基于深度学习的NLP 32页最新进展综述,190篇参考文献
【导读】今年8月,Tom Youn等人更新了去年发表在IEEE杂志上的重磅文章《Recent Trends in Deep Learning Based Natural Language Processing》,总结了到今年为止,基于深度学习的自然语言处理(NLP)系统和应用程序的一些最新趋势。在这篇综述中,读者可以详细了解这一年来学界的一些大动作,它包含以下主题:(1)分布式表征的兴起(例如word2vec)(2)卷积、循环和RNN(3)在强化学习中的应用(4)句子的无监督表征学习的最新进展(5)深度学习模型与记忆增强的结合。最好作者也总结后续NLP的几个重要方向:无监督学习、强化学习的一系列应用、多模态学习等。
题目: Recent Trends in Deep Learning Based Natural Language Processing
作者:Tom Young, Devamanyu Hazarika, Soujanya Poria, Erik Cambria

【摘要】深度学习使用多层学习层次的数据表示,并在许多领域得到了最优的结果。最近,各种各样的模型设计和方法在自然语言处理(NLP)蓬勃发展。在本文中,我们回顾了被广泛应用于各种NLP任务的深度学习相关模型和算法以及它们的发展演变过程。我们还总结,比较和对比了各种模型,对深度学习应用于NLP领域的过去,现在和未来进行了详细阐述和展望。
参考链接:
https://arxiv.org/abs/1708.02709
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“NLPDL2018” 就可以获取深度学习自然语言处理最新进展综述的下载链接~
引言
自然语言处理(NLP)是一种基于理论的计算技术,用于人类语言的自动分析和表达。NLP的研究已经从分析一个句子的时间长达7分钟的打孔卡和批处理的时代发展到像谷歌这样的不到一秒时间处理数百万网页的时代。NLP使计算机能够在各个层面执行各种与自然语言相关的任务,从解析和词性标注到机器翻译和对话系统。
深度学习架构和算法已经在计算机视觉和模式识别等领域取得了令人瞩目的发展。遵循这一趋势,近年来的NLP研究越来越多地关注于使用新的深度学习方法(见图1)。几十年来,针对NLP问题的机器学习方法一直基于在非常高维和稀疏特征上训练浅层模型(如SVM和logistic回归)。近年来,基于密集向量表示的神经网络已经在各种NLP任务中取得了较好的效果。这种趋势是由词嵌入(word embeddings)[2,3]和深度学习方法[4]的成功引发的。深度学习可以实现多层次的自动特征表示学习。相比之下,传统的基于机器学习的NLP系统在很大程度上依赖于人工制作的特性。这些人工制作的功能非常耗时,而且常常是不完整的。
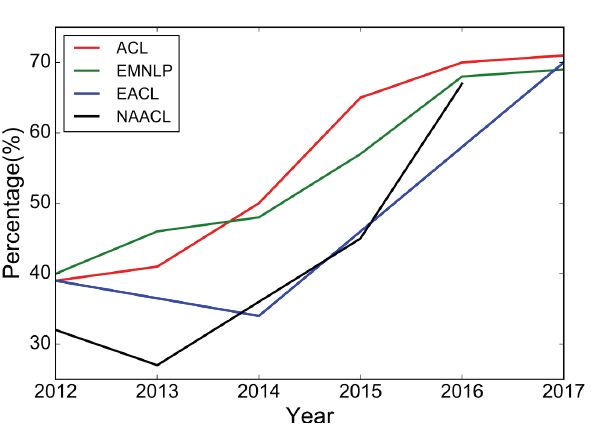
Fig. 1: Percentage of deep learning papers in ACL, EMNLP, EACL, NAACL over the last 6 years (long papers).
Collobert et al.[5]证明了一个简单的深度学习框架在一系列NLP任务(如命名实体识别(NER)、语义角色标记(SRL)和POS标注)中的表现优于最先进的方法。此后,针对一些复杂的NLP任务,提出了许多基于深度学习的复杂算法。该论文回顾了应用于自然语言任务的一些主要的深度学习模型和方法,如卷积神经网络(CNNs)、循环神经网络(RNNs)和递归神经网络。我们还讨论了记忆增强策略、注意力机制以及无监督模型,强化学习的方法以及最近的深度生成模型如何被用于与语言相关的任务。
据我们所知,这是第一个全面涵盖当今NLP研究中最流行的深度学习方法的一项工作。Goldberg[6]的工作只是以教程的方式介绍了将神经网络应用于NLP的基本原理。我们相信这篇文章将会让读者更全面的了解这个领域目前的一些实践。
本文的结构如下:
第二部分介绍了分布式表示的概念,是复杂的深度学习模型的基础;
第三、第四和第五节讨论了一些比较流行的模型,如卷积、循环和递归神经网络,以及它们在各种NLP任务中的使用;
第六节列举了强化学习在自然语言处理中的最新应用和无监督句子表示学习的新进展;
第七节阐述了深度学习模型与记忆模块耦合的最新趋势;
第八部分总结了一系列基于深度学习方法的NLP任务在标准数据集上的性能表现。
结论
深度学习提供了一种处理大量计算和数据的方法,而无需多少手工工程[90]。随着分布式表示的出现,各种深度模型已经成为解决NLP问题的最新方法。监督学习是近年来NLP深度学习研究中最受欢迎的做法。然而,在许多现实世界的情景中,我们都有未标记的数据,这些数据需要先进的无监督或半监督方法。如果某些特定的类缺少标记数据,或者在测试模型时出现了一个新类,那么应该使用zero-shot learning之类的策略。这些学习方案仍处于发展阶段,但我们期望基于深度学习的NLP研究能够朝着更好地利用未标记数据的方向发展。我们预计这种趋势会随着更多更好的模型设计而继续。我们期望看到更多采用强化学习方法的NLP应用,例如对话系统。我们还期望看到更多关于多模态学习的研究[190],因为在现实世界中,语言通常以其他信号为基础(或与之相关)。
最后,我们期望看到更多深度学习模型,其内部存储器(从数据中学到的自底向上的知识)通过外部存储器 (从知识库继承的自顶向下的知识)得到丰富。符号与子符号人工智能的耦合是实现从自然语言理解向自然语言理解过渡的关键。事实上,依靠机器学习,可以根据过去的经验做出“好的猜测”,因为子符号方法可以编码相关性,而他们的决策过程也是概率性的。然而,自然语言理解需要的远不止于此。用诺姆•乔姆斯基(Noam Chomsky)的话来说,“在科学领域,你不会通过获取大量数据、将它们输入电脑并对它们进行统计分析来获得发现:这不是你理解事物的方式,你必须具备理论上的见解。”
附教程内容






















请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“NLPDL2018” 就可以获取深度学习自然语言处理最新进展综述的下载链接~
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




