应用中都能发挥作用,包括语音识别、机器翻译、自然语言生成、或是作为下游任务中的通用特征提取器。语言模型可以有不同的粒度,其中的tokens可以是单词、子词(sub-words)或者字符。在实验中,单词级别的模型比字符级别的表现得更好,但是会占用较多的计算内存。如果任务中含有大量词汇,单词级别的模型仍然需要将不常用的单词替换成词汇表之外(OoV)的tokens,而字符级别的模型就不存在这种问题。
对于单词级别的语言模型来说,要理解一个句子表达的含义,可能一两个有代表性的词语就够了。但是一个字符级别的模型需要好几个词语才能辨别。对于这种差异,单词级别和字符级别的模型在训练时都有着不同的结构。而vanilla长短期记忆(LSTM)网络已经被证明能在单次级别的语言模型上发挥出目前为止最佳的性能。在这篇论文中,我们证明了由vanilla RNN(LSTM或QRNN)和自适应softmax组成的标准模型框架能够以多种数据规模针对单词和字符级别的任务进行建模,同时达到最先进的结果。此外,我们还对LSTM和QRNN结构进行了比较,并分析了模型中不同参数的重要性。
模型结构
我们的基础架构基于Merity等人使用的模型,该模型中有一个可训练的嵌入层、一个或多个层叠式循环神经网络和一个Softmax分类器。在Merity等人的论文中,他们评估了两个不同的循环神经网络:LSTM和QRNN。在性能方面,LSTM更胜一筹;而QRNN更能提高GPU的利用率:它用卷积层处理输入的数据,然后在跨通道中应用一个极简的循环池化函数。由于卷积层不依赖之前的输出,因此所有的输入处理都可以分成单个矩阵乘法。虽然循环池化函数是连续的,但它是基于元素的快速操作,要被用于现有的已经准备好的输入上,因此几乎没有任何额外成本。
