深入机器学习系列之:Random Forest


导读
随机森林算法在单机环境下很容易实现,但在分布式环境下特别是在Spark平台上,传统单机形式的迭代方式必须要进行相应改进才能适用于分布式环境。

来源:星环科技
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

Bagging
Bagging采用自助采样法(bootstrap sampling)采样数据。给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时,样本仍可能被选中, 这样,经过m次随机采样操作,我们得到包含m个样本的采样集。
按照此方式,我们可以采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基本学习器,再将这些基本学习器进行结合。这就是Bagging的一般流程。在对预测输出进行结合时,Bagging通常使用简单投票法, 对回归问题使用简单平均法。若分类预测时,出现两个类收到同样票数的情形,则最简单的做法是随机选择一个,也可以进一步考察学习器投票的置信度来确定最终胜者。
Bagging的算法描述如下图所示。

随机森林
随机森林是Bagging的一个扩展变体。随机森林在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来讲,传统决策树在选择划分属性时, 在当前节点的属性集合(假设有d个属性)中选择一个最优属性;而在随机森林中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。 这里的参数k控制了随机性的引入程度。若令k=d,则基决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分。在MLlib中,有两种选择用于分类,即k=log2(d)、k=sqrt(d); 一种选择用于回归,即k=1/3d。在源码分析中会详细介绍。
