VizWiz数据集:用计算机视觉回答盲人的问题
计算机视觉的应用可以用来帮助盲人,无论是改善视力缺陷还是打破社交障碍。例如TapTapSee和CamFind等物体识别工具可以让人们拍摄图像,并识别目标物体是什么,以及哪里能买到。另外,Facebook和Twitter推出的新功能可以识别和标记图片中的好友,让人们与朋友保持联系。计算机视觉应用的下一个理想目标是让有视力障碍的人更自然地接收到关于周围世界的信息。这一目标的出现引起了人们对通用视觉问题解答(visual question answering)的兴趣,该问题旨在准确地回答任何有关图像的问题。
在过去三年里,计算机视觉领域已经涌现出了14种VQA数据集,但他们都是人工创建设置的,并且没有一个数据集的图片是来自盲人的或服务于盲人的。然而,可以这么说,盲人能够产生训练算法所需的大量数据。近十年来,盲人群体通过拍照询问他们拍的是什么,并且盲人通常是计算机视觉技术早期的使用者,这项技术将为他们的生活带来极大的便利。
中国科学技术大学和美国卡内基梅隆大学等高校的研究人员共同提出了第一个由盲人产生的视觉数据库“VizWiz”,他们通过数据库创建了一个手机程序,可以让盲人通过拍照和询问得到超过七万个问题的答案。数据集刚开始构建时严格对内容进行过滤,消除有可能侵犯个人隐私的视觉问题。之后通过众包获取图像的答案来训练和评估算法,接着通过实验对图像进行特征分类、问题回答,最终发现了VizWiz与其他现有VQA数据集不同的地方。
VizWiz介绍
该VQA数据集由盲人提出的视觉问题组成,在四年时间里积累了72205个问题。表一总结了VizWiz收集数据的过程与其他数据库的不同,其中明显的区别是VizWiz包含来自盲人摄影师的图像,并且提问方式是口头而非文字。
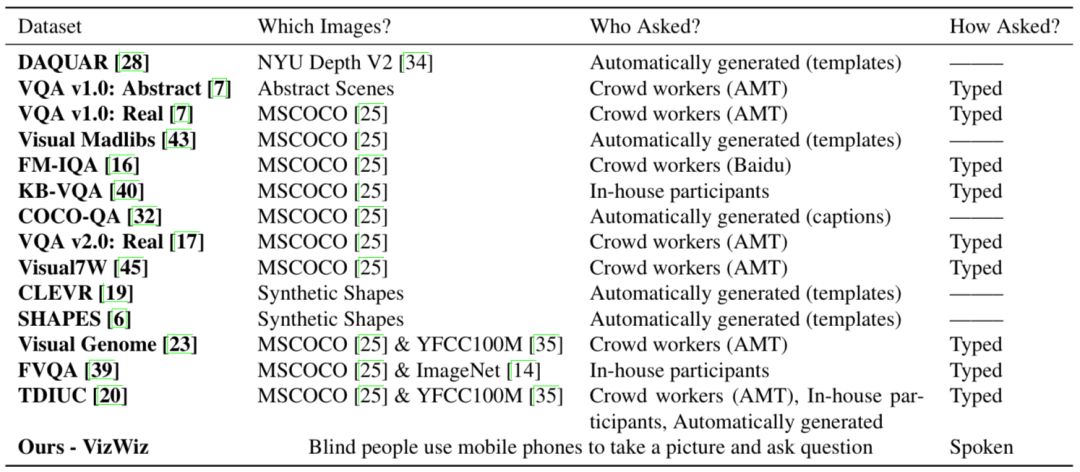
表一
这种图像质量带来了一般数据集中没有的挑战,例如会有大量的模糊、光线不足、图像内容缺失等。另外,因为“提问者”也是“拍摄者”,所以有时问题可能与图像无关,如图所示。

