

场景文本分割旨在从场景图像中裁剪文本,通常用于帮助生成模型编辑或删除文本。现有的文本分割方法往往涉及各种与文本相关的监督以提高性能。然而,大多数方法忽略了文本边缘的重要性,而文本边缘对下游应用具有重要意义。本文提出了边缘感知Transformer(EAFormer),以更精确地分割文本,特别是文本边缘。
方法
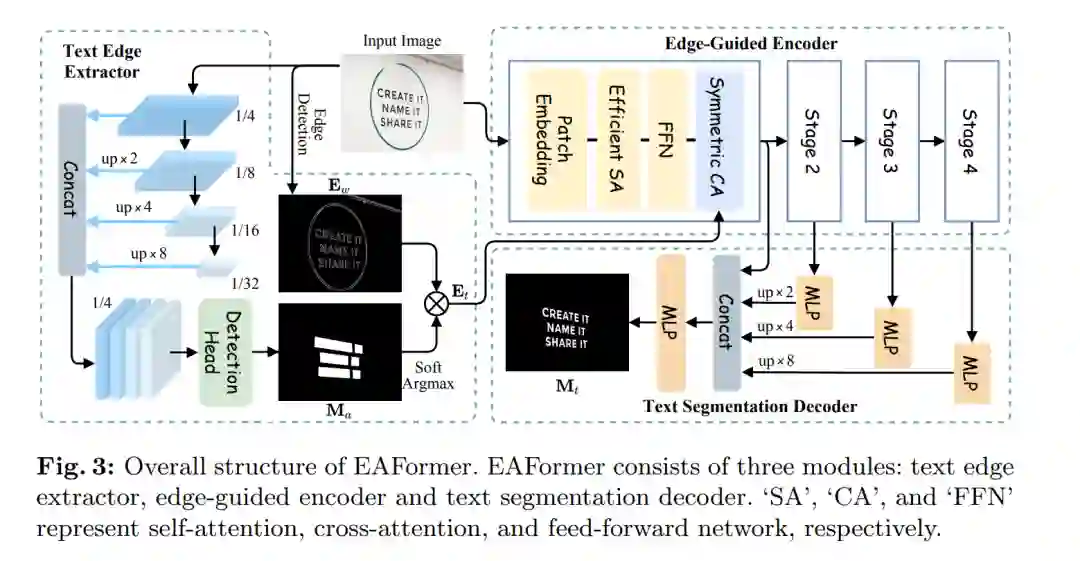
文本边缘提取器
首先,我们设计了一个文本边缘提取器,用于检测边缘并过滤掉非文本区域的边缘。这个提取器能够有效地识别出文本的边界,从而为后续的分割任务提供有价值的信息。
边缘引导编码器
然后,我们提出了一个边缘引导编码器,使模型能够更多地关注文本边缘。通过引入边缘信息,编码器能够更准确地捕捉文本区域,从而提高分割的精度。
基于MLP的解码器
最后,我们使用了一个基于多层感知器(MLP)的解码器来预测文本掩码。该解码器能够将编码后的信息转换为精确的文本区域掩码,从而实现文本的精确分割。
实验
我们在常用的基准数据集上进行了广泛的实验,以验证EAFormer的有效性。实验结果表明,所提出的方法在文本边缘分割方面比现有方法表现更好。考虑到几个基准数据集(如COCO_TS和MLT_S)的注释不够准确,无法公平评估我们的方法,我们重新标注了这些数据集。通过实验,我们观察到,当使用更准确的注释进行训练时,我们的方法可以实现更高的性能提升。 代码和数据集可以在以下网址获取:https://hyangyu.github.io/EAFormer/
结论
本文提出了一种新的场景文本分割方法——EAFormer,通过引入边缘感知机制,提高了文本特别是边缘的分割精度。实验结果验证了我们方法的有效性,特别是在重新标注的更准确的数据集上表现更加突出。未来的工作将致力于进一步优化模型结构,并扩展到更多的实际应用场景。
成为VIP会员查看完整内容
相关内容
相关主题

相关VIP内容
相关资讯
相关论文