可以看出,随机森林对Bagging只做了小改动,但是与Bagging中基学习器的“多样性”仅仅通过样本扰动(通过对初始训练集采样)而来不同,随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动。 这使得最终集成的泛化性能可通过个体学习器之间差异度的增加而进一步提升。
随机森林在分布式环境下的优化策略
随机森林算法在单机环境下很容易实现,但在分布式环境下特别是在Spark平台上,传统单机形式的迭代方式必须要进行相应改进才能适用于分布式环境 ,这是因为在分布式环境下,数据也是分布式的,算法设计不得当会生成大量的IO操作,例如频繁的网络数据传输,从而影响算法效率。 因此,在Spark上进行随机森林算法的实现,需要进行一定的优化,Spark中的随机森林算法主要实现了三个优化策略:
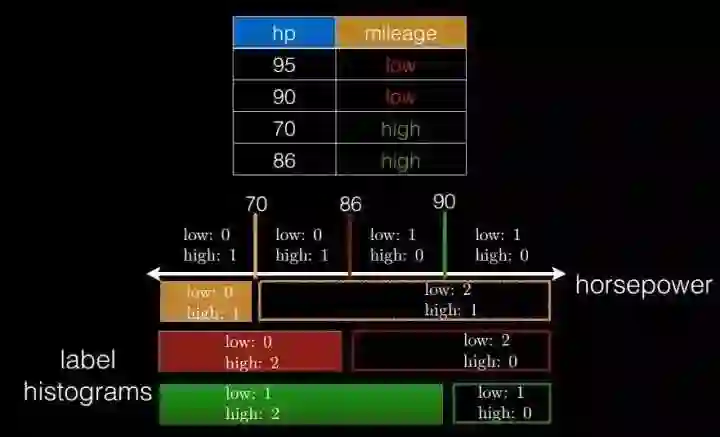
1). 切分点抽样统计,如下图所示。在单机环境下的决策树对连续变量进行切分点选择时,一般是通过对特征点进行排序,然后取相邻两个数之间的点作为切分点,这在单机环境下是可行的,但如果在分布式环境下如此操作的话, 会带来大量的网络传输操作,特别是当数据量达到PB级时,算法效率将极为低下。为避免该问题,Spark中的随机森林在构建决策树时,会对各分区采用一定的子特征策略进行抽样,然后生成各个分区的统计数据,并最终得到切分点。 (从源代码里面看,是先对样本进行抽样,然后根据抽样样本值出现的次数进行排序,然后再进行切分)。

2). 特征装箱(Binning),如下图所示。决策树的构建过程就是对特征的取值不断进行划分的过程,对于离散的特征,如果有M个值,最多有2^(M-1) - 1个划分。如果值是有序的,那么就最多M-1个划分。 