R语言之数据分析高级方法「时间序列」

作者简介Introduction
姚某某
知乎专栏:https://zhuanlan.zhihu.com/mydata
往期回顾:

本节主要总结「数据分析」的「时间序列」相关模型的思路。
「时间序列」是一个变量在连续时点或连续时期上测量的观测值的序列,它与我们以前见过的数据有本质上的区别,这个区别在于之前的数据都在一个时间的横截面上去测量、计算数据,而「时间序列」给出了一种时间轴线上纵向的视角,将时间作为自变量,测量出一系列纵向数据。
关于「时间序列」的预测模型,我所了解的常用模型有三种:1. 移动平均 2. 指数预测模型 3. ARIMA 预测模型
0. 时序的分解
要研究时序如何预测,首先需要将复杂的时序数据进行分解,将复杂的时序数据分解为单一的分解成分,这样能利用统计方法进行拟合,然后个个击破,最后再合成为我们需要预测的未来时序数据。
前人在这一问题上已经得到很好的结论,通过对时序数据现实意义的理解,一般将时序数据分解为四个成分:
1. 水平项
2. 趋势项
3. 季节效应(衍生出去为周期项)
4. 随机波动
水平项,即剔除时序数据的趋势影响和季节影响后,时序数据所剩的成分,它代表着时序数据在时间轴上相对稳定的一个基础值。就像一个原点一样,在这个原点上去考虑时间所带来的趋势影响和季节影响。
趋势项,它用于捕捉时序数据的长期变化,是逐步增长还是逐步下降。就像在二元空间中的一个单调函数。
季节效应,衍生出去就是周期型,在一定时间内,时序数据所包含的周期型变化。就像在二元空间中的三角函数,如y=sinx,其数值是周而复始的。
通常在分解以上各个成分时,有两种模式,一个是乘法模型,一个是加法模型。其中,加法模型的季节效应被认为不依赖于时间序列,二乘法模型认为季节影响随着时间会发生改变。不过两种模型在计算时可以相通,对乘法模型作对数处理即可。
1. 移动平均
这一方法很简单,只做简单讲解
所谓移动平均,就是使用时间序列中最接近的 k 期数据值的平均值作为下一个时期的预测值。
即:
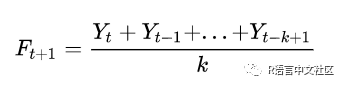
较小的 k 值将更快速追踪时间序列的移动,而较大的 k 值将随着时间的推移更有效地消除随机波动。
可延伸为加权移动平均,此法对每个数值选择不同的的权重,然后计算最近 k 期数据值的加权平均数作为预测值。
如果仅用于平滑现有数据,也可以使用居中移动平均,即使用时序中前后最接近的各 q 期数据及自己的平均值作为在该时点上的平滑值。
即:
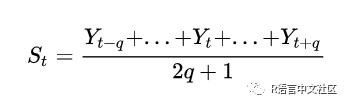
2. 指数预测模型
指数预测模型也是利用过去的时间序列值的加权平均数作为预测值,它是加权移动平均法的一个特例。
即:只选择最近时期观测值的权重,其他数据值的权重则自动推算,原则是时间距离越远权重越小。
2.1. 单指数平滑
单指数平滑,不考虑季节和趋势分解,仅用过去数据值的加权平均数来预测。其思想为:
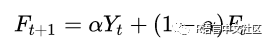
其中 F 为某时刻的预测值,Y 为某时刻的观测值。以上公式从 t = 1 开始递推,则每个时刻的预测值都包含着过去所有观测值的成分,只是权重不同,令F1 = Y1 ,则:
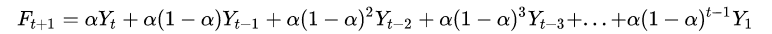
α为平滑常数,越接近于 1 ,则近期观测值的权重越大;反之,越接近于0,历史观测值权重越大。
2.2. Holt 指数平滑
Holt 指数平滑,在单指数平滑的基础上,还对趋势项进行了拟合。
由于考虑到了趋势项,则预测值可表示为:
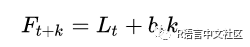
其中 Lt 为 t 时刻时序水平项的估计值,bt为 t 时刻时序斜率的估计值。
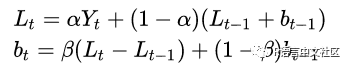
α为水平平滑常数, β为斜率平滑常数。
2.3. Holt-Winters 指数平滑
Holt-Winters 指数平滑,在 Holt 指数平滑的基础上,还对季节项(周期项)进行了拟合,
由于还考虑到了季节项,则预测值表示为:
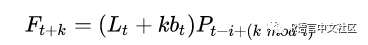
其中 i 为季节项的周期,mod 是求余,P 是某时刻时序周期的估计值。
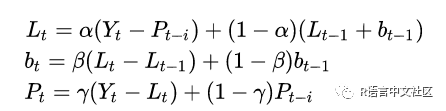
α为水平平滑常数,β为斜率平滑常数,γ为周期平滑常数。
2.4. R 语言实现
以上三种指数平滑模型,采用 forecast 包中的 ets ( ) 函数即可:
ets(ts, model="zzz")
# ts 为需要分析的时序
# model 为模型选择参数,具体分类如下
# 不指定 model 参数时,自动匹配最优模型

3. ARIMA 预测模型
ARIMA 模型的相关资料我找到了,但是并没有看完和看懂,相对来说其思想确实有些复杂。而且最近买了《统计学方法》和《机器学习》两本书,发现自己的线性代数水平还很难看懂这些公式和算法推导,所以准备把《 R 语言实战 》敲完后转入线性代数的复习,之后学习方向待定。
这里我就仅把利用 R 语言进行 ARIMA 模型模拟和预测的流程做以总结:
3.1. 确保时序是平稳的
时序平稳的要求一般有两个:方差为均值、无趋势项
方法是利用时序图估判和 ndiffs ( ) 函数推荐最优的差分次数 d 。
3.2. 选择模型
通过 ACF 和 PACF 图来判断 p 和 q 参数的值。
其中 ACF 为自相关函数图用于判断 q,PACF 为偏自相关图用于判断 p。
p 为自回归模型(AR)参数,q 为移动平均模型(MA)参数。
3.3. 拟合模型
fit <- arima(ts, order=c(p,d,q))
# ts 为原时序,order 中放入包含三个参数的向量
fit
# 一般要进行多组参数的尝试,在输出结果中利用 AIC 值来选择最合理的模型,AIC 越小越好
accuracy(fit)
# 得到一系列误差值,用于准确性度量
3.4. 模型评价
模型的残差应该满足独立正态分布,根据这一条:
1. 使用正态 Q-Q 图来判断其正态性
2. 使用box.test ( ) 函数对模型的残差进行独立性检验。
3.5. 预测
forecast(fit,3)
# fit 为我们之前拟合好的最佳模型,3 指的是要预测的年数
3.6. 自动预测
forecast 包中的 auto.arima ( ) 函数可以实现最优 ARIMA 模型的自动选取。

公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享


