博客 | 机器学习算法系列(一):logistic回归


作者 | Ray
编辑 | 安可
出品 | 磐创AI技术团队
目录:
一、Logistic分布
二、二项Logistic回归原理
三、参数估计
四、Logistic回归的正则化
五、Logistic回归和线性回归区别
六、为什么Logistic回归的输入特征一般都是离散化而不是连续的?
七、Logistic回归和SVM的关系
一、Logistic分布
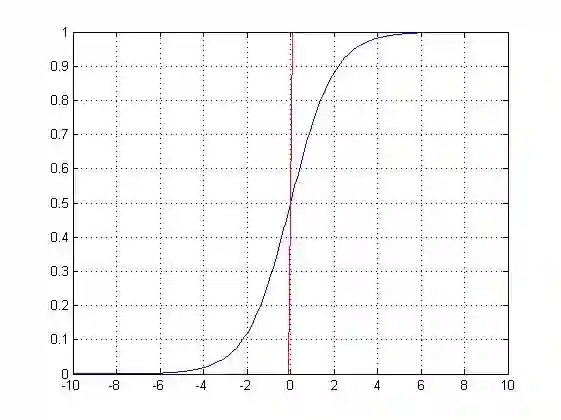
定义:X是连续随机变量,X服从logistic分布,则X具有下列的分布函数和密度函数:
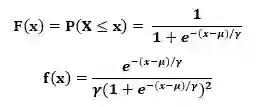
其中,μ为位置参数,γ为形状参数
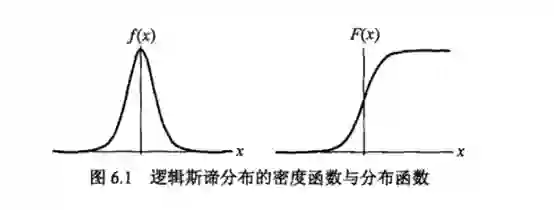
曲线在中心附近增长速度较快,并且γ值越小,曲线在中心附近的增长速度越快。
特别的,当μ=0,γ=1的时候就是sigmoid函数。
二、二项Logistic回归原理
二项Logistic回归模型时一种分类模型,由条件概率分布P(Y|X)表示,随机变量Y取0或1。
定义二项logistic回归模型的条件分布如下:
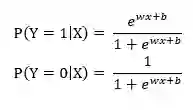
其中x∈Rn是输入,Y∈{0,1}是输出,W∈Rn和b∈R是参数,w称为权重,b称为偏置。
有时为了方便会将权重向量和输入向量进行扩充:
w = (w1,w2, …, wn, b)T, x = (x1,x2, …, xn, 1)T
所以,logistic回归模型变为:
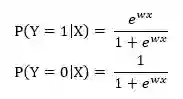
得到概率之后,我们可以通过设定一个阈值将样本分成两类。如:阈值为0.5的时候,当大于0.5则为一类,小于0.5为另一类。
三、参数估计
有了以上的模型,我们就需要对模型中的参数w求出来。我们可以使用极大似然估计法估计模型的参数。
设:
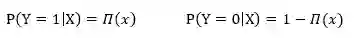
似然函数为:
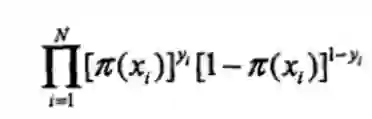
对数似然函数:
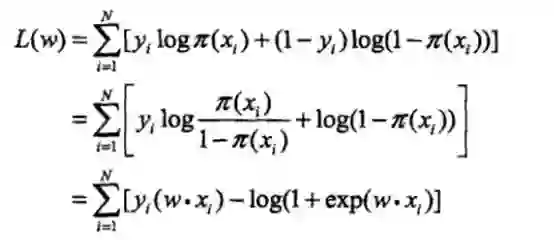
对L(w)求极大值,得到w的估计值。通常采用梯度下降法或拟牛顿法求解参数w。
四、Logistic回归的正则化
正则化是为了解决过拟合问题。分为L1和L2正则化。目标函数中加入正则化,即加入模型复杂性的评估。正则化符合奥卡姆剃刀原理,即:在所有可能的模型中,能够很好的解释已知数据并且十分简单的模型才是最好的模型。
加入正则化后,模型的目标函数变为:

P表示范数,p=1为L1正则化,p=2为L2正则化
L1正则化:向量中各元素绝对值的和。关键在于能够对特征进行自动选择,稀疏参数可以减少非必要的特征引入噪声。
L2正则化:向量中个元素的平方和,L2会使得各元素尽可能小,但都不为零。
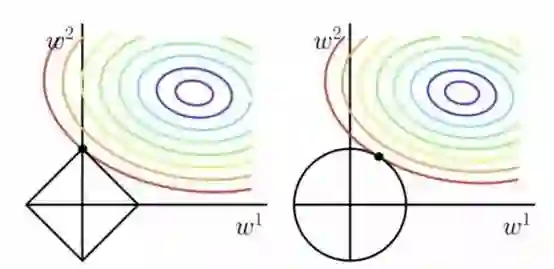
左边为L1正则化,右边为L2正则化。假设权重参数w只有二维w1和w2。L1为各元素绝对值和,即|w1|+|w2| = C,则得到的形状为棱形,L2为(w1)^2+(w2)^2 = C,则形状为圆。很容易可以发现L1更容易在顶点处相切,L2则不容易在顶点处相切。顶点处则其中一个参数为0,这就是为什么L1会使得参数稀疏的原因。
五、Logistic回归和线性回归区别
1. Logistic回归在线性回归的实数输出范围加上sigmoid函数,将输出值收敛在0~1之间。其目标函数也因此从差平方和函数变为对数损失函数。
2. 逻辑回归和线性回归都是广义的线性回归,线性回归是使用最小二乘法优化目标函数,而逻辑回归是使用梯度下降或者拟牛顿法。
3. 线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围需要在[0,1]。逻辑回归是一种减少预测范围,将预测值限定为[0,1]间的一种回归模型。因而对于二分类问题,逻辑回归的鲁棒性更好。
4. 逻辑回归是以线性回归为理论支持的,但线性回归模型无法做到sigmoid的非线性形式。Sigmoid可以轻松处理0/1分类问题。
六、为什么Logistic回归的输入特征一般都是离散化而不是连续的?
1. 离散特征容易增加和减少,使得模型容易迭代。
2. 离散特征的内积运算速度快,计算结果方便存储。
3. 对异常值不敏感,比如一个特征是年龄>30为1,否则为0,如果特征没有离散化。一个异常数据300岁会给模型带来很大的干扰。
4. 逻辑回归是广义线性模型,表达能力受限。单变量离散化为N个后,每个变量都有单独的权重,相当于为模型引入了非线性,能够提升模型的表达能力,加大拟合。
5. 特征离散化后可以进行特征交叉,由M+N变量变为M*N个变量,进一步引入非线性,提升表达能力。
6. 特征离散化后,模型会更加稳定。比如对用户年龄离散化,将20~30作为一个区间,这样不会因为一个用户年龄大了一岁就变成完全不同的人了,当然处于区间相邻处的样本就刚好相反,所以怎么划分区间是们学问。
7. 特征离散化后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
七、Logistic回归和SVM的关系
1. LR和SVM都可以处理分类问题,且一般都处理线性二分类问题。
2. LR是参数模型,SVM是非参数模型。
3. LR的目标函数是对数似然函数,SVM的目标函数是hinge损失函数。这两个函数都是增加对分类结果影响较大的数据点的权重,减少影响较小的数据点的权重。
4. SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
5. 逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
6. logic能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
欢迎扫码关注磐创AI微信公众号


点击 阅读原文,查看更多内容