比如年龄特征,有老,中,少3个值,如果无序有2^2-1=3个划分,即老|中,少;老,中|少;老,少|中。;如果是有序的,即按老,中,少的序,那么只有m-1个,即2种划分,老|中,少;老,中|少。 对于连续的特征,其实就是进行范围划分,而划分的点就是split(切分点),划分出的区间就是bin。对于连续特征,理论上split是无数的,在分布环境下不可能取出所有的值,因此它采用的是切点抽样统计方法。
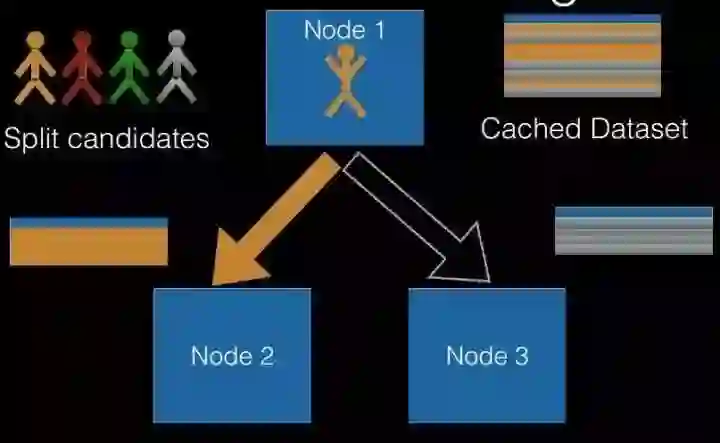
3). 逐层训练(level-wise training),如下图所示。单机版本的决策树生成过程是通过递归调用(本质上是深度优先)的方式构造树,在构造树的同时,需要移动数据,将同一个子节点的数据移动到一起。 此方法在分布式数据结构上无法有效的执行,而且也无法执行,因为数据太大,无法放在一起,所以在分布式环境下采用的策略是逐层构建树节点(本质上是广度优先),这样遍历所有数据的次数等于所有树中的最大层数。 