在对数据集的图像进行筛选时,研究人员将可能会泄露隐私的图片分成以下几类:
暴露个人信息,例如人脸、财务状况、药品处方。
某个地点,例如邮箱地址、商业地点。
不雅内容,例如裸体、亵渎。
可疑的复杂场景,审查人员怀疑其中可能包括个人信息,但没有找到明确的地方。
可疑的低质量图像,审查人员怀疑增强图像质量可能会暴露个人信息。
最终,研究人员通过IQ引擎、Facebook、Twitter或电子邮件公开接收图像的答案。
VizWiz数据库分析
接着,研究人员将对VizWiz中的问题和答案进行可视化,他们分析了自然语言问题的类型、图像都有哪几类、答案分为哪几类以及视觉问题无法回答的情况。
首先,问题的类别如下图所示:
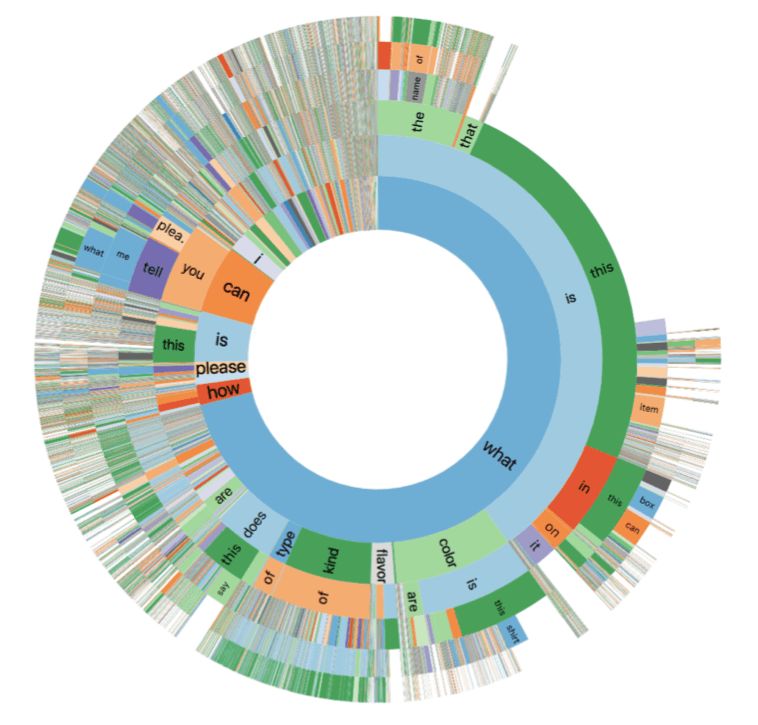
表中统计了所有问题的前六个字母。最内环代表第一个字母,以此类推。可以看出,“这是什么?(What is this)”这个问题是最常见的。
然后,我们来分析数据库中的图像多样性。尤其值得关注的是,我们的数据集中高质量的图像可以显示单个标志性的对象,因为在收集时过滤掉了可疑图像。在之前工作的基础上,我们首先计算了VizWiz中所有图像的平均图像。如下图所示:

接着,我们来分析答案的多样性。我们首先用词汇地图将不同答案进行可视化,如下图所示:

文字越大,答案出现的频率就越高。
VizWiz评估结果
研究人员用现有算法测试了VizWiz数据集的难度。首先是用现代VQA算法预测VizWiz数据集中视觉问题的答案,结果如下表所示:
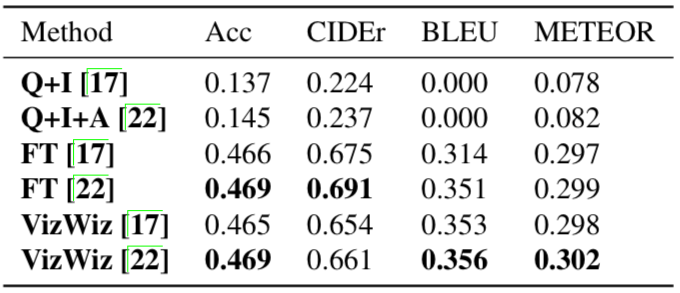
可以看出前两行的表现非常糟糕,而VizWiz的表现还是不错的。
接着他们测试了算法是够能区分某一问题是否可答的精确度,结果如下图所示:
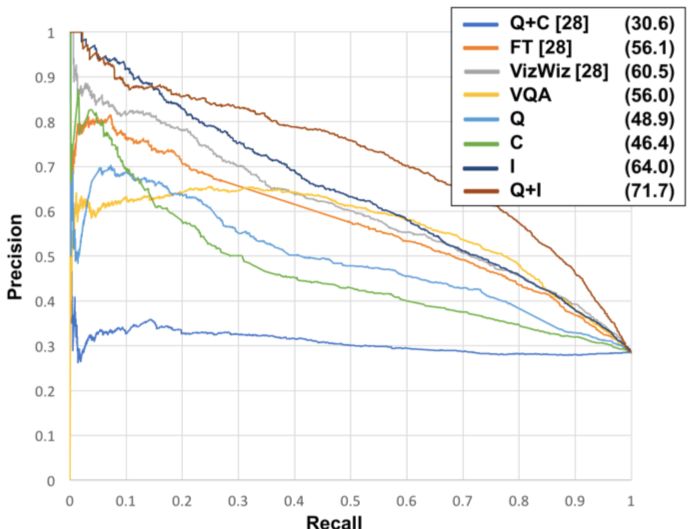
结果可见,研究人员提出的方法比现有方法的精确度提高了至少25%。
结语
在这篇论文中,研究人员介绍了一种VQA数据集——VizWiz,与一般数据集不同的是,其中的内容都来自盲人拍摄的图片,并由盲人对内容进行提问。通过对数据集的分析,研究人员对计算机视觉以及自然语言处理又有了新的认识。更重要的一点是,VizWiz的出现能让更多人关注针对盲人的技术需求,为开发专门的技术提供了新机会。
论文地址:arxiv.org/pdf/1802.08218.pdf







