
关于Q(Q-star)的两个猜测*
11月22日,在OpenAI宫斗进入尾声的时候,多家媒体曝出了一个宫斗背后原因的新版本:在Sam Altman被董事会开除前的几天,几名OpenAI员工向董事会发出警告,称Q*可能预示着通用人工智能即将出现,正是这封警告信促使董事会解雇了他们的CEO。
**Q*究竟是什么?**这之后的几天,越来越多的研究人员和工程师加入了对Q 的猜测中。虽然网上炒得很热闹,大家都没有在正式场合严肃地讨论这个问题,毕竟来自一个未经证实的传闻,而且只有名字、对技术细节一无所知。相信很多人和我一样,并不在意传闻的真假,对类似阴谋论的说法也没有兴趣。但不得不说,这些讨论中从技术角度的种种猜测和开的脑洞值得关注,反映了大家对于AI当前局限和未来发展方向的思考。比如知乎的这个讨论Q的帖子就出现了大量深入的讨论[D1]。从这个角度看,这更像是一次全网的头脑风暴。最近这个话题冷下来了。作为吃瓜群众,我把这段时间看到的信息做了整理,也许会有一些有意思的想法。
首先,为什么大家对OpenAI一个传闻中的项目都有如此大的兴趣?一方面,从去年底开始颠覆了很多事情的ChatGPT以及看起来怎么努力都赶不上的“别人家的”GPT-4,都增加了OpenAI这家公司的神秘性。毕竟,《自然》已经将chatgpt列为2023年度十大科学人物(Nature's 10)。首次有非人类入选,也代表了其对科学发展的深刻改变,它可是承载了全村人的希望。另一方面,从GPT-1到GPT-2、GPT-3,除了超前的认知和对大力出奇迹的坚定信念,只能说OpenAI每一次都选择了正确的技术线,然后用了更多数据、更大模型和高级的训练优化策略,但我们并没有看到很特别的技术。在GPT-4(V)已经接入多模态的情况下,让人期待GPT-5会带来什么新的东西。增加context length、定制GPTs这些实用性进展显然够不上人们的期待,似乎也不符合OpenAI的报复。所以,他们会不会藏了什么大招?
于是,稍有风吹草动就引来各种猜测,可谓是为别人家的事操碎了心。总结来看,对于Q的猜测普遍一致,代表了Q-learning强化学习。对于*的猜测,与搜索和奖励数据的自动获取两个要素有关。此外,各种猜测都在向将LLM和AlphaGo结合的方向引导。下面就围绕搜索和奖励数据自动获取如何融入预训练+强化学习,总结两个猜测。提前声明:我的方向不是自然语言处理或强化学习,理解难免有误、预测也没有考虑可行性。此外,外行的思考多是后知后觉,也许NLP和RL大佬们已经实现或者在实现的路上了。 猜测一:搜索=思维树,奖励数据自动获取=过程奖励自动标注
Nathan Lambert的这篇博客[D2]算是对猜测一的集大成讨论。 对于Q*,很多人都联想到了Q-learning和A*,所以也自然把Q*和强化学习以及搜索联系在了一起。具体到搜索如何与强化结合,要从RLHF中简化的bandit问题说起。在InstructGPT实现的标准RLHF中,预测序列token的行为奖励是独立分配的,即输出的每个token都共享整个response的奖励。这没有利用强化学习在序列决策建模方面的潜力。 最近从思维链发展出的思维树提示(Tree-of-Thought,ToT[L1])提供了可能的解决思路。思维树模拟人类的推理过程,将问题求解定义为树上的搜索问题,相比思维链允许采用不同的思维路径(图1),在24点等需要复杂推理的任务上获得了不错的结果。思维树是为推理阶段的提示优化提出的。在与预训练以及强化学习结合时,可以将RLHF使用的策略函数以策略树的形式实现(图2):给定prompt(状态s),生成response(动作a)的过程通过思维树分解为多条、多步的推理路径。推理路径构成马尔科夫链,通过为每一步推理赋予价值,从而提高LLM的推理求解能力。这里的价值可以看成是推理过程中的奖励,与OpenAI在今年5月提出的过程监督奖励(process-supervised reward[L2])有着相似之处。
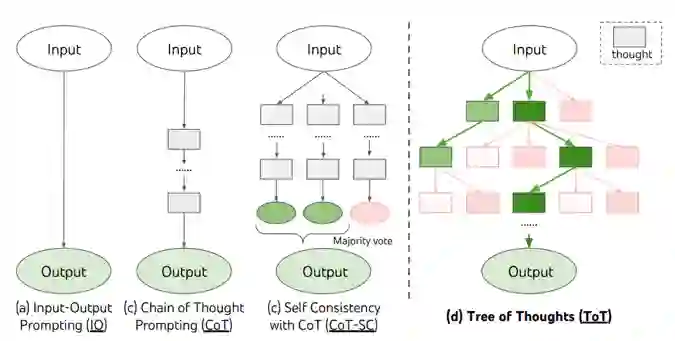
图1 思维树示意[L1]
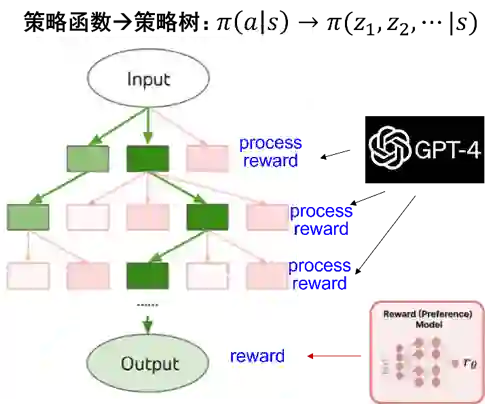
图2 RLHF:策略函数->策略树
在AlphaGo中,和树搜索相关的MCTS用在推理阶段。但我们知道,AlphaGo Zero在训练阶段也引入了MCTS,将第二步策略网络强化中的策略自对弈替换成了MCTS自对弈,这一变化显著了提升了棋力。在围棋等游戏中,可以通过最终的输赢结果来估计价值,但在RLHF中如何为中间推理步骤赋予价值呢?在过程监督奖励论文[L2]中,OpenAI邀请人类标注者为每个中间步骤标注过程奖励值,但这显然无法满足强化学习训练对实时和大规模反馈数据的要求。一个可能的解决思路是用算力换人工,例如用GPT-4自动评估每一步推理的价值(类似思维树中value prompt的作用),最终的奖励仍然由Reward Model提供(图2)。 总结一下。猜测一比较有意思的地方在要素1-搜索:将思维树引入LLM训练的RLHF强化学习。思维树的引入提供了更为复杂和灵活的决策框架,可以提升模型的结构化推理能力。在此框架下,LLM不仅是生成响应,而是在多个推理路径中进行选择和优化。这里从大模型合成数据的角度讨论一下要素2-奖励数据自动获取。利用合成数据辅助训练,可以追溯到早期深度学习训练使用的数据增强,近期的例子包括ShareGPT收集ChatGPT的对话数据以支持其他模型的微调,以及Anthropic的RLAIF方法。随着自然数据的耗尽以及对数据分布等要求的提高,如何有效地利用合成数据(或者说是AIGC)进一步提升大模型的能力尤为重要,而其中的准确性、可靠性和效率等问题都亟待解决。 关于猜测一,如果结合系统一和系统二,有一个值得思考的地方。首先,目前提示方法中的思维链、思维树、思维图之所以可以提升推理能力,一定程度上可以理解为在推理阶段启用了类似于系统二的处理方式。但此时LLM的训练仍然依赖系统一的方法。猜测一将思维树加入RLHF,可以视为对LLM进行系统二的训练,从而在推理时自然地发挥出系统二的能力。但如果训练用系统二、推理时不加入思维树而采用系统一,会产生什么效果?回顾MuZero的做法,它在训练中采用了类似AlphaGo Zero的MCTS自对弈方法,但在推理阶段、尤其是需要快速响应的场景,它并不进行在线MCTS搜索,而是直接使用训练好的策略网络来做决策。这是因为策略网络经过大量离线自对弈训练后已经足够强大,能够在没有实时MCTS辅助的情况下作出高质量的决策。**从系统一和系统二的角度看,这可以理解为经过系统二的强化训练后,模型获得了复杂的推理能力,并已经将这些能力固化为系统一的直觉。**打个比方,我们说一个人直觉(系统一推理)非常好,其实是因为他经过了长期深入思考(系统二训练),从而系统提高了认知能力。 关于在预训练的强化学习中加入树搜索,其实不是什么新鲜事。早在今年6月,DeepMind的创始人Demis Hassbis就提到Gemini中会融入AlphaGo的技术,包括强化学习和树搜索等[D3]。结合传闻中的消息和上述讨论,可以看到这种想法确实有望提升数学和编程类推理任务上的解决能力,但它是否能提升模型的通用能力以及对其他任务的解决能力还未知。此外,尽管树搜索的加入提高了强化学习对于数据的利用效率,但这些数据仍然直接(如人工标注)或者间接(如GPT-4标注)地来自于人,限制了模型超越人类知识的潜力。至于Q*项目是否旨在超越人类,这引出了下面的猜测二。 猜测二:搜索=思维树,奖励数据自动获取=自我博弈(self play)
从Andrej Karpathy11月的一个报告说起[D4]。在谈到未来值得关注的方向时,Andrej Karpathy比较了AlphaGo和LLM(图3):AlphaGO的训练除了模仿学习还有自我博弈强化,从而探索出了超越人类经验的策略;相比之下,LLM只有模仿学习,依赖大规模的语料库学习,这些语料库基本上是人类知识和交流的集合,主要反映和模仿人类已有的知识和表达方式。
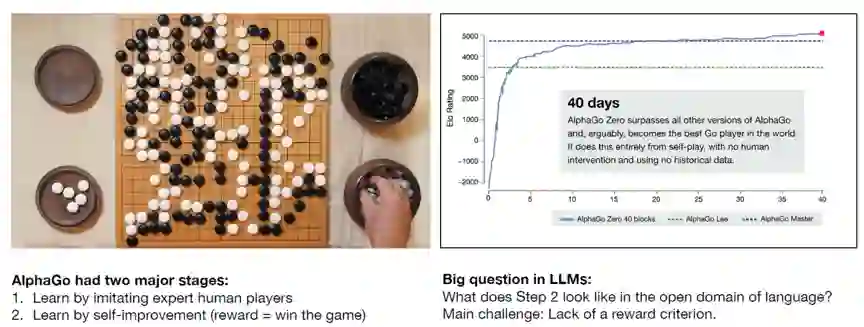
图3 AlphaGo vs. LLM[D4]
关于预训练和强化学习的结合,我们再拉远一点视角。图4是OpenAI研究员Hyung Won Chung今年10月在首尔国立大学报告[D5]中的一页slide,从手工设计和自动学习模块的变化总结了人工智能从专家系统、传统机器学习、深度(监督)学习到深度强化学习的转变。其中强化学习为深度学习带来了可以学习的目标函数。这隐隐让我有种感觉,如果说深度学习代表了过去(虽然这个过去也不远)、预训练代表了现在,难道强化学习代表了(不远的)未来?它们分别对应了模型结构、数据要求和目标函数的变革(图5)。深度学习已经分别与预训练和强化学习进行了较好的融合,将预训练和强化学习融合可能是一个潜力巨大的研究方向。预训练对人类已有知识和经验压缩,其受限于概率建模的约束,创造未知知识的小概率事件很难发生。强化学习通过平衡利用和探索,通过增加随机性,有潜力打破LLM依赖人类设计的局限,实现更高层次的智能。进一步,预训练对应连接主义、强化对应行为主义,如果将思维树等有系统二思想的结构化推理看成是一种符号系统,Q*也算是三种主义一次有趣的重逢,这样的结合不仅能够从数据中学习复杂的模式,还能进行结构化的思考和决策,有望提高AI的适应性、灵活性和解释性。
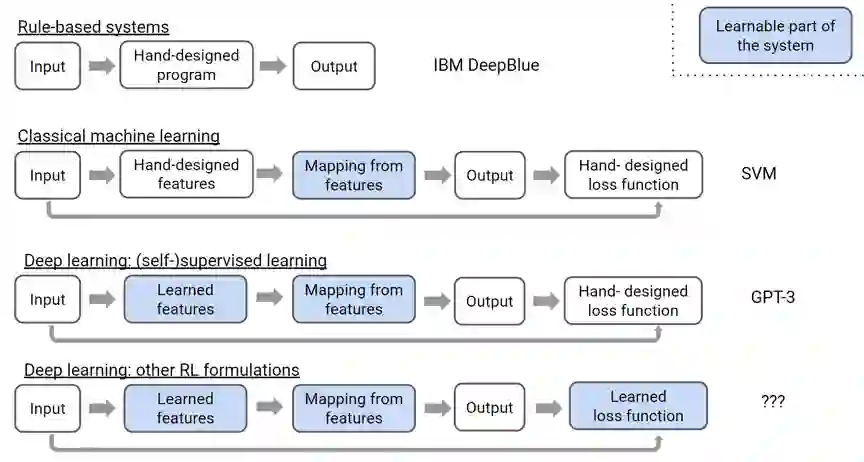
图4 不同方法中的手工设计和可学习模块[D5]

图5 深度学习vs预训练vs强化学习
回到关于Q的讨论。预训练和强化学习结合的一个挑战是如何获取奖励数据。猜测一采用的是模型自动标注的合成数据。参考AlphaGo的奖励设计方式,应该如何获取奖励数据才能超越人类已有知识的约束?让我们试着从IIya Suskever身上寻找答案。首先是两个访谈。今年3月的一个访谈中[D6],IIya介绍了RLHF中人训练奖励函数然后奖励函数训练模型的原理,主持人Dwarkesh Patel随即非常犀利地问到:“是否有可能将人类反馈从循环中移除,以类似AlphaGo的方式自我演进?”IIya并没有正面回答,而是从安全的角度回避了这个问题(图6)。在今年11月初的另一个访谈中[D7],主持人问模型能力持续提升的主要推动力是什么?IIya毫不犹豫地说是数据,但又接着说:“不详细说明,我只想说数据限制是可以克服的。”(图7)在访谈的后面,IIya提到:“我们最近会发布一个非常令人兴奋的研究成果。”不得不令人遐想这和十多天之后宫斗以及Q传闻的关系。不过自从ChatGPT发布甚至是GPT-3之后,OpenAI就开始对技术语焉不详,我们很难从中找到想要的答案。
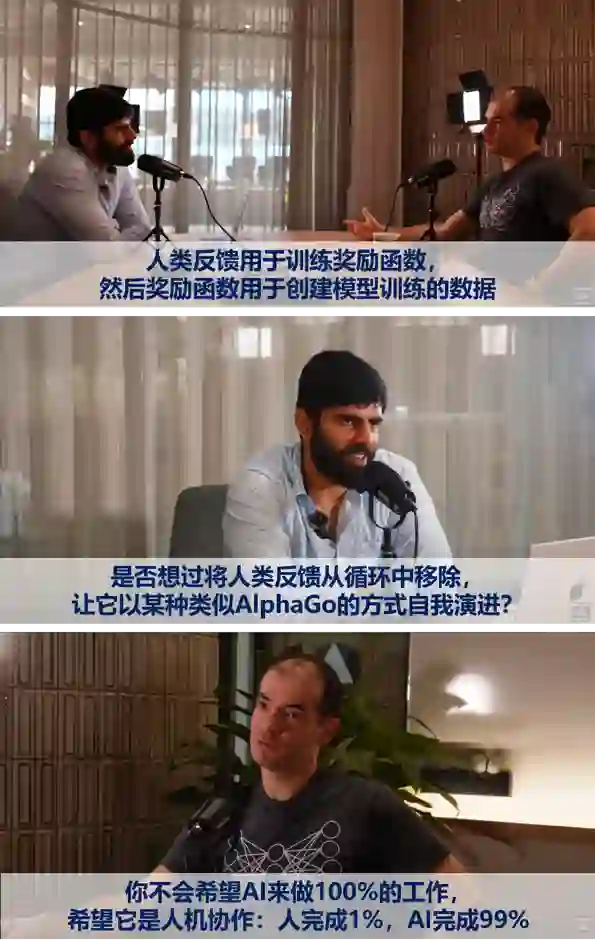
图6 Dwarkesh Patel对IIya Suskever的采访 [D6]
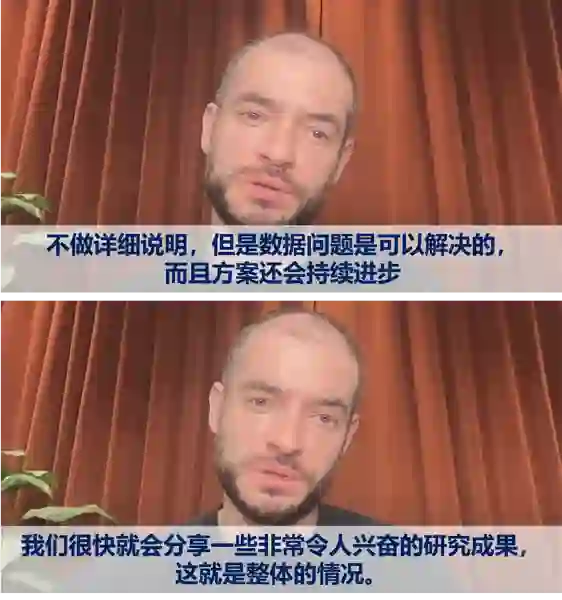
图7 Priors对IIya Suskever的采访 [D7]
答案可能要从更久的资料中去找。2018年初IIya在MIT作了一个题为“Meta Learning & Self Play”的报告[D8]。报告首先令人印象深刻的是他对强化学习的理解,他认为相比监督学习的确定性目标(包括自监督学习),强化学习的本质是“为动作增加一点随机性,如果结果好,未来就继续执行这个动作”(图8上),个人认为这个认知是非常深刻的。其次,IIya那时对元学习的关注就不是小样本学习这种类别层的泛化,而是“在多个任务训练,然后解决未见过的任务”的任务层的泛化,为后来指令学习的实践和任务涌现奠定了基础。 报告的后半部分是猜测二的主角:Self Play自我博弈。在演示了多个自我博弈的应用视频后,IIya先用一句话精辟总结了自我博弈的作用:自我博弈可以将计算转化为数据(图8中)。然后对自我博弈能否实现AGI给出了肯定的回答:“开放式的自我博弈可以产生心智、社交能力和真正的语言理解”(图8下)。报告后的QA环节也信息量巨大,问题和回答同样精彩,快6年之后再来考古,当时的很多对话都让人起鸡皮疙瘩。不过除了QA环节的一个问题,整个讲座IIya都没有提语言建模,这也让Q*项目有了超越大语言模型的可能:不要忘了OpenAI早年的重心是在让AI控制鼠标键盘 (OpenAI Universe)、深度强化智能体(OpenAI Gym、OpenAI Five)和模仿机械手(Dactyl)这些项目上。如果和虚拟现实模拟各种环境结合,会有很多想象空间。
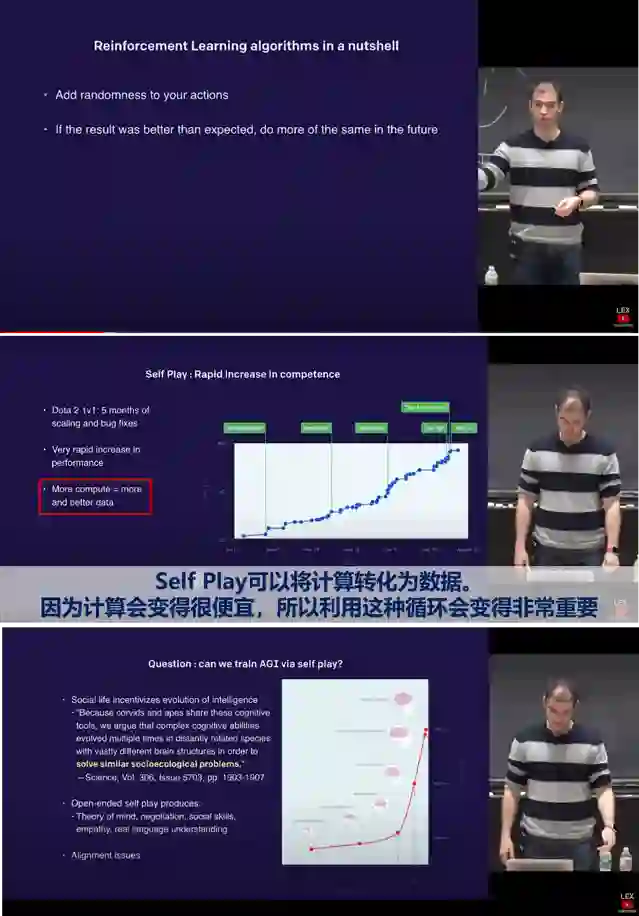
图8 IIya 2018年的讲座: Meta Learning & Self Play [D8]
结合IIya Suskever的两段访谈一个报告和Andrej Karpathy的报告,我们似乎可以得出结论:如果OpenAI旨在让语言模型突破人类局限,Self Play会是他们设计强化奖励规则的选择。然而,为语言建模设计一个类似于围棋输赢的Self Play奖励机制并不容易,语言的复杂性和多样性使得定义“胜利”的标准变得非常困难。 这里结合最近LLM-based AI Agent的工作,脑洞一下语言建模中Self Play可能的玩法:为LLM设计不同的角色或立场,并为之设置竞争或协作的博弈任务。 * **竞争型任务比如辩论和数学问题解答。**辩论任务中将模型分为正反两方,围绕一个主题展开辩论,语言模型需要生成有说服力、逻辑性强的论据和观点来反驳对方,循环进行。或者可以模仿《对话录》的形式,让大模型扮演不同的古希腊哲学家,在相互提问和思辨式对话中完成智力演化。数学问题解答任务中一个模型出数学题,另一个尝试解答。出题模型旨在设计出更有挑战性的题目,解题模型则需要努力找到解决方案。竞争型自我博弈可以促进模型相互挑战和增强,有助于提升模型的多样性和创新性。 * **协作型任务可以让模型相互补充或者互为演员和评论家。**补充类任务比如故事续写,让两个模型连续创作一个故事的不同部分,目的是创造一个连贯、吸引人和富有创意的故事。演员-评论家类任务比如代码生成和审查,一方负责写出高质量代码,另一方进行代码审查和优化建议,目的是生成高效、无误且优化良好的代码。也可以泛化到更一般的创作任务上,比如图像设计、音乐生成等,让一个模型担任图像和音乐创作者,另一个模型负责对创作进行评价和改进,使多模态能力提升也成为可能。这种协作型自我博弈在提高生成内容的连贯性、逻辑性等方面可能更有意义。
以上讨论了猜测二的要素2-奖励数据自动获取:为语言建模的训练过程引入自我博弈任务。关于要素1-搜索,仍然可以沿用猜测一中的思维树的思路,与自我博弈结合可以提高训练中智能体的推理能力和决策质量。 今年10月Geffrey Hinton、IIya Sutskever、Demis Hassabis共同参加的一个在线活动上[D9],Demis Hassabis认为创造力分为三个层次,分别是插值(interpolation)、外推(extrapolation)和发明(invention)。根据这个分类,ChatGPT目前仍然停留在第一个层次:对已有知识进行插值和组合,显然已经做到了顶级水平。AlphaGo与李世石第二局中的第37步是第二层次外推的代表:下出了人类棋手没见过的策略。猜测二中讨论的通过自我博弈突破人类监督限制,可以看成是在探索大模型的第二个层次。关于第三个层次,Hassabis认为它关注的“不是围棋中下了一步好棋,而是发明了一种新的棋类游戏”。对应到大模型,可能需要它发现新的数学猜想和定理。那可能如何实现呢?回想AlphaGoZero抛弃了模仿学习人类棋谱,在只有规则的情况下无师自通打了AlphaGo个100:0。难道人类知识只作为先验也是有害的?类似的,如果抛弃预训练阶段对语料的拟合,让模型突破人类语法限制、甚至开发出自己的语言,会是实现第三个层次的解决方案么?
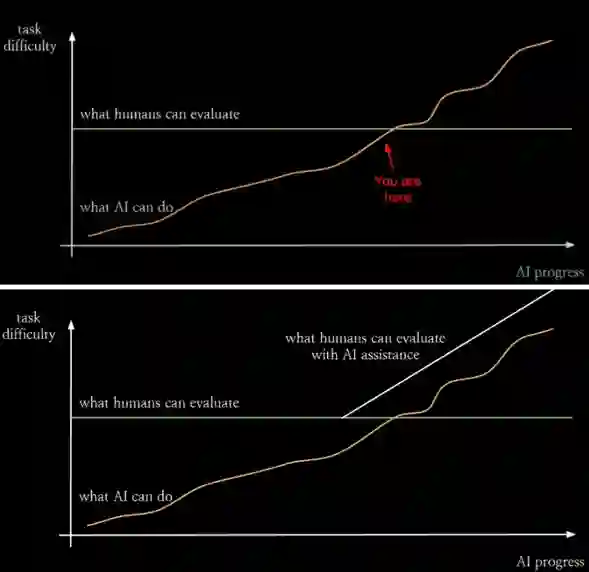
图9 OpenAI超级对齐 [D10]
讨论:安全与对齐
最后讨论一下这背后的安全和对齐问题。上面猜测的对强化学习的拓展显然已经超出了现有RLHF来实现价值对齐的目标。**能力超越和价值对齐像是矛和盾的关系:一个探索能力上限、一个确保安全底线。**IIya在[D8]报告的最后讲到了OpenAI安全团队当时在对齐人类偏好方面的工作[L3],看似和前面讲的Self Play有点不搭。但结合上面的猜测,OpenAI如果坚信类似Self Play的方法能让AI能力超越人类,讨论安全和对齐就十分必要。实际上,论文[L3]中的多位作者、同时也是OpenAI安全团队的核心成员,已于2020年底出走创办了今天OpenAI的主要竞争对手Anthropic,而Anthropic成立宣言就是致力于安全、可解释的AI。 OpenAI的这次宫斗还贡献了两个新名词:有效加速主义和超级“爱”对齐。将时间调回今年7月,OpenAI高调成立了一个名为Super Alignment(超级对齐)的新部门,其两位联合负责人是IIya和Jan Leike(论文[L3]的第二作者)。图9是Jan Leike今年1月的一个报告截图,展示了随着AI能力演进(橙线)人类理解和评估能力的相对停滞(绿线)。在橙线未穿越绿线的情况下(图9上),人类能够有效理解和评估AI的策略和行为,我们尚可以使用类似RLHF人类监督反馈的方式进行价值对齐。但当AI能力继续提升,AI系统可能发展出超越人类直观理解的复杂策略和行为模式(图9下),这时人类母亲将难以准确评估和指导这些AI系统,确保其决策和行为符合人类价值观和伦理标准将会非常困难。所以,从技术上看,超级对齐和能力进化都需要突破人类反馈的限制。 到了这一阶段,实现价值对齐可能有两种思路。一种是内在、先天的,类似婴儿一出生就有的基因,要在AI设计之初、自我博弈之前内嵌一套价值和伦理规则,确保它们的行为自然而然地符合这些原则,从根本上符合人类价值观。这有点像为AI加入人类价值观钢印,或者是赋予底层的类似“机器人三定律”的第一原则。另一种是外在、后天的,类似老师和警察进行指导和监督,但这里的老师和警察本身也是AI,需要同步进化。这大概就是OpenAI超级对齐的building AI for AI alignment思想。“老师”AI负责提供指导和训练,帮助其他AI系统学习正确的人类价值观[1],Anthropic采取的Constitutional AI思路和RLAIF[L4]应该属于这种类型,用HHH准则(Helpful, Honest, Harmless)驱动AI行为。“警察”AI则负责监督和纠正AI行为,确保它们不偏离既定的道德和伦理标准、并始终符合人类利益。超级智能推动AI探索未知、扩展智能的边界,超级对齐确保AI发展与人类价值观和利益一致、设定安全和伦理底线。两者缺一不可。 注[1]:OpenAI在12月14日发布了超级对齐团队的第一篇论文:Weak-to-strong generalization: eliciting strong capabilities with weak supervision。论文认为,以对齐为目标,我们不需要去教模型新的能力,只需要激发模型发现”不知道自己知道”的能力。也就是说,需要的不是知识渊博的权威式老师,而是循循善诱的启发式老师。 参考文献
[D1] 知乎关于Q的讨论。 https://www.zhihu.com/question/631474975 [D2] Nathan Lambert. "The Q hypothesis: Tree-of-thoughts reasoning, process reward models, and supercharging synthetic data. " Blog, 2023.11.24 [D3] https://www.wired.com/story/google-deepmind-demis-hassabis-chatgpt/ [D4] Andrej Karpathy. "The busy person’s intro to LLMs. " Talk, 2023.11 [D5] Hyung Won Chung. "Large Language Models (in 2023). " Talk, 2023.10.06. https://www.youtube.com/watch?v=dbo3kNKPaUA [D6] The Lunar Society 主理人 Dwarkesh Patel对OpenAI 首席科学家 Ilya Sutskever的采访。https://www.dwarkeshpatel.com/p/ilya-sutskever [D7] No Priors对IIya的采访。https://www.youtube.com/watch?v=Ft0gTO2K85A [D8] Ilya Sutskever. "Meta Learning & Self Play." Talk, 2018. [D9] Geffrey Hinton, IIya Sutskever, Demis Hassabis. "Research on Intelligence in the Age of AI." Panel, 2023.10.07. [D10] Jan Leike. "Language and Human Alignment". Talk, 2023.01.17. 参考论文
[L1] Yao, Shunyu, et al. "Tree of thoughts: Deliberate problem solving with large language models." arXiv preprint arXiv:2305.10601 (2023). [L2] Lightman, Hunter, et al. "Let's Verify Step by Step." arXiv preprint arXiv:2305. 20050 (2023). [L3] Christiano, Leike, et al. "Deep Reinforcement Learning from Human preference." [L4] Bai, Kadavath, et al. "Constitutional AI: Harmlessness from AI Feedback." E N D 观点&文案:桑基韬 排版:赵宪 责任编辑:桑基韬,黄晓雯