每次遍历时,只需要计算每个节点所有切分点统计参数,遍历完后,根据节点的特征划分,决定是否切分,以及如何切分。
使用实例
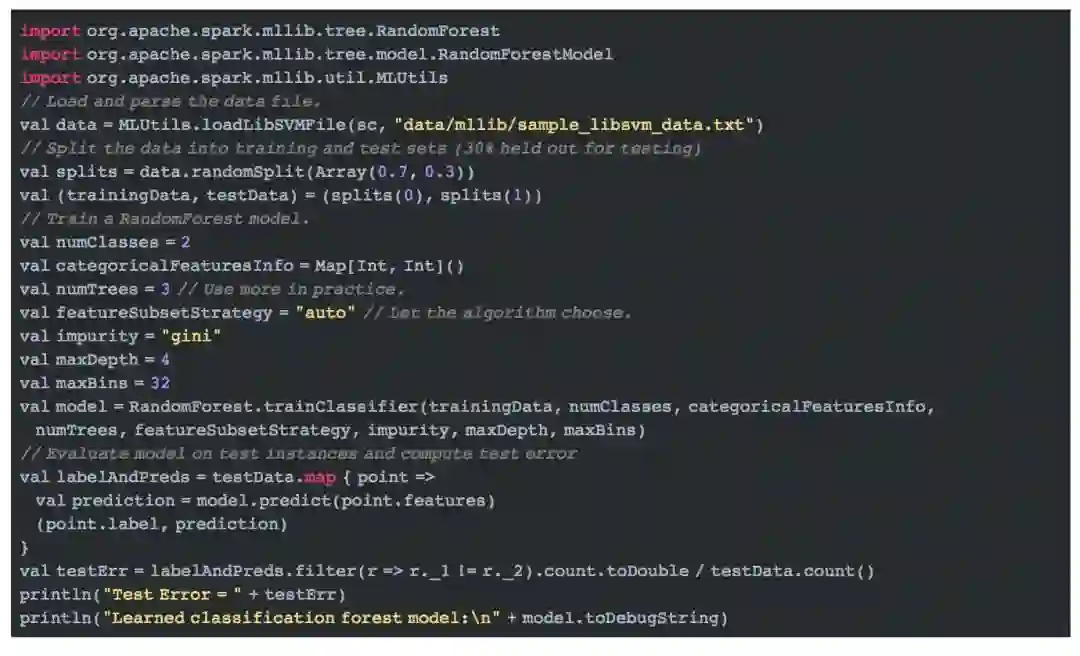
下面的例子用于分类。
(提示:代码块部分可以左右滑动屏幕完整查看哦)
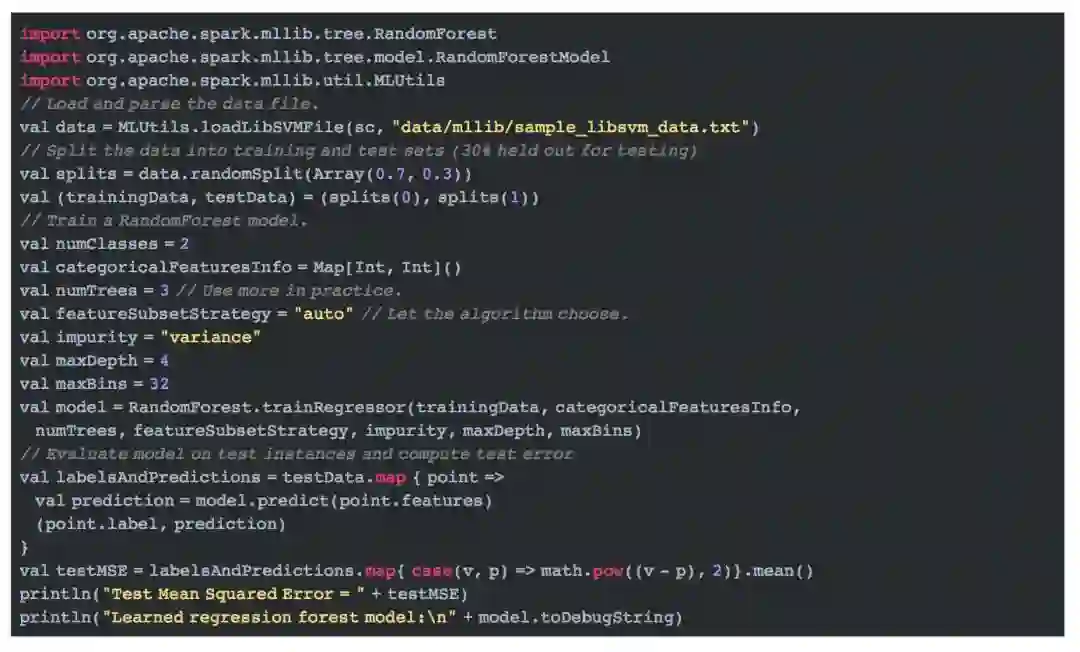
下面的例子用于回归。
源码分析
1 训练分析
训练过程简单可以分为两步,第一步是初始化,第二步是迭代构建随机森林。这两大步还分为若干小步,下面会分别介绍这些内容。
1.1 初始化
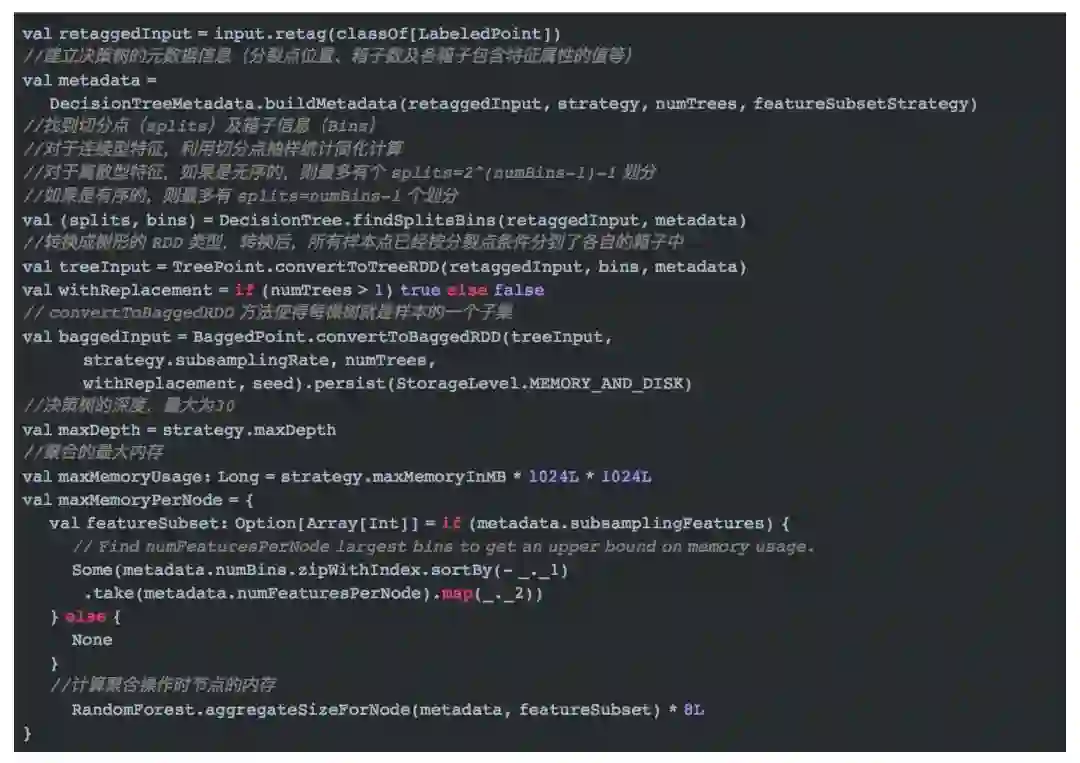
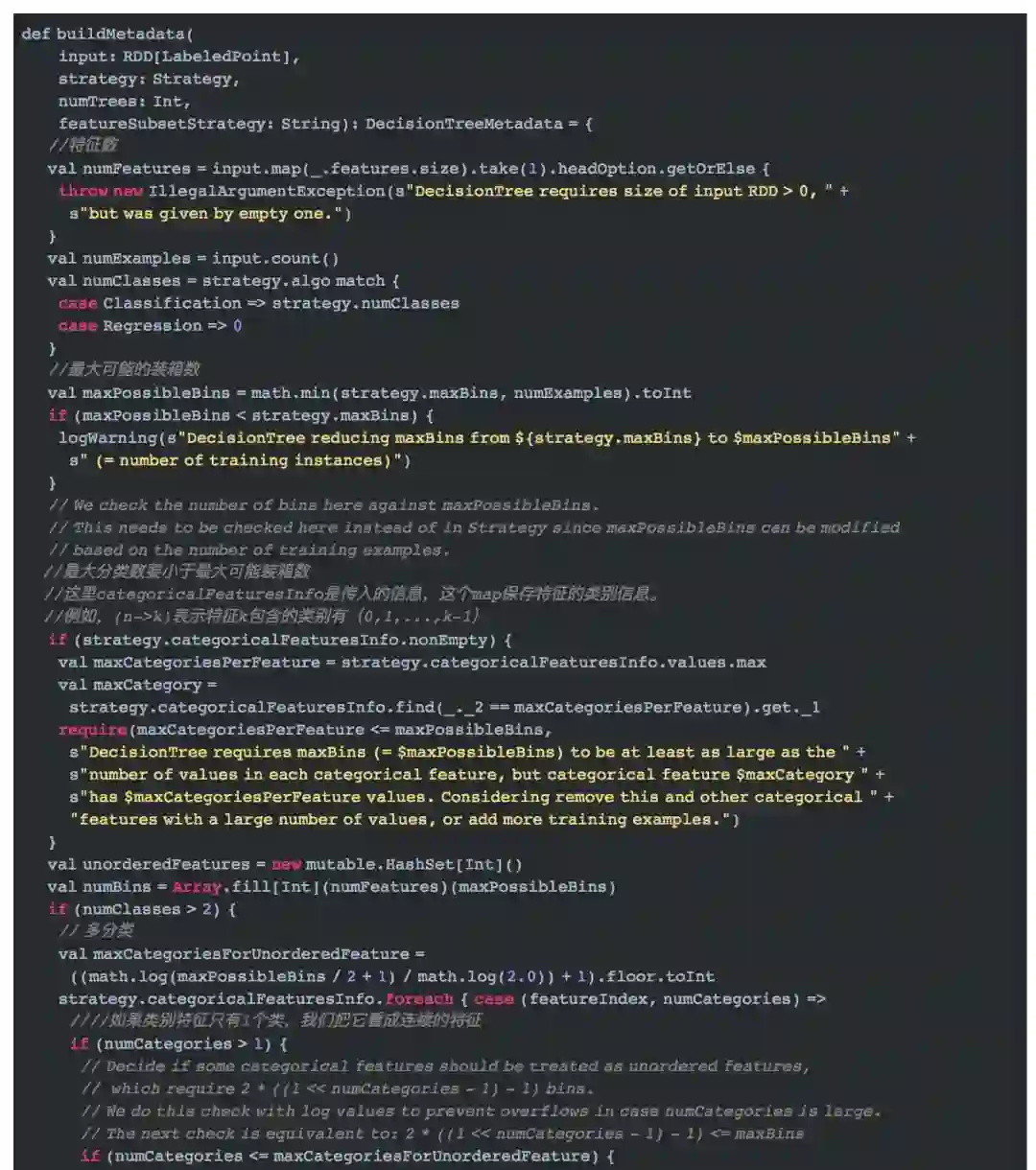