除此之外,结构还加上了简洁版的时序反向传播(BPTT),这是长连续数据集的必备工具。BPTT不仅能增加准确度,还能提高GPU的利用率。
最后,模型结构还加上了可自适应的softmax,解决大量词汇导致模型速度变慢或占用GPU内存而无法训练模型的问题。
数据集对比
试验在三个数据集上进行,两个字符级数据集(Penn Treebank和enwik8),一个大型单词级数据集(WikiText-103)。
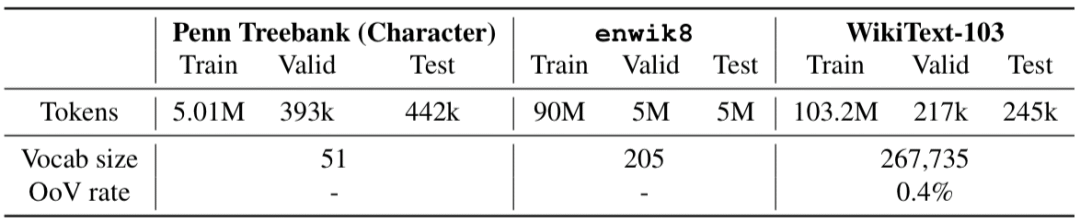
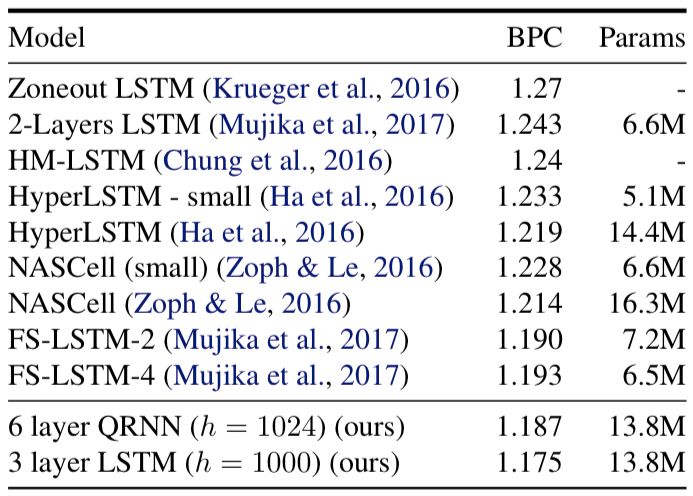
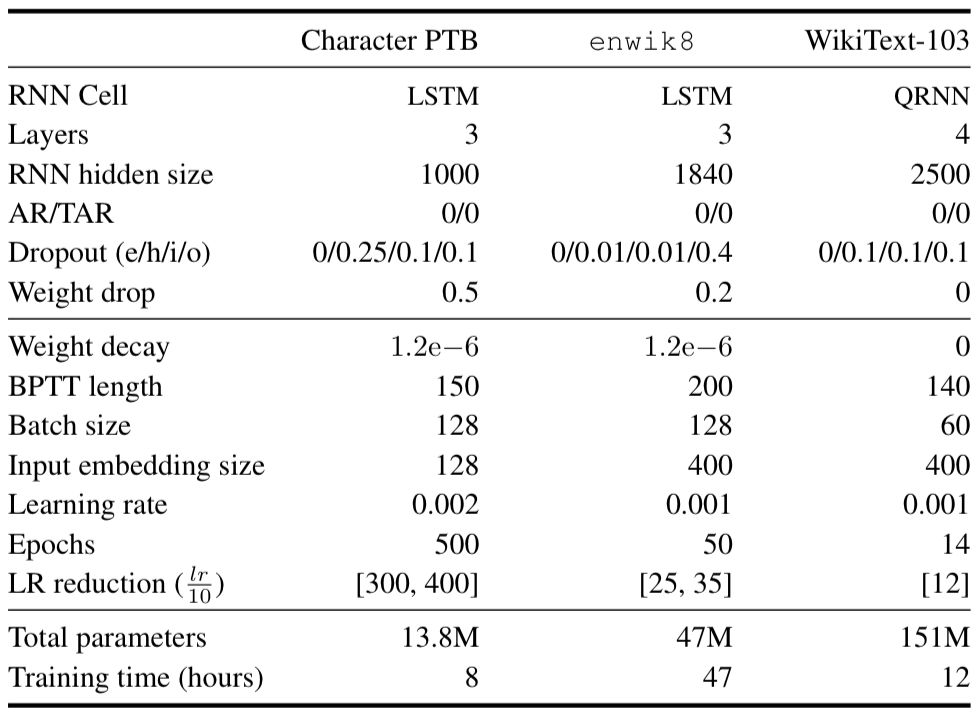
在Mikolov等人的论文中,Penn Treebank数据集经过处理后可生成字符级别的语言模型数据集,该数据集由单词和字符两种形式。最初,该数据集由《华尔街日报》的文章组成,预处理过程删去了许多可能会影响建模的特征。模型用了一个三层的LSTM和长度为150的BPTT,嵌入的尺寸为200,隐藏层的尺寸为1000。下表显示了模型在Penn Treebank数据集上的实验结果:
Hutter Prize Wikipedia数据集(即enwik8)是一个字节级数据集,有维基百科XML转储的前一亿字节组成。在该数据集上,模型使用了三层LSTM,BPTT的长度为200,嵌入尺寸400,隐藏层尺寸为1850。最终实验结果如下:
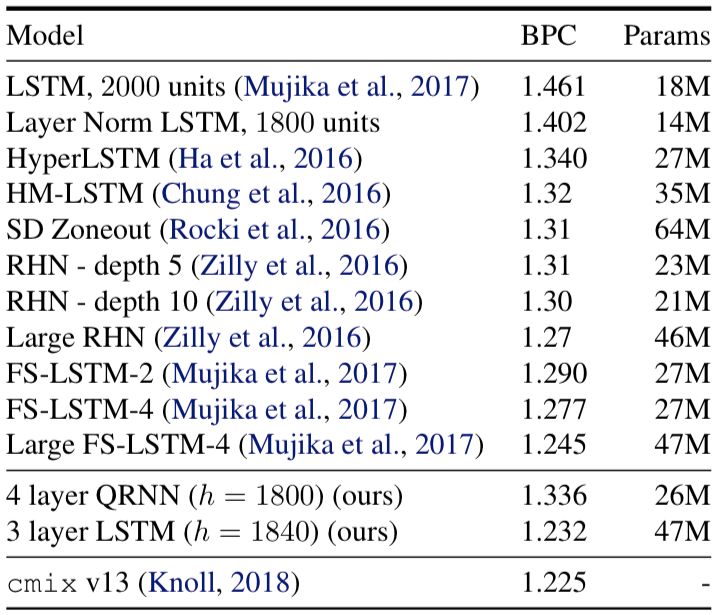
