

导语
伴随着 ChatGPT 引发的AI浪潮,从年初的斯坦福小镇,再到最近OpenAI开放的GPTs商店,大语言模型驱动的智能体(Agents)展现出令人惊叹的智能水平和广阔的应用前景,引发各行各业的广泛关注。而在此之前,强化学习和机器人领域的学者已经在长期进行Agents相关的研究。因果强化学习(Causal RL)这一新兴领域的核心,即是让 Agents 能更好地理解环境中的因果关系,做出更好的决策。**
近日,集智俱乐部因果科学社区成员、悉尼科技大学博士生邓智鸿参与的一篇因果强化学习综述被Transactions on Machine Learning Research (TMLR) 正式接收,本文从Agents、因果、结构因果模型等基础概念讲起,介绍了这篇综述的主要内容,以及对因果强化学习的深入思考。作者认为,对于探讨 Agents 和人类的关系而言,除了多模态和具身,因果也是一个很好的切入点。**********
研究领域:因果科学,因果强化学习,AI Agent,结构因果模型****************************************************************

论文链接:
TMLR:https://openreview.net/pdf?id=qqnttX9LPo ArXiv:[2307.01452] Causal Reinforcement Learning: A Survey (arxiv.org) https://arxiv.org/abs/2307.01452 Tutorial:
Causal Reinforcement Learning: Empowering Agents with Causality https://2wildkids.com/talks/2023-08-21-ADMA_tutorial Github项目(资源汇总,持续更新中):
我们也非常欢迎大家一起为这个项目做贡献! GitHub - familyld/Awesome-Causal-RL: A curated list of causal reinforcement learning resources. https://github.com/familyld/Awesome-Causal-RL
前言
这次跟大家分享一下的是我们最近正式被Transactions on Machine Learning Research (TMLR) 接收的关于因果强化学习(Causal RL)的综述论文。Causal RL是一个非常有趣的新兴领域,它的核心是让智能体(Agents)能够更好地理解环境中的因果关系,从而做出更好的决策。这篇文章除了介绍综述里的部分内容,我也会简单地分享一点对这个话题的思考。为了避免讨论太过发散,我们不妨先约定以下几点:
一、承认一个事实:Agents不理解因果
截至2023年底,agents在理解因果上仍存在较大的不足。ChatGPT是基于LLMs的Agents中最先进的之一,我们可以用它举个例子: 
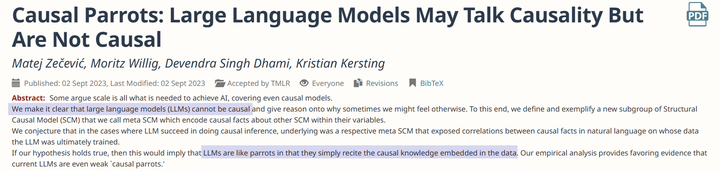
causal parrots. 作者将这种现象称为“Causal Parrots”。简单来说,这意味着这些最为强大的智能体,即便表现得很像人类,依然只是在重复着训练数据中已经存在的因果知识,没有真正地理解这些知识,就像学舌的鹦鹉一样。
二、宣扬一种价值:Agents应当理解因果
在了解到以上事实的同时,我们有时也会听到一种声音:智能体不需要理解因果,毕竟人类自己也总是犯错。有些时候,我们依赖相关性做的决定就很不错,何必追求(让agents理解)因果呢?虽然ChatGPT等智能体不完全理解因果,但这并不阻碍它们快速成为许多人的工作流中不可或缺的一环。在对话这个场景中,依靠互联网级别的数据、足够大的模型容量和少量的对齐,大部分可以基于自然语言表达的任务似乎已经能被解决。 但我们认为,在“可用”和“可以可靠地使用”之间仍然存在一道巨大的鸿沟。如果我们希望让智能体更深度地参与到人类社会中,特别是做出与人有关的重要决定,就不能满足于“可用”,而必须在“可以可靠地使用”这个方向上开辟新的路线 —— Causal RL正是这样一条路线。用Judea Pearl的话[2]来说: 我相信因果推理对智能机器至关重要,它可以让智能机器使用我们的语言与我们交流策略、实验、解释、理论乃至遗憾、责任、自由意志和义务,并最终让智能机器做出自己的道德决策。 因此,让agents理解因果是有价值的,这是一件值得追求的事。这种价值不仅仅体现于让agents能自然地与人类交流它们的选择和意图,也在于提高我们对agents的信任,将我们从对超人工智能的恐惧中释放出来。
三、如何让Agents理解因果?仍然有待研究
如果说我们可以在前面两点上达成共识,那么这第三点就有很多种答案了。 我们是人工指定因果方面的知识呢,还是只提供某种第一性原理,让agents自己学习呢?是让agents在与环境交互的过程中学习呢,还是让agents通过仅学习历史数据来理解因果呢?是将因果推理模块集成在模型内部呢,还是作为一个外部工具供模型调用呢? 每一个不同的选择都可以导出许多有意思的解决方案,它们所采用的技术也不尽相同。在这篇综述里,我们根据四个大问题对causal RL的现状进行了梳理,它们分别是:如何提高agents的样本效率,如何增强agents的泛化能力与知识迁移,如何缓解伪相关对agents的影响,以及如何促进agents的可解释性、公平性和安全性。随着agents的不断发展,新的问题也会陆续出现,欢迎大家补充和分享~ 在正式开始前,我们先补充一点基础知识,帮助大家理解因果是如何被数学化的。
亿点点基础知识
首先介绍Judea Pearl的结构因果模型(Structural Causal Model, SCM)[3]:

这是一个四元组,包含内生变量集,外生变量集,结构方程集和外生变量的联合分布。内生变量就是我们感兴趣的变量,比如MDP里的状态和奖励等等。外生变量代表的则是那些我们不关心的变量,所以也叫背景变量或者噪声变量。这些变量通过结构方程联系在一起。每个结构方程指定了一个内生变量的取值方式,其中方程左侧变量是果,方程右侧的内生变量则是对应的因。因为方程本身是确定性的,所以所有的随机性都源于外生变量。换句话说,给定所有外生变量的取值,内生变量的取值也就随之确定。通过这样的方式,SCM刻画了系统(世界)运行的规律,我们可以借助它来理解不同的因果概念。 前面我们提到相关关系不等价于因果关系,我们可以用饼图来更好地理解这种区别:
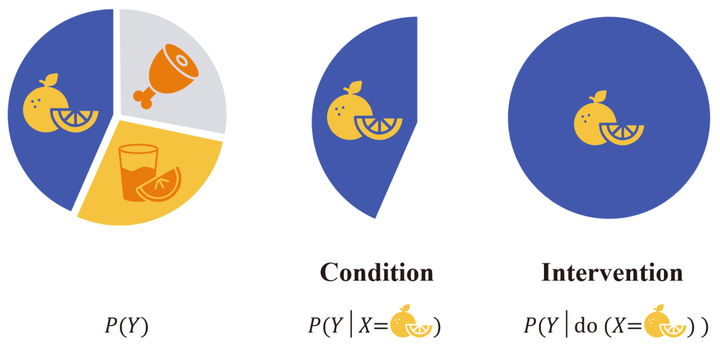
假设完整的饼图对应我们感兴趣的总体,比如所有的水手。这个总体可以根据食用不同的食物划分成三块,我们将其记作变量X,然后用变量Y表示是否患上疾病。我们希望问的问题是:食用某种食物是或否会让水手患上该疾病? 在传统的机器学习中,我们可能会尝试建立一个预测模型来拟合条件分布P(Y|X) 。然而,条件分布的研究对象是整体中的一部分,它能回答关于相关性的问题,比如:如果我们(被动地)观察到水手食用了某种食物,他们有多大可能会患上这种疾病?而实际上我们感兴趣的是一个因果问题,如果我们(主动地)实施某种干预,会有什么变化?为了区分两者,研究者引入了do算子。干预分布P(Y|do(X=x)) 表示当所有水手都被要求食用某种食物时,他们有多大可能会患上这种疾病?看起来只有些许的差别,但这非常重要。 如果模型只能回答相关性问题,那我们将难以从模型的预测中得出可靠的结论。这种相关性有可能是由模型遗漏的某个混杂因素(X和Y的共同原因)引起的。或许食用该食物本身不会导致患病,但是某个未知的基因会让人既偏好于这种食物又更容易患上疾病(这会造成两者之间呈现出虚假相关)?如果所有水手都食用这种食物,而不是受到某种未知原因的影响,我们就能解开这个疑惑。从SCM的角度来看,do(X=x) 实际上是删除了变量X的结构方程,将X的取值方式设定为X=x ,这就创造出了一个满足X=x的,和原本的世界有着最小差异的世界。 也许有人会问:强迫所有水手都食用相同的食物真的可行吗?这种做法似乎既不现实也不道德。如果我们没有办法做到这一点,要如何确保模型可以学习到我们感兴趣的干预分布呢?这就不得不提到因果科学最重要的研究成果之一—— 如何在不实际实施干预的情况下预测干预的效果。还是用上面的例子来讲解,我们可以将假设表达为图的形式,其中每个顶点代表一个内生变量,存在和缺失的边代表我们对因果关系的假设。X→Y 代表我们假设食用某种食物可能会导致患上疾病。X←Z→Y 代表我们假设存在某个混杂变量 Z 既会影响食用的食物又会影响患上疾病的概率。如此,可以得到图3.3:

类似地,要表达所有水手被要求食用同样的食物,我们可以从图3.3中移除X←Z这条边,得到图3.4。换句话说,图3.4表达的是一个被干预的世界,在这个世界中,我们关心的干预分布P(Y|do(X=x)) 与条件分布Pm(Y|X=x)相同。利用基础的概率论知识,我们可以做以下推导:
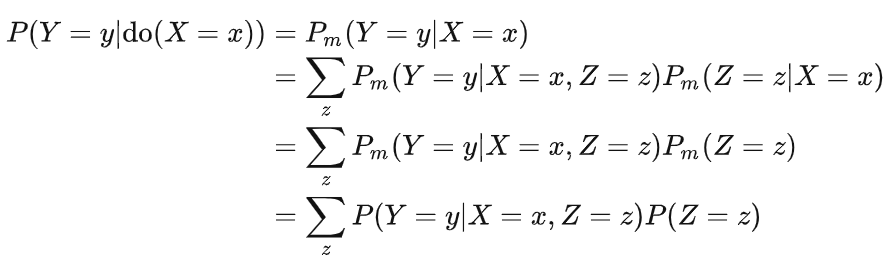
第三个等号利用了不存在X→Z这个假设,也就是说变量X的变化不到导致变量Z 的变化,所以条件概率等于边缘概率。第四个等号利用了两个不变性:边缘概率P(Z=z)在干预前后不变,移除X←Z并不影响Z的取值过程;条件概率P(Y=y|X=x,Z=z)在干预前后不变,因为无论X 是自发变化还是被设定为固定值,Y 的结构方程(产生Y的过程)也是不变的。那么这个结论有什么用处呢?它恰恰就解决了我们之前烦恼的问题。看等式的右边,我们可以看到表达式中的两项都是普通的概率,没有do算子也没有下标m。这意味着我们可以使用观测数据回答因果问题!当然了,在实际中,变量Z 并不总是可被观察的,所以有些时候我们感兴趣的因果量并不总是可被识别的。 除了干预,因果科学里还有一个非常重要的概念:反事实。在传统机器学习里,我们几乎从不讨论这个概念,但它在我们的日常生活中相当常见。沿用上面的例子,在观察到食用tomapotato的水手患上神秘疾病之后,我们往往会思考一个问题:如果这些患上疾病的水手当初没有食用tomapotato,则结果会变成什么?经典统计学中没有合适的语言可以表述这样的问题,这是因为我们无法用被动观察的经验数据准确地刻画“回到过去”(如果...当初)和“干预”(没有食用)这两个概念。要表述出那个正确的问题,我们必须考虑因果关系,并且不能止步于干预这一层次。为什么呢?借助do算子,我们可以试着表述上面的问题: P(Y|do(X=x′),Y=1) 我们会发现这里出现了两个Y ,它们的含义不同。第一个Y 表示水手没有食用tomapatato的结果,第二个Y 表示水手食用了tomapatato的结果。为了区分这两种情况,我们需要用到一种新的语言——潜在结果(potential outcome)[4],通过引入下标来指定特定变量的取值。对于个体u 而言,我们可以将其食用tomapatato的潜在结果记作YX=x(u) ,没有食用的潜在结果记作YX=x′(u)。显然,对于同一个体,我们只能观察到一种潜在结果(事实世界中的结果)。对于那些未被观察到的潜在结果,我们想象存在着多个平行世界(反事实世界),它们是在平行世界中被观察到的结果。借助潜在结果,我们可以将感兴趣的量表述为: P(YX=x′|X=x,YX=x=1) 这里首先将条件do(X=x′) 合并到目标变量中得到YX=x′,因为这才是我们真正感兴趣的目标。然后,我们补全了条件,原本的Y=1 实质上是指X=x 和YX=x=1 这两个条件。又因为YX=x所表达的潜在结果和条件X=x是一致的,所以我们可以进一步将这个概率改写为: P(YX=x′|X=x,Y=1) 这个概率表达的是:如果我们观察到X=x,Y=1,那在X=x′的世界里会有怎样的结果?这正是我们想问的问题。从SCM的角度来看,要算出这个反事实量需要三步:首先,我们要根据掌握的事实X=x和Y=1反推外生变量U的值;然后,我们要根据do(X=x′) 修改结构方程,建立平行世界;最后,将U的值代入修改后的结构方程组就可以计算出反事实变量的值了。这个流程本身非常透明,所以反事实不只是一个空想的概念,它是可被严谨地刻画的。然而,因为SCM在实际应用中通常是未知的,这个流程在实际计算中未必可用。在这种情况下,我们通常可以引入一些定性假设(比如因果图)来辅助涉及到反事实的计算。 到目前为止,我们介绍了SCM,它提供了一种用数学语言刻画遵循特定因果规律运行的世界模型的方式。我们强调了相关关系和因果关系的区分,并在SCM的基础上引入了干预和反事实。这些概念并不是为了堆砌专业术语,而是为了填补传统统计学只问相关不问因果的不足。新的推荐算法是否能提高点击率和用户留存率?如果病人当初没用采用了某种治疗手段是否更容易康复?一所大学的录取决定是否涉及到性别和种族歧视?这些都是因果问题,它们推动着科学和社会的发展。试想一个由相关性而不是因果性统治的世界,在那样的世界里我们可能因为多吃冰淇淋而被鲨鱼袭击或者因为害怕死亡而不去医院接受治疗,这样的世界是荒谬的。 OK,基础部分到这里就结束了。因果科学是一个非常庞大的领域,还有很多值得了解的概念、术语和技术。但为了让这篇文章更紧凑一些,我们就不进一步展开了 ️,感兴趣的读者可以参考我们的综述论文,相关书籍[3][5],以及专栏里的博客:Zhihong Deng:【干货】《统计因果推理入门》读书笔记https://zhuanlan.zhihu.com/p/380711267
回到强化学习的话题上,基础知识就不多说了。在看完关于因果的内容之后,大家可能会对两个概念有一些思考: 1.强化学习里的策略和因果里的干预之间有什么联系?2.强化学习的基于模型的强化学习(MBRL)中的model和因果模型有什么联系? 会马上想到这两个问题说明你的思维很敏锐 。首先,在强化学习中,agents和环境交互这个过程本身就是一种干预。但这种干预通常不是直接将变量At 设定为一个固定值,而是保留了对状态变量St 的依赖。既然我们承认策略是一种干预,那就自然会有一个疑问:强化学习本身是否学习了因果关系?对于on-policy RL来说,agents确实学习了动作对结果的总效应(total effect),并且on-policy方法通常比off-policy方法效果更好也支持着这一点。但我们需要认识到,环境本身还存在其它因果关系,比如相邻时间里各状态维度之间的因果关系。如果缺乏对这些因果关系的理解,agents的能力就会