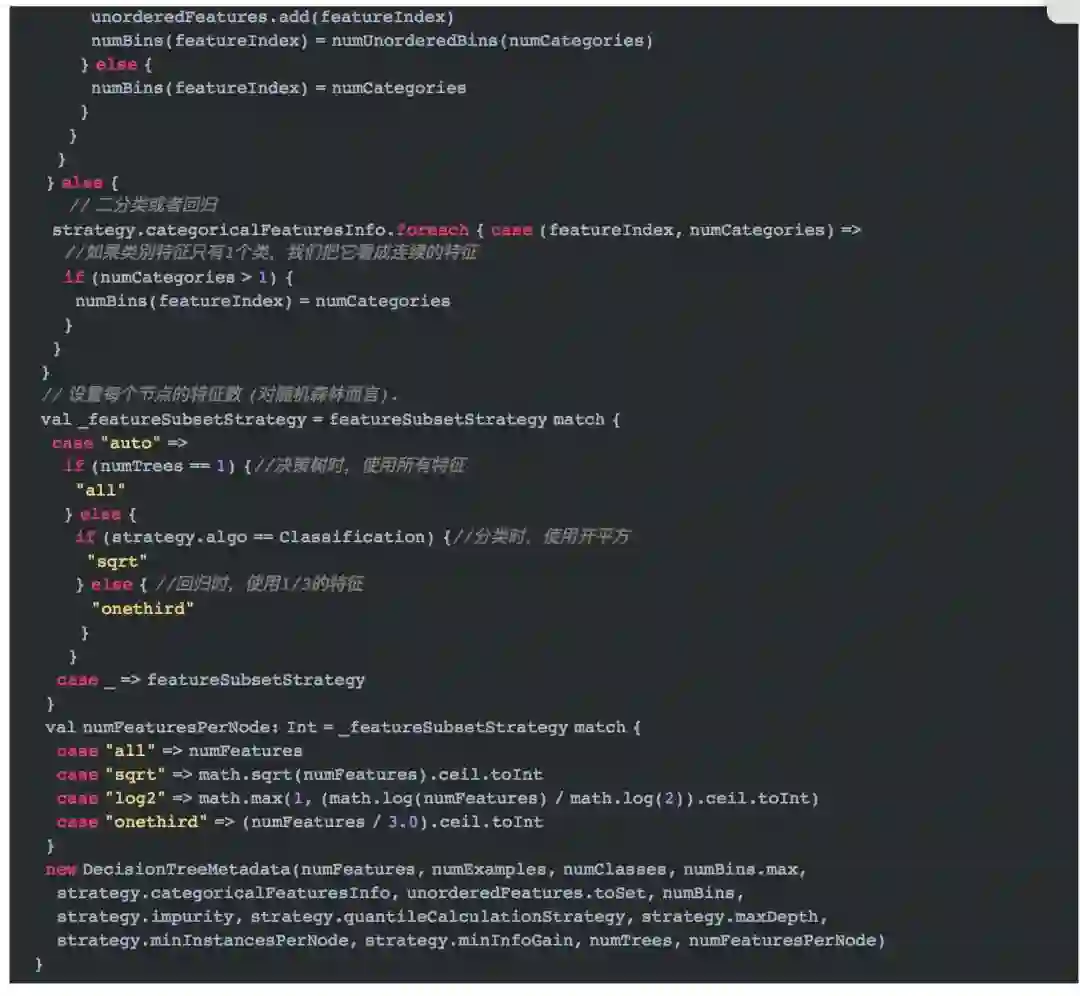
初始化的第一步就是决策树元数据信息的构建。它的代码如下所示。
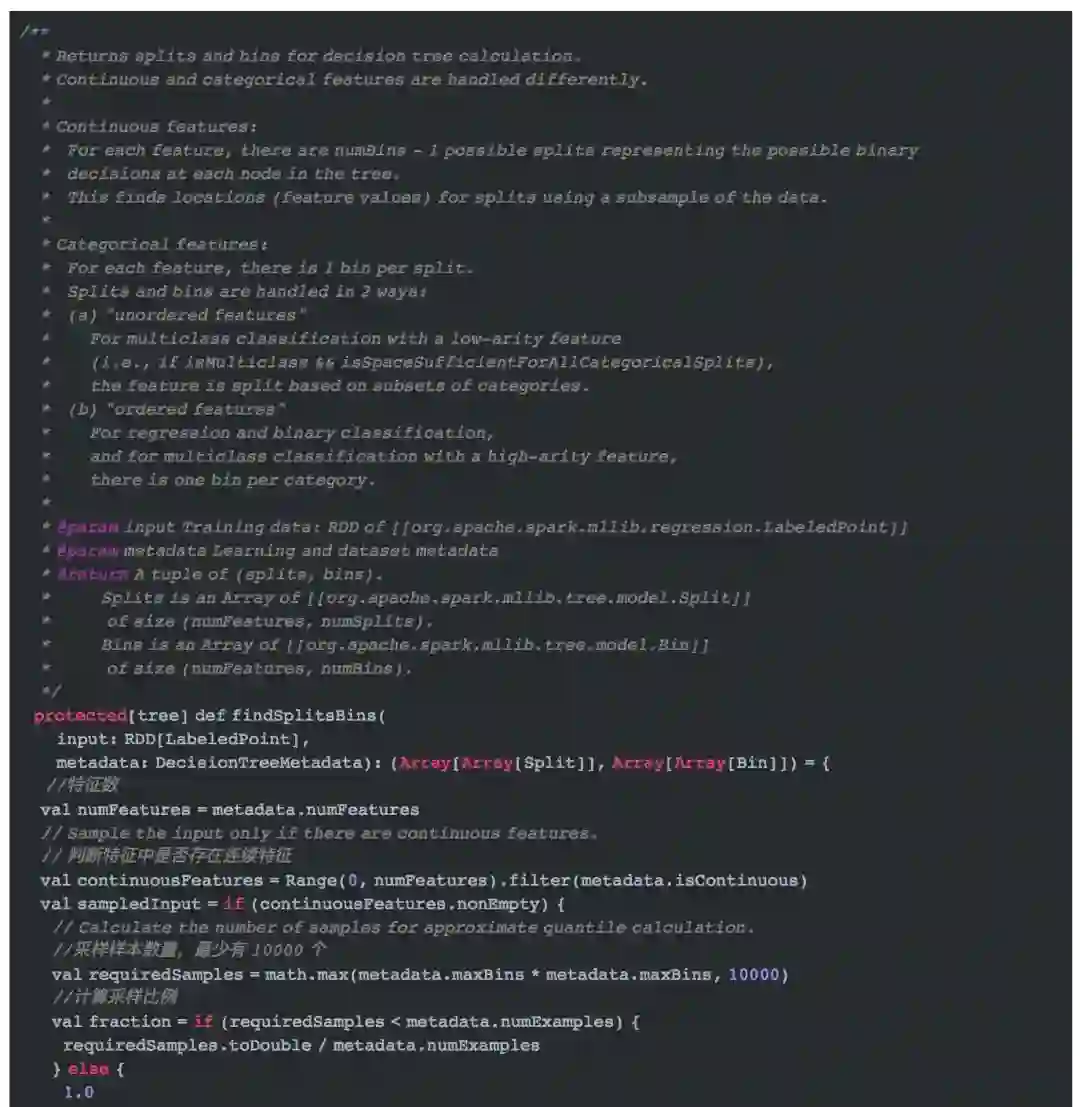
初始化的第二步就是找到切分点(`splits`)及箱子信息(`Bins`)。这时,调用了`DecisionTree.findSplitsBins`方法,进入该方法了解详细信息。

我们进入findSplitsBinsBySorting方法了解Sort分裂策略的实现。
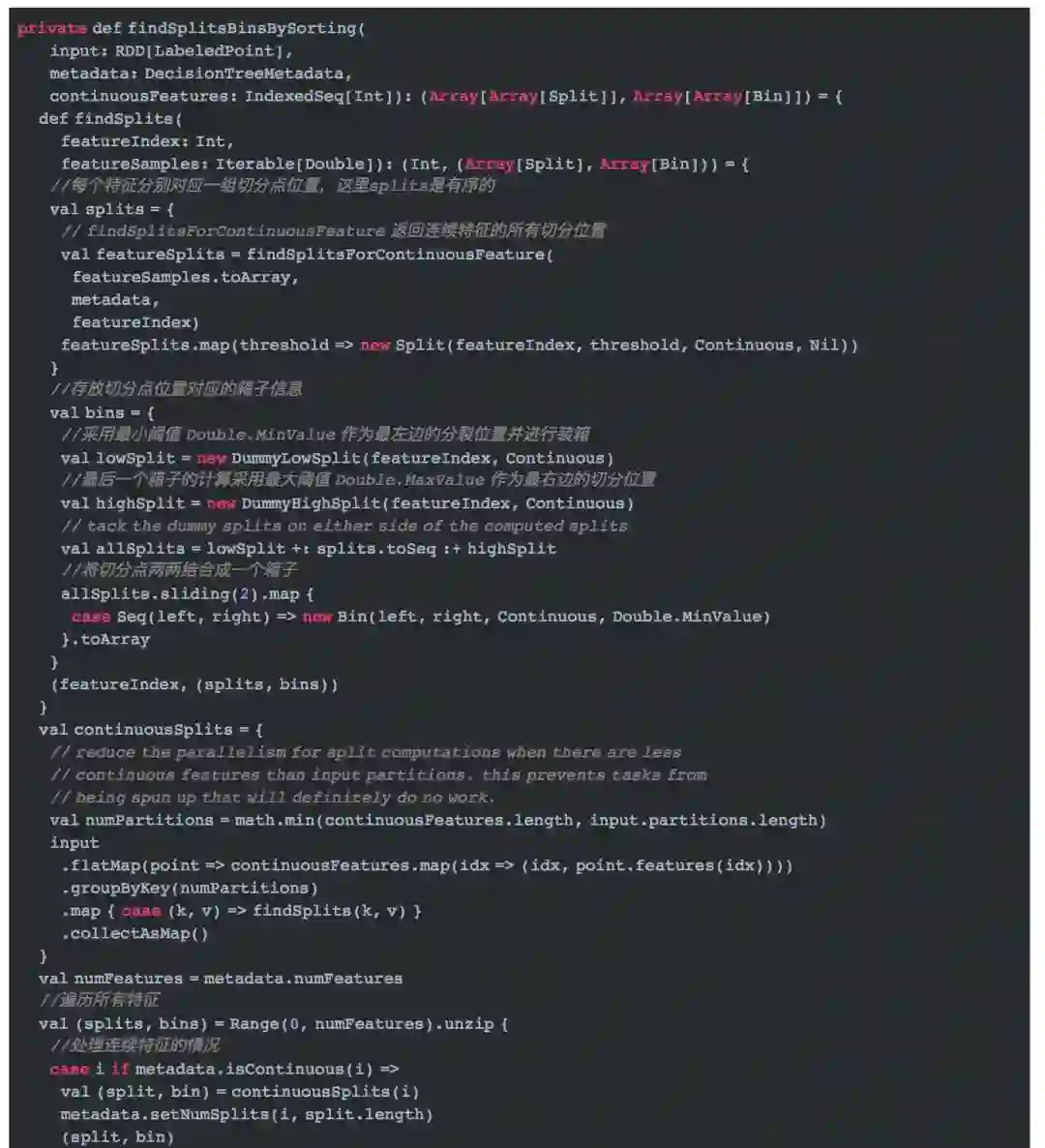
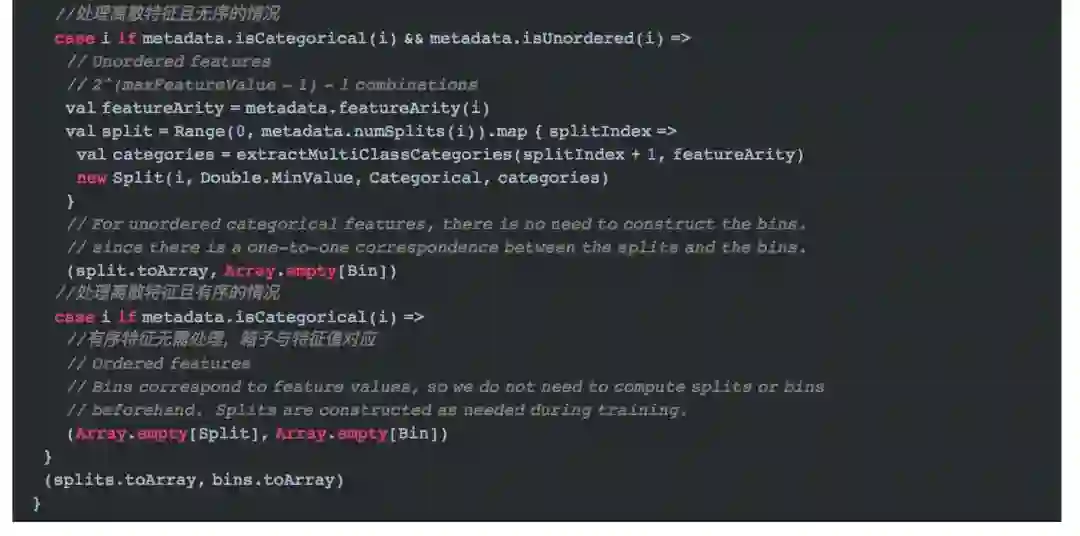
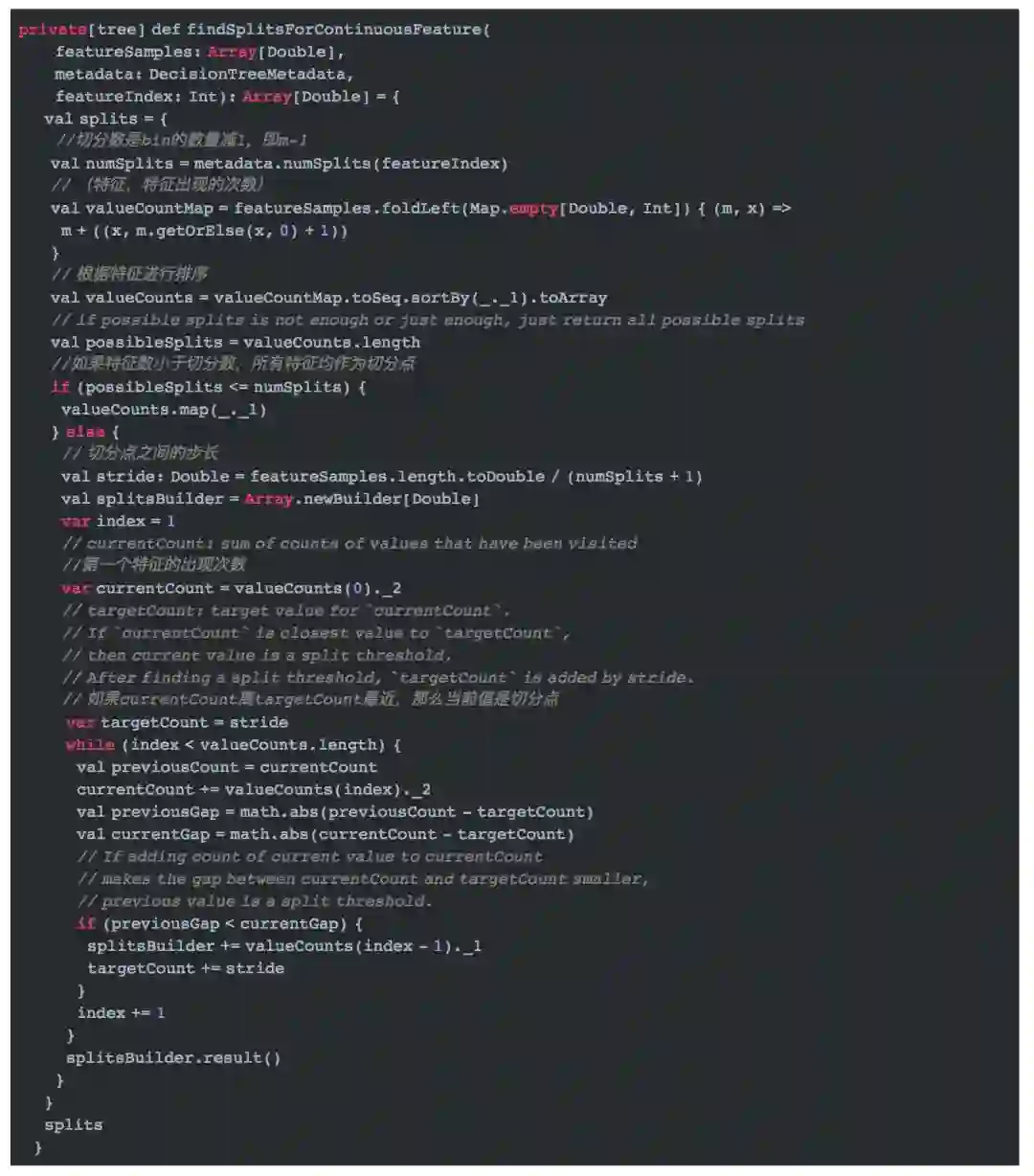
计算连续特征的所有切分位置需要调用方法`findSplitsForContinuousFeature`方法。
