大型语言模型(LLMs)的最新进展增强了自然语言推理。然而,它们有限的参数记忆和易受幻觉影响的特性,在需要准确的基于上下文推理的任务中仍然存在持续挑战。为了克服这些限制,越来越多的研究提出了利用外部知识来增强LLM的方法。本研究系统地探索了使用外部知识增强LLM的策略,首先通过一个分类法将外部知识分为非结构化数据和结构化数据。接着,我们重点讨论结构化知识,提出了表格和知识图谱(KGs)的不同分类法,详细介绍了它们与LLM的集成范式,并回顾了具有代表性的方法。我们的比较分析进一步突出了可解释性、可扩展性和性能之间的权衡,为开发可信且具有普适性的知识增强LLM提供了洞察。
引言
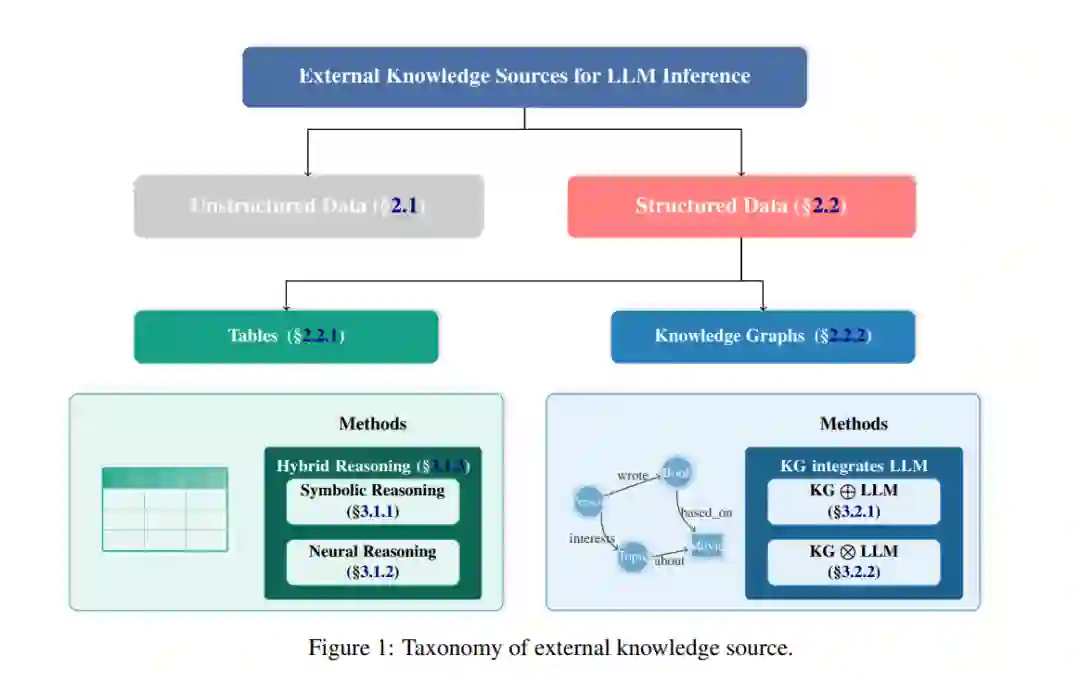
大型语言模型(LLMs)的进展(Radford 等,2019;Brown 等,2020a;Achiam 等,2023;Touvron 等,2023a,b;Grattafiori 等,2024)显著推动了自然语言处理的进步。这些模型在自然语言理解、生成和推理方面表现出色。然而,它们仍然面临若干限制,促使研究人员将外部知识整合到模型中,以提高性能、可靠性和可解释性。 主要的限制包括:1)由于训练数据的截止,知识过时;2)幻觉问题(Huang 等,2025);3)缺乏领域特定的专业知识;4)响应缺乏透明度。为了解决这些问题,研究人员正在通过在推理过程中引入外部信息,将LLM转变为具有知识感知的助手。尽管在这一领域取得了快速发展,但知识增强LLM推理的格局仍然是碎片化的,不同的数据模态和领域的方法不断演变。这些方法大多遵循检索-增强-生成(RAG)框架(Fan 等,2024),该框架专注于检索相关的外部知识,通过模型的内部理解进行增强,并生成响应。由于这种方法在减少幻觉的同时保留了LLM的生成能力,它已成为主流。 本文首先介绍了知识来源的分类法,将其分为结构化(Zhang 等,2024;Pan 等,2024;Dagdelen 等,2024)和非结构化(Gao 等,2024;Yin 等,2024;Selmy 等,2024)形式。我们主要关注结构化数据,因为它具有明确的关系和推理能力,回顾了利用表格和知识图谱(KGs)数据的相关方法。这包括符号推理(Rajkumar 等,2022;Nahid 和 Rafiei,2024a)、神经推理(Wang 等,2024)和混合推理(Nahid 和 Rafiei,2024b;Zhang 等,2025;Nguyen 等,2025)用于表格数据的处理,以及松散耦合(Baek 等,2023;Li 等,2024b;Wu 等,2023)和紧密耦合(Sun 等,2024;Ma 等,2025;Chen 等,2024)用于知识图谱的集成方法。我们通过比较这些方法的优势、局限性和主要权衡,总结了它们的特点。 通过关注知识集成,我们强调的是在推理过程中增强LLM的方法,而非预训练或微调。这种方法需要较少的资源,并允许动态响应,因为外部知识可以根据需要实时添加,而无需重新训练,同时保持模型性能。 本综述的主要贡献包括: • 对外部知识来源和集成策略的全面分类,特别关注表格和知识图谱(KGs)。 • 通过基准实验对代表性方法进行比较分析,突出其优缺点和权衡。 • 提供实践性见解和指导,为未来的知识增强LLM研究提供参考。