该数据集比字符级的Penn Treebank更具挑战性,enwik8的训练token数量比Penn Treebank增加了18倍,并且数据没有进行预处理。
最后,WT-103数据集包含1.03亿单词,其中是对维基百科文章进行了轻微预处理。由于维基百科的文章相对较长,并且专注于单一主题,因此捕获和利用长期依赖关系是让模型拥有强大性能的关键。

分析
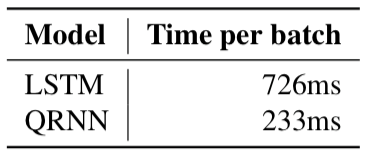
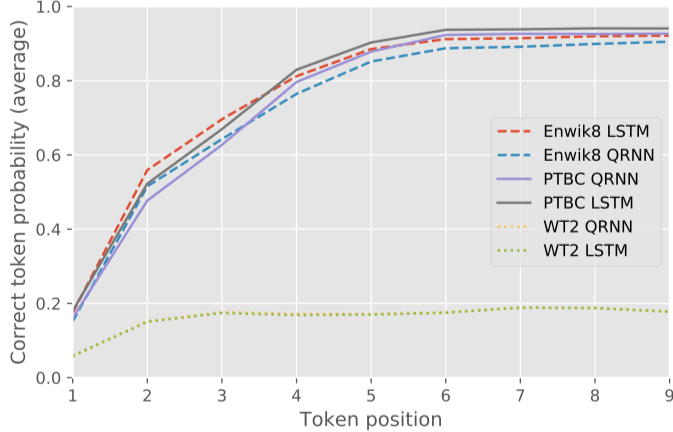
QRNN vs LSTM
QRNN和LSTM以完全不同的方式对顺序数据进行操作。对于单次级别的语言模型,QRNN能用LSTM的一小部分成本进行类似的训练和泛化。然而,在我们的工作中,我们发现QRNN在字符级任务中不太成功,即使进行了大量超参数调整。下图是LSTM和QRNN在单词级和字符级任务中的表现比较:
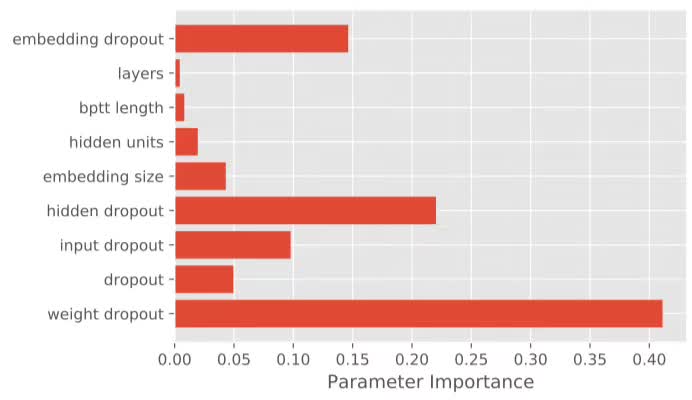
超参数的重要性
如果神经语言模型中的超参数数量较多,那么模型在应对新数据集时的调整是非常费时费力的。为了研究超参数的重要性,我们用随机参数训练了200个模型,然后用随机森林MSE对其进行回归。随机森林的特征重要性就代表了超参数的重要性。
结语
快速且易调整的标准是做研究的重要部分,没有这些标准,我们就无法准确判断研究的进展。通过扩展现有的基于LSTM和QRNN的语言模型,我们发现调整好的模型可以在字符级数据集和单词级数据集上得到最好的结果,而不用定制复杂的结构。
论文地址:arxiv.org/pdf/1803.08240.pdf




