

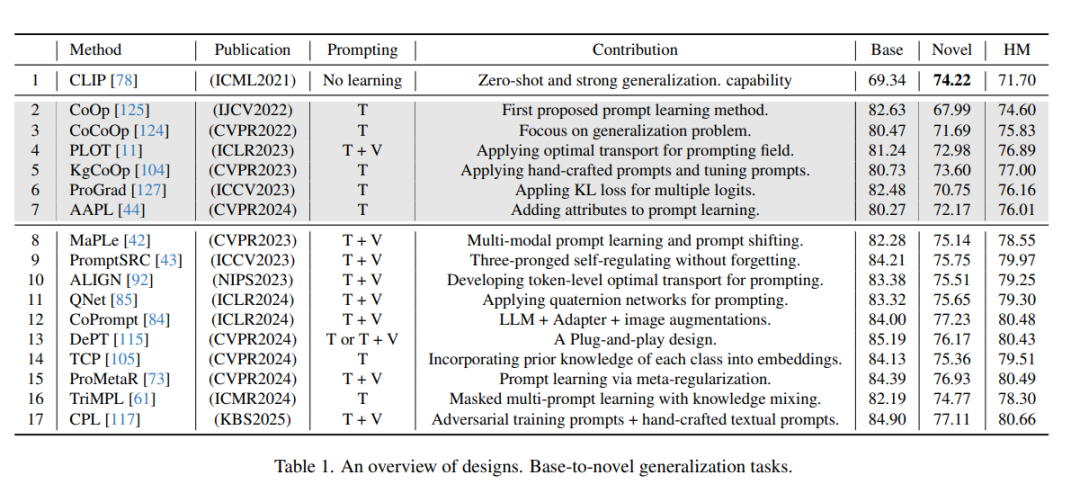
- 引言 大规模预训练模型,例如BERT [41]和T5 [79],在自然语言处理和计算机视觉领域取得了显著进展。计算机视觉领域的大规模预训练模型,如ViT [22],将图像视为序列数据,并通过在大规模图像数据集上进行预训练来学习大量的通用视觉知识。这些进展为图像分割 [7, 21, 64, 65, 123]、3D检测 [15, 23, 33, 67]、视觉问答 [107–110, 112, 113] 以及其他应用 [52, 57–59, 86, 95, 100] 的多模态预训练模型的出现奠定了基础。研究者们开始探索如何整合语言模型和视觉模型,以实现对文本和图像的统一理解。这导致了许多图文多模态预训练模型的出现,也称为视觉-语言模型(VLMs),例如CLIP [78]和ALIGN [38]。这些模型通过对比学习和掩码语言建模等策略,在大规模图文对上进行训练,以学习文本和图像的跨模态表示。例如,CLIP通过训练4亿对图文数据,最大化相同图文对的相似性并最小化非配对图文对的相似性,从而联合学习图像和文本的表示。这些VLMs展示了强大的联合表示能力,但将其迁移到下游任务中仍是一个新的挑战 [66]。微调通常需要大量标注数据来调整模型参数,这在少样本场景中并不适用。同时,微调可能会破坏VLM在预训练阶段学到的通用知识,导致灾难性遗忘。少样本图像识别领域的开创性研究可以追溯到手工特征时代。随着深度学习的兴起 [3],研究者们开始关注如何利用神经网络的强大拟合和泛化能力来解决少样本图像识别问题 [54, 70, 77, 81]。 近年来,随着CLIP为图像分类开辟了新范式,如何在零样本和少样本场景中高效地将CLIP迁移到图像分类任务中成为研究热点。CLIP在少样本图像分类任务中展示了出色的分类性能,这得益于其使用手工设计的提示工程(prompt engineering)技术为每个分类类别构建文本提示,然后利用文本和图像编码器提取特征向量,并通过计算余弦相似度进行图像分类。这些提示可以包括手工设计的文本,例如“a photo of a [class]”,以指导CLIP的文本编码器。与重新训练模型相比,CLIP的提示工程方法允许自由更改类别数量,为图像分类创造了新范式。在CLIP之后,一些研究 [62, 124] 受到NLP领域提示学习的启发,使用可学习的提示(learnable prompts)代替固定模板“a photo of a [CLASS]”进行少样本数据训练,从而在指定样本上取得了更好的分类结果。在CLIP的图像模态中引入可学习提示的目的是调整图像的特征表示,使其更接近对应类别的文本提示特征向量,从而提高分类准确性。从开创性角度来看,CoOp [125] 首次在CLIP的任务迁移中引入了可学习提示,用可学习的文本提示替换了“a photo of a [CLASS]”模板,相比CLIP显著提升了图像分类任务的表现。然而,CoOp在泛化能力上表现较差,学习到的提示在新类别上效果不佳(表1),这可能是由于对训练图像的过拟合 [124]。这些方法通常依赖于单一的可学习提示,无法全面描述分类类别,从而限制了其区分不同分布的能力 [8, 9, 55, 91]。将提示学习扩展到CLIP的图像模态的研究尚未充分考虑文本提示学习与图像之间的协同效应,也未充分利用CLIP中包含的丰富多模态知识 [111, 124]。为了解决这一问题,CoCoOp [124] 在CoOp的基础上将图像特征向量与可学习文本提示结合,增强了对图像实例信息的关注,并提升了对未见类别的分类准确性。许多研究致力于在少样本图像分类任务中有效应用CLIP的提示学习,但这些工作仍存在主要问题。在表1中,CoCoOp在新类别上的表现优于CoOp,但仍未达到无学习提示的CLIP的水平,且这些模型 [11, 44, 62, 104, 127] 也存在类似问题。
成为VIP会员查看完整内容
相关内容
Arxiv
223+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日