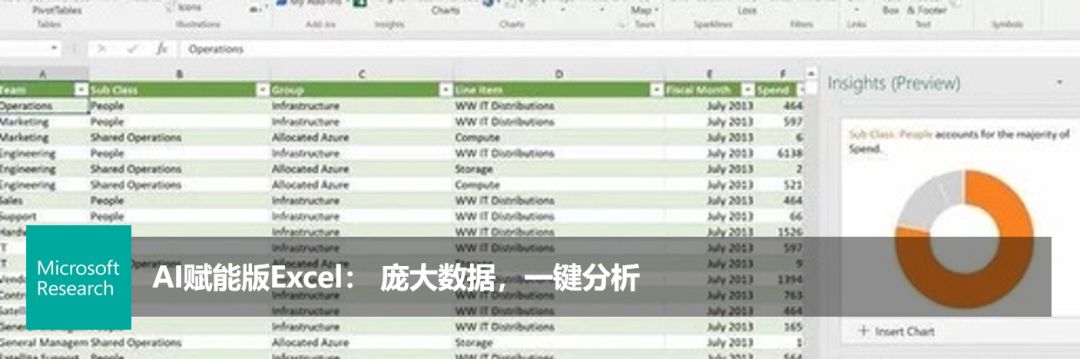
智能数据分析技术,解锁Excel“对话”新功能

编者按:微软在 Ignite 2019 大会上展示了 Excel 中的一项新功能——只需向 Excel 提出一个问题,它就能自动理解,进行智能数据分析,并通过可视化图表的方式将结果呈现在你的眼前。这个超实用功能背后的技术支撑,来自微软亚洲研究院数据、知识、智能组。为了降低大数据时代的数据分析门槛,微软亚洲研究院对对话式数据分析技术开展了多年的研究,致力于为数据分析工具赋予人工智能技术与自然语言理解能力,使更多用户能以更自然、更高效、学习成本更低的方式进行数据分析。
今天,数据正在成为个人和企业的重要资产,分析和提取数据价值的技术也成为了大数据时代人们关注的焦点。然而,目前大多数的数据分析工具要通过编程语言(例如 SQL 语句)进行数据库交互操作,给数据分析设置了较高的专业门槛。人们迫切需要技术革新来降低数据分析工具的使用门槛和成本,并提升数据分析的效率。
对话式数据分析技术应运而生。通过为数据分析工具赋予人工智能技术与自然语言理解能力,对话式数据分析能将人们从繁重的编程语言学习和复杂的工具中解放出来,更加注重分析任务和业务逻辑本身。同时,更简单、高效的分析流程也能够进一步推动数据分析的广泛运用。
对话式数据分析也已经成为业界发展的最新趋势。IT 咨询公司高德纳(Gartner)预计,到2021年,自然语言理解与交互式分析将促使智能商业数据分析的采用率从35%增加到50%。正是由于高度的实用性和广阔的应用前景,工业界在对话式数据分析研究领域同样扮演了重要的角色,微软、谷歌、Tableau、SalesForce 等公司一直活跃在各大顶级学术会议上,引领着最新的商业智能技术的发展。
在本文中,我们将总结对话式数据分析的核心问题与应用挑战,分享数据智能领域的最新研究成果以及在 Excel 中的实际应用。
区别于普通的问答系统,对话式数据分析是一个典型的交叉领域,综合了自然语言理解、多维数据(multi-dimensional data)分析、机器学习、知识工程、人机交互等多个领域。建立一个端到端的对话式数据分析系统主要需要研究以下问题:
理解和识别结构化数据是第一步。在很多场景中(例如网页或者 Excel 文件),表格数据并不像数据库中那样规整,识别和抽取表格信息也并非轻而易举。比如在 Excel 文件中,数据表格通常以一系列有特殊格式和样式的 Excel 单元格组成,还包含非常复杂的分层次的表头、标题、尾注等表格结构元素,因此需要先将这些表格元素抽取和识别出来。然而,并没有内置的数据结构来指示单元格分别对应的表格元素,这给识别和抽取表格数据带来了巨大的困难。理解和识别结构化数据需要:1. 识别表格的结构信息,例如识别标题、表头、表名、列名以及表格值数据;2. 识别数据的元信息(meta data),包括识别表格中每一列的类型(例如字符串类型,数值类型,时间类型与布尔类型等),表格之间的关系(例如主外键关系)等等。
对话式数据分析中,为了回答用户的提问,经常需要利用常识或者领域相关知识,而这些知识往往并不在表格数据中出现。结构化的表格数据看似比非结构化的文本段落更容易理解,但恰恰相反,表格中的数据描述往往是缺失的,标题和表头也经常简短而不完整,领域相关的知识更是存储在用户的脑海中。这些知识的缺失给机器理解用户的问题造成了巨大的挑战,因为用户会根据自己对数据的理解来提问,这些问题中往往包含了表格本身缺失的知识。为了解决这个问题,就需要对表格进行知识增强,例如识别和建立表格中列的实体类型(例如人物、地点、单位、度量等)、列实体间的关系以及它们在语言中的语义角色等,并让算法利用这些知识来理解用户的提问,消除语义分歧,提高理解准确率。
理解和解析用户的自然语言查询是对话式数据分析的核心技术之一。对话式数据分析中的自然语言具有逻辑复杂性、表达多样性、语义歧义性、内容模糊性等问题,给准确理解用户的提问造成了一定的困难。
用户输入的问题通常可以分成两类,一类是查询类问题,即用户有明确的查询意图,这类问题通常可以通过单轮对话解决;另外一类是探索式问题,用户没有明确的查询意图,只有一些假设和猜想,此时需要通过假设-验证(hypothesis-test)的方式,进行提问-反馈-再提问,逐层递进,不断深入,最终达到分析目的。这类问题往往需要通过多轮对话解决,而用户的问题通常是上下文相关的,因此,模型需要具备基于上下文的理解能力。
用户提出的自然语言问题常常会出现歧义,模型需要通过主动询问的方式消除自然语言中的歧义,明确用户的查询意图,实现 AI+HI(人类智能)。
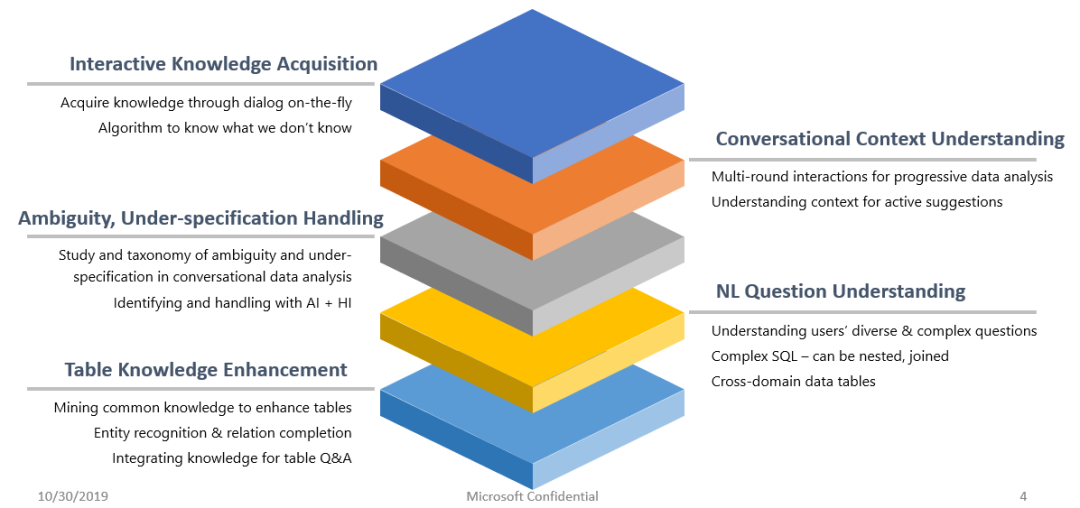
图1:对话式数据分析的研究问题
对话式数据分析应用需要面向各行各业的用户,不同领域的用户都会进行针对性的提问,模型事先无法获取这些领域专业知识,因此需要具备跨领域工作的能力。
对话式数据分析场景下,用户的自然语言表达形式多样,甚至语法错误也很常见,例如,很多用户养成了搜索引擎的关键词使用习惯,导致输入问句只包含关键词,语法结构不够完整。基于规则的传统方法不够灵活,维护难度大,没有办法覆盖到各种语言现象,使得模型的容错能力较差。一个实际的应用产品应当能够处理自然语言表达的多样性。
投入应用的产品需要具备可解释性,既让普通用户能够理解模型给出的结果,也要对开发人员来说可调试(easy to debug)。然而对于一般的端到端的神经网络模型来说,解释错误原因以及调试模型都非常困难,这为神经网络模型在真实产品中的应用造成了很大的障碍。
多语言扩展
作为一个全球性公司,全球化能力是模型设计中的一个重要的考虑因素,模型需要支持多语言及其变种。如何快速且低成本地将对话式数据分析中的算法和模型推广到不同的语言,是一个巨大的挑战。
针对以上挑战,微软亚洲研究院的研究员们开展了一系列的研究工作:
一. 表格实体识别(schema linking):基于自然语言交互的数据分析算法的最大难点,是识别自然语言中提到的列名、表格名、以及单元格值。为了解决这个问题,研究员们提出了一种基于多任务的学习框架,同时解决表格实体识别和语义解析问题,详细内容请参考论文 Data-anonymous Encoding for Text-to-SQL Generation, (EMNLP’19)。
二.设计中间的语言表示(intermediate representation):计算机可执行语言(例如 SQL 语句)往往与数据的存储方式有关,而用户的自然语言是基于语义的,因此,可执行语言和自然语言之间存在着不匹配的问题,给语义解析,尤其是复杂问题的解析带来了困难。为了减少不匹配问题,研究员们提出,需要设计一种中间语言,先将自然语言转换成中间语言,再将中间语言转换到目标语言。我们设计的方法在耶鲁大学发布的 Text-to-SQL 的比赛中,目前位列排行榜第一。详细内容请参考论文Towards Complex Text-to-SQL in Cross-domain Database, (ACL’19)。
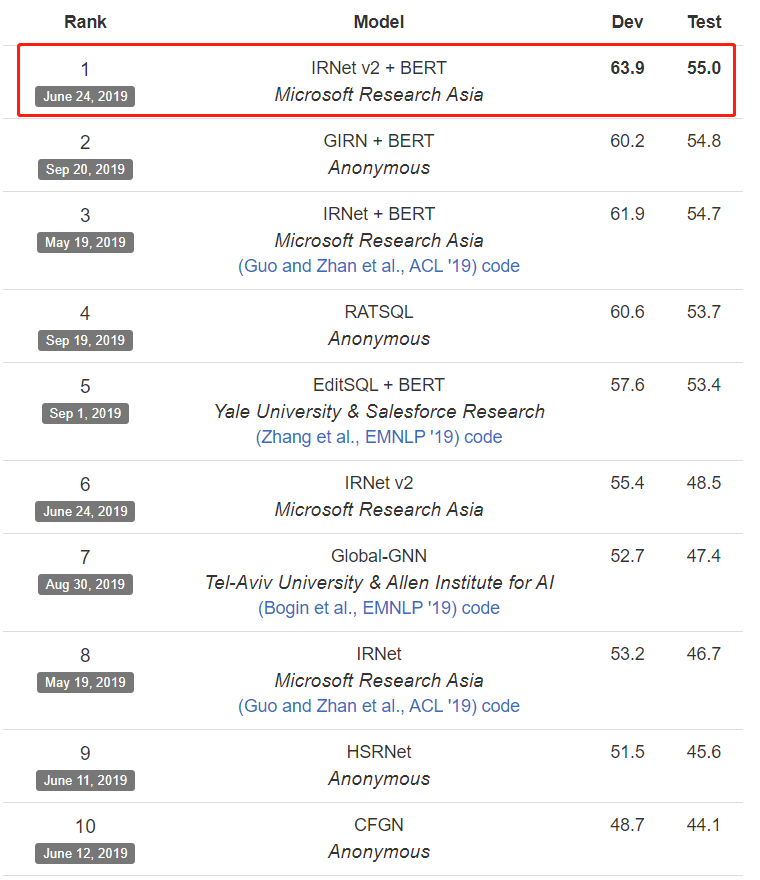
图2:微软亚洲研究院提出的算法目前在耶鲁语义分析与 Text-to-SQL 挑战赛中位列第一
三.通过表格知识挖掘,提升自然语言理解的准确性:用户输入可能包含了隐含指示表格中某个实体的形容词、动词、量词和名词,因此表格知识理解就尤为重要。表格知识包括识别表格中的人名、地名、单位,也包括识别表格相关的形容词、动词等,详细内容请参考论文 Leveraging Adjective-Noun Phrasing Knowledge for Comparison Relation Prediction in Text-to-SQL, (EMNLP’19)。
四.渐进式数据分析:在对话式数据分析中,用户常常使用指代或省略使问题更加简洁和连贯,针对用户提出的上下文相关的问题,研究员们提出了一种新的Split-and-Recombine语义解析算法框架,详细内容请参考论文 FANDA: A Novel Approach to Perform Follow-up Query Analysis, (AAAI’19), A Split-and-Recombine Approach for Follow-up Query Analysis, (EMNLP’19).
作为人们日常办公最重要的工具之一,Excel 功能强大而多样,但许多用户对 Excel 的使用停留在基础的表格制作与存储上,数据分析功能仍然具备一定的专业门槛。
基于数据智能领域丰富的研究成果,微软亚洲研究院开发了一个智能数据分析算法 AnnaParser,来提高 Excel 的智能数据分析能力。为了解决新表格实体识别的问题,AnnaParser 首先引入了一个数据抽象模块(data abstraction)来识别自然语言中与表格相关的部分,比如表名、列名、表格值,然后将这些词汇替换成相应的符号输入语义解析模块,使模型与表格不相关,提升了模型对不同表格的泛化能力。同时,为了实现领域知识的匹配,在实体识别阶段,AnnaParser 还引入了一个知识理解(knowledge understanding)模块,挖掘每个表格背后隐含的知识,表示成知识卡片(knowledge frame),提升实体识别的准确率。
在语义解析阶段,AnnaParser 将语义规则和深度学习算法结合起来,构建了一个自底向上(bottom-up)的解析框架来生成树形的逻辑表达。最后,将逻辑表达式转换为可执行的语言,例如 SQL 等。这个框架可以充分发挥语义逻辑的知识推理能力和深度神经网络的映射学习能力,拥有以下几个优点:首先,与传统的完全基于规则的方法相比,它具有良好的语言灵活性和泛化能力;其次,与端到端的神经网络模型相比,它具有良好的可解释性,容易进行系统调试和渐进调优,并且能够高效地利用通用知识和领域知识;再次,因为语义规则是语言无关的,而且深度神经网络无需进行复杂的特征工程,它具备良好的多语言扩展能力,大大降低了多语言支持的成本。
经过微软亚洲研究院与 Excel 团队的通力合作,AnnaParser 算法已经进入到 Excel 的“Ideas”预览版中。今后,你只要向 Excel 提出一个问题,Excel 就可以通过可视化图表的方式将智能数据分析结果呈现在你的眼前。AnnaParser 将让更多用户能够轻松、高效、零门槛地利用 Excel 进行数据分析,洞见各行各业数据中蕴藏的独特价值。
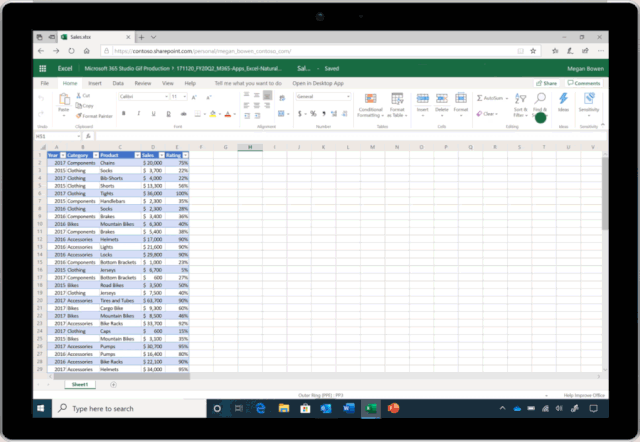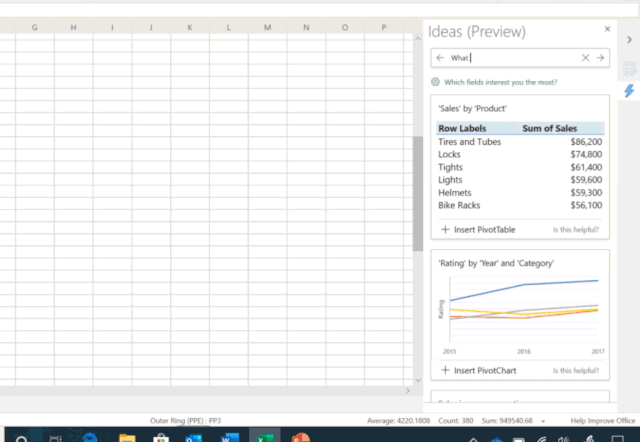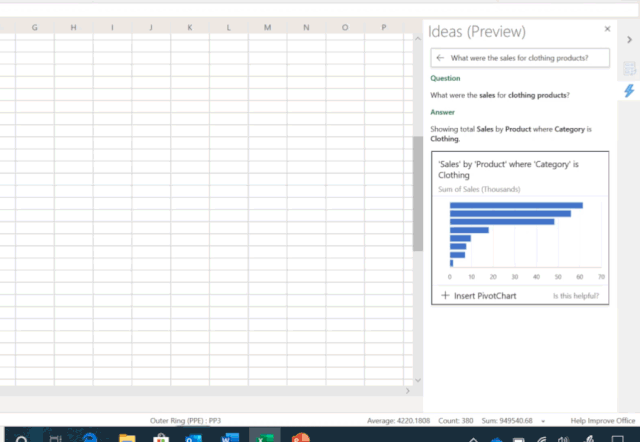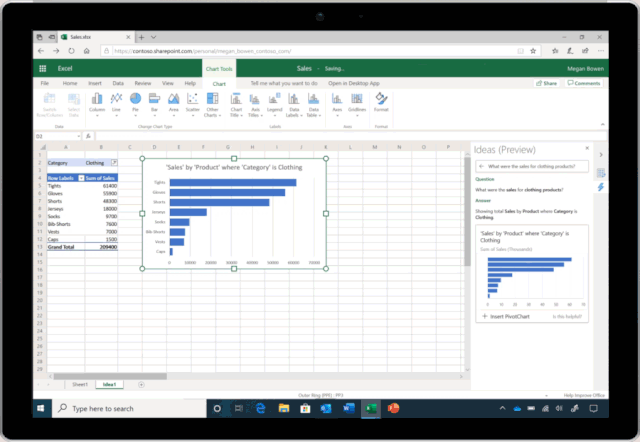
图3:对话式数据分析已进入 Excel 中的 Ideas 预览版功能
你也许还想看: