在小目标检测上另辟蹊径的SNIP
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
1. 前言
相信大家都或多或少的熟悉一些检测器,不知道你是否思考过这样一个问题?FPN的多特征图融合方式一定是最好的吗?如果你看过ASFF这篇论文的话,你应该知道这篇论文的出发点就是如何对不同尺度的特征做自适应特征融合(感觉也可以叫作FPN+Attention),而非Feature Pyramid Network那样较为暴力的叠加(不知道这个说法是否稳妥,有意见欢迎来提)。而今天要介绍的这个SNIP(「An Analysis of Scale Invariance in Object Detection – SNIP」)算法,是CVPR 2018的文章,它的效果比同期的目标检测算法Cascade R-CNN效果还好一些。为什么说这个算法是另辟蹊径呢?因为这个算法从COCO数据集开始分析,作者认为目标检测算法的难点在于「数据集中目标的尺寸分布比较大,尤其对小目标的检测效果不太好」,然后提出了本文的SNIP算法。
2. 出发点
我们首先来看一下这篇文章的出发点,简单来说就是「数据集」。作者发现如果将数据集按照图像中目标的尺寸除以图像尺寸的比例来排序的话,那么在ImageNet中这个比例的中位数是「0.5444」,而在COCO数据集中,这个比例的中位数是「0.106」 ,如下面的Figure1中两个「Median」代表的点所示。
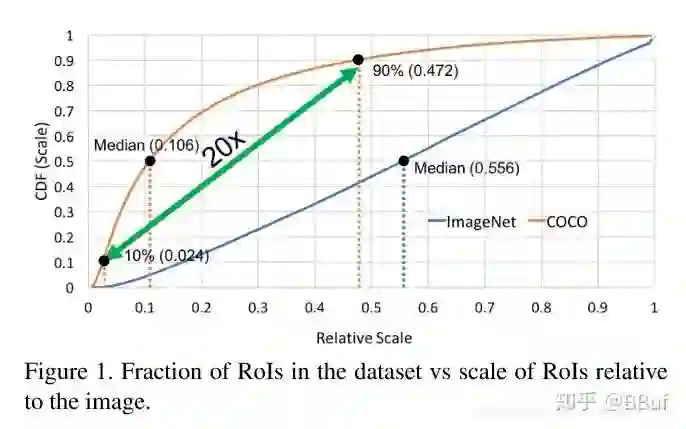
Figure1是针对ImageNet和COCO数据集中目标尺寸和图像尺寸比例的关系曲线,其中横坐标表示 「目标尺寸/图像尺寸」 的值,而纵坐标则表示比例。我们看到在COCO数据集中大部分目标的面积只有图像面积的1%以下,这**「说明在COCO数据集中小目标占的比例比ImageNet多」。此外,在COCO数据集中,第90%(0.472)的倍数差不多是第10%的倍数(0.106)的20倍,这「说明COCO数据集中目标尺寸变化范围非常大」**。
「那么这两种差异会对目标检测带来什么影响呢?」
我们知道在目标检测算法如Faster RCNN/SSD中常用基于ImageNet数据集预训练的模型来提取特征,也就是迁移学习,但是我们从Figure1发现ImageNet和COCO数据集在目标的尺寸分布上差异比较大,这样在做迁移学习时可能会存在一些问题,论文将其称为「domain-shift」,也可以简单理解为是训练集和测试集的分布有较大差异,后面也有实验来说明这一点。
如果读过我之前写的目标检测算法之YOLOv2这篇文章的话应该知道YOLOv2考虑到在ImageNet数据集上预训练模型时输入图像大小是 ,而YOLOv2的输入图像大小是 ,这两者差距比较大,所以就将预训练模型在 的ImageNet数据集上继续预训练,然后再用到检测模型提取特征,这样使得预训练模型和检测模型可以更好的适配。
3. 创新点
在本文之前已经有一些算法针对数据集中目标尺度变化大进行入手了,例如FPN实现多尺度特征融合来提升效果,Dilated/Deformable卷积通过改变卷积核的感受野来提升效果,通过多尺度训练/测试引入图像金字塔来提升效果。不同于上面这些思路,基于对数据集的深入分析,本文提出了一种新的模型训练方式即:「Scale Normalization for Image Pyramids (SNIP)」 ,主要包含两个创新点:
-
「为了减少第二节提到的Domain-Shift,在梯度回传的时候只将和预训练模型所基于的训练数据尺寸相对应的ROI的梯度进行回传。」 -
「借鉴多尺度训练的思想,引入图像金字塔来处理数据集中不同尺寸的数据。」
4. 两个核心实验
我们来首先来看一下论文在ImageNet数据集上做的关于尺寸变化的实验,也就是**「去验证第二节提到的Domain-Shift对模型效果的影响。实验结果如Figure3和Figure4所示,这里主要是基于不同分辨率的图像来训练模型以及不同分辨率的图像作为验证集来验证模型的方式去评估训练集和测试集的尺度差异对模型效果的影响」**,首先来看Figure3:

Figure3中一共展示了 种模型,下面我们分别来描述一下:
-
「CNN-B」。分类模型基于ImageNet数据集常规的 大小来训练,但是验证数据集进行了尺度变化,即先将验证数据图片缩小到 , , 和 ,然后再将这些图片放大到 作为模型的输入,这样放大后的图像分辨率较低。 「因此这个实验模拟的就是训练数据的分辨率和验证数据的分辨率不一致的时候对模型效果的影响,实验效果如Figure4(a)所示。」 -
「CNN-S」。这个实验中,训练数据的分辨率和验证数据的分辨率保持一致,这里主要针对的是 和 的分辨率,并且对网络结构的第一层做了修改。例如对于 的数据进行训练,将卷积核大小为 的卷积层改成卷积核大小为 ,滑动步长为 的卷积层。而基于 的数据训练时,将卷积核大小为 的卷积层变成卷积核尺寸为 ,步长为 的卷积层。 「这个实验模拟的是训练数据和验证数据的分辨率一致的效果,实验结果如Figure4(b),(c)所示。」 -
「CNN-B_FT」。这个模型是CNN-B在放大的低分辨率图像上fine-tune后的模型,并且输入图像也使用放大的低分辨率模型。 「可以看出这个实验验证的是基于高分辨率图像进行训练的模型是否可以有效提取低分辨率图像的特征,实验结果如Figure4(b),(c)所示」。

Figure4是Figure3中三种实验的实验结果展示,从(a)可以看出如果验证集数据的分辨率和训练数据的分辨率差别越大,则实验效果越差,这说明CNN对数据的尺度变化的鲁棒性还不够好。而从(b),(c)的结果我们可以看出当训练数据的分辨率和验证数据的分辨率相同时,模型的效果会好很多,并且CNN-B-FT的效果更好,而二者的差别仅仅是模型是否在放大的低分辨率图像上做fine-tune,因此可以得出下面的结论:
「基于高分辨率图像训练的模型也可以有效提取放大的低分辨率图像的特征。」
上面介绍了在ImageNet上的实验细节,下面来说说在COCO数据集上关于「特定尺度检测器」 和 「多尺度检测器」 的实验,如Table1和Figure5所示。

Table1是检测器在小目标验证集上的检测效果对比结果,用的验证图像尺寸都是 。
-
和 分别代表检测器基于 和 两种尺寸的图像进行训练,从两者的mAP结果对比可以看出 的效果稍好,这和我们前面介绍的基于ImageNet的实验结果也吻合,只是这里的提升非常小,猜测原因是虽然基于放大图像 「(原始图像大概 ,放大成 )训练的模型在训练过程中可以提高对小目标物体的检测,但是由于训练数据中尺寸中等或较大的目标的尺寸太大所以难以训练,这就影响了模型最终的效果」 。检测的效果如Figure5(1)所示。

-
表示训练数据尺寸是 ,但是训练过程中忽略中等尺寸和大尺寸的目标,其中中等和大尺寸的标准是在原始图像中目标宽高的像素大于 ,这就是前面提到的「特定尺度检测器」 ,即基于单一尺度的输入进行训练,这样就可以减少Domain-Shift。所以,这个实验的目的是验证上面那个实验的猜想,即:「基于 大小的图像训练时由于训练数据中尺寸中等及较大的目标对模型训练有负作用,因此这里直接在训练过程中忽略这样的数据。」*但是从Table1的实验结果看出,这个模型的效果更差了,猜测原因是因为忽略这些训练数据(大概占比30%)所带来的的数据损失对模型的影响更大,具体的检测结果如Figure5(2)所示。 -
「MST」 表示训练一个检测器时采用不同尺度的图像进行训练,即前面说的「多尺度检测器」 。按道理来说这个实验的效果应该会比前面2个实验好,可是结果却不是这样,这是为什么呢?「主要原因是训练数据中的那些尺寸非常大或者非常小的目标会影响训练效果」。
因此,基于上面的实验结果,「本文在引入MST思想的同时限定了不同尺寸的目标在训练过程中的梯度回传,这就是SNIP的核心思想」。从Table1可以看出效果提升是比较明显的。
5. SNIP算法
基于前面的分析,我们希望存在一个算法既可以获得多尺度的目标信息,又可以减少Domain-Shift带来的影响,因此SNIP出现了。SNIP借鉴了多尺度训练的思想,在多尺度训练方法中,由于训练数据中尺寸极大或极小的目标会影响实验结果,「因此SNIP的做法就是只对尺寸在指定范围内的目标回传损失(该范围需接近预训练模型的训练数据尺寸),这样就可以减少Domain-Shift的影响。又因为训练过程中采用了类似多尺度训练的方法,所以每个目标在训练时都会有几个不同的尺寸,那么总有一个尺寸在指定的尺寸范围内。」
还需要注意的一点是在SNIP中,对目标的尺寸限制是在训练过程,而不是预先对训练数据进行过滤,训练数据仍然是基于所有的数据进行的。实验证明这种做法对小目标检测非常有效。
下面的Figure6是SNIP算法的示意图。
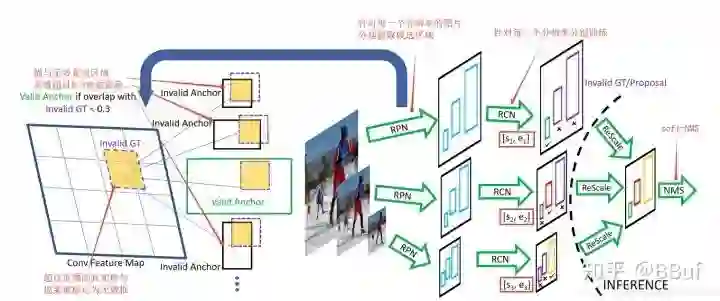
可以看到整个流程还是基于Faster RCNN的,不管是训练ROI Head还是训练RPN网络,都是基于所有Ground Truth来定义候选框和Anchor的标签。具体来说就是某个ROI在某次训练中是否进行梯度回传是和预训练模型的数据尺寸有关的,也就是说当某个ROI的面积在指定范围内时,该ROI就是「valid」,也就是会在此次训练中回传梯度,否则就是「invalid」(如Figure6的紫色框所示)。这些「invalid」的ROI所对应的「invalid ground truth」会用来决定RPN网络中Anchor的有效性。具体来说,「invalid Anchor」 就是和「invalid ground truth」的IOU大于 的Anchor,如Figure6左边的黑色框所示。
另外,作者还分析了RPN网络中不同标签的Anchor比例(一共就2种Anchor,正负样本),我们知道在RPN网络中,一个Anchor的标签是根据Anchor和Ground Truth的IOU值来确定的,只有下面 种情况才会认为Anchor是正样本:
-
「假如某个Anchor和某个ground truth的IOU超过某个阈值(默认 ),那么这个Anchor就是正样本。」 -
「假如一个ground truth和所有Anchor的IOU都没有超过设定的阈值,那么和这个ground truth的IOU最大的那个Anchor就是正样本。」
遵循Faster RCNN的设定,将conv4的输出作为RPN网络的输入,然后在此基础上设定了15种Anchor(5种尺度,三种比例),然后作者介绍了一个有趣的发现,那就是在COCO数据集上(图像大小为
)只有30%的Ground Truth满足Anchor是正样本的第一个条件,即使将阈值调节成
,也只有58%的Ground Truth满足Anchor是正样本的第一个条件。
「这就说明,即使阈值等于 ,仍然有 的正样本Anchor和Ground Truth的IOU值小于 。」 显然,这种正样本的质量是不高的。所以SNIP引入的多种分辨率图像作为输入一定程度上可以缓解这种现象。
6. 实验结果
下面的Table2展示了SNIP算法和其它算法的对比。
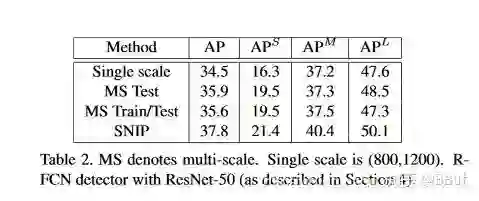
第二行的多尺度测试比第一行的单尺度效果好,而第三行是在多尺度测试的基础上加入了多尺度训练的情况,这个时候在大尺寸目标( )上的检测结果要比只有多尺度测试的时候差,原因在第4节中提到过,主要是因为训练数据中那些极大和极小的目标对训练产生了负作用。
下面的Table3展示了优化RPN后的对比试验结果:
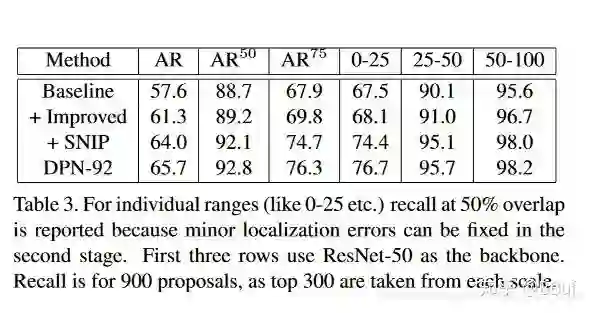
下面的Table4进一步展示了几个目标检测算法的对比结果。D-RFCN表示Deformable RFCN,D-RFCN+SNIP(RCN+RPN)表示在D「eformable RFCN」算法的检测模块和「RPN」网络中同时加入SNIP。
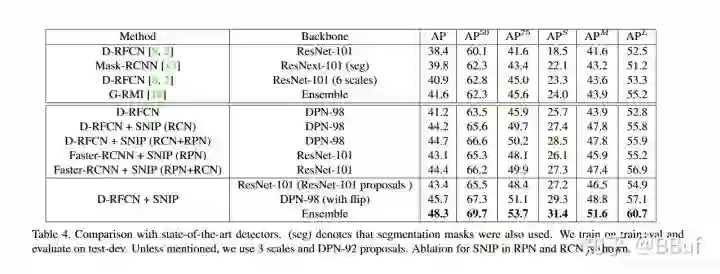
Deformable-RFCN的细节蛮多的,这里就不再赘述了,感兴趣可以查看论文或者搜索相关资料,我后面有空再写写。
7. 结论
推荐阅读:


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~