1.2 迭代构建随机森林
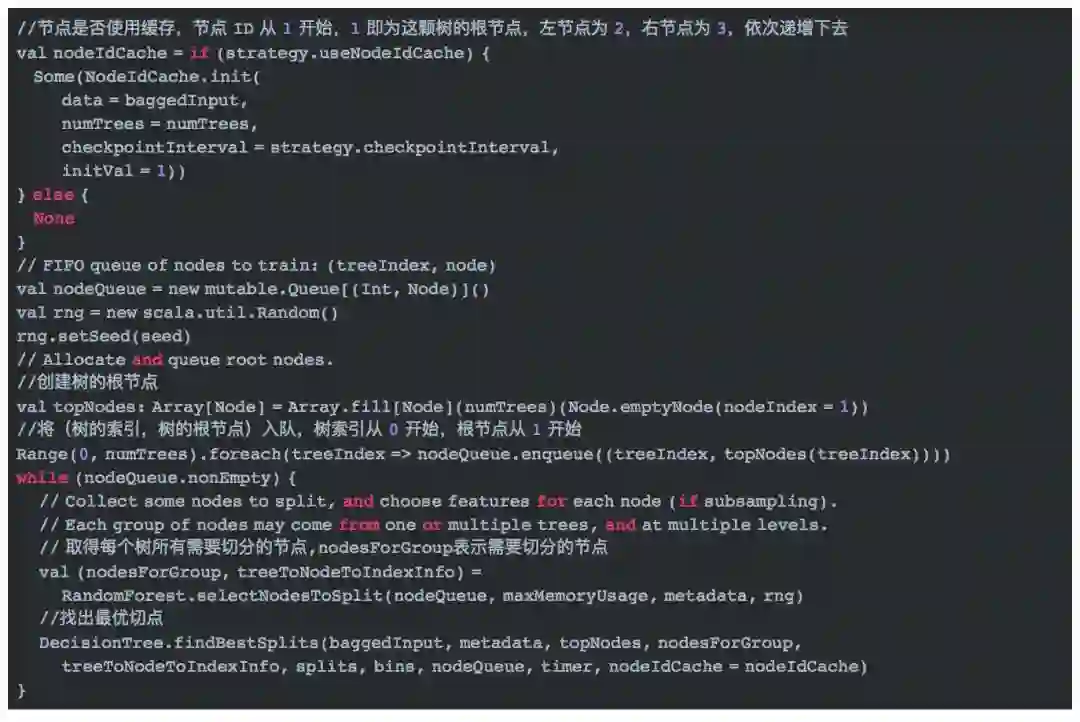
这里有两点需要重点介绍,第一点是取得每个树所有需要切分的节点,通过RandomForest.selectNodesToSplit方法实现;第二点是找出最优的切分,通过DecisionTree.findBestSplits方法实现。下面分别介绍这两点。
-
取得每个树所有需要切分的节点
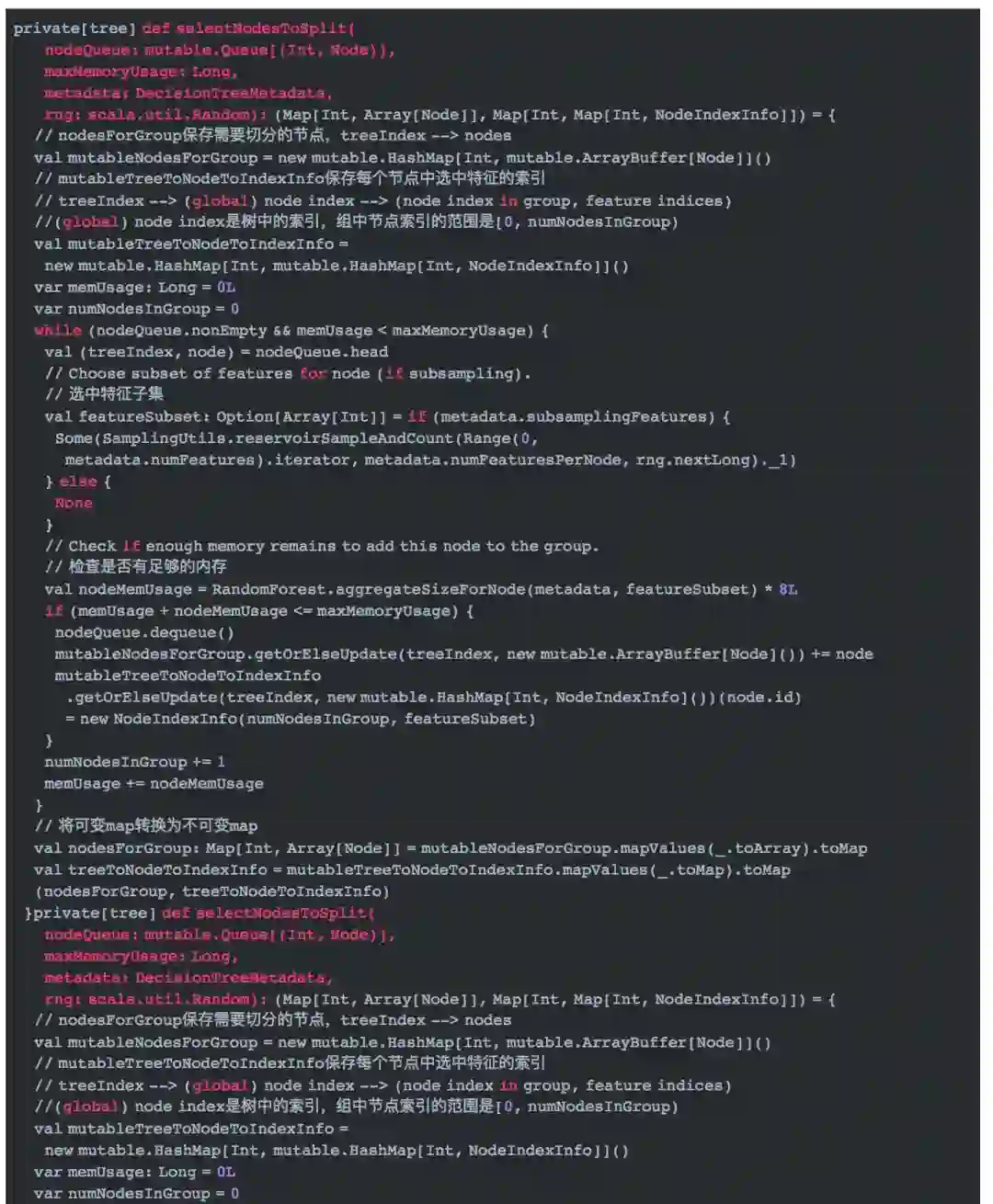
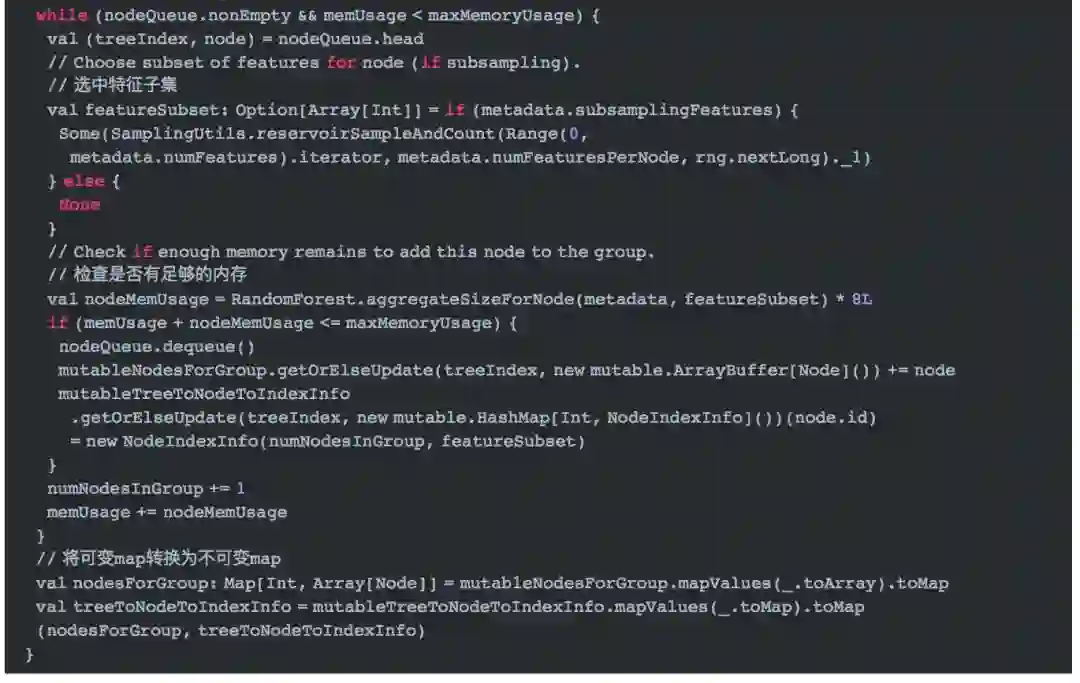
-
选中最优切分

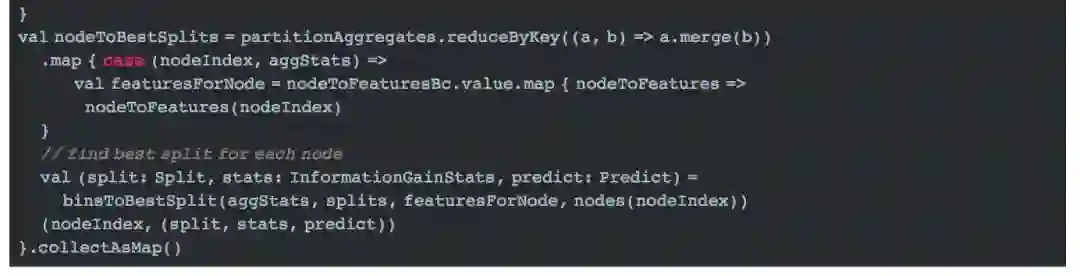
2 预测分析
在利用随机森林进行预测时,调用的predict方法扩展自TreeEnsembleModel,它是树结构组合模型的表示,其核心代码如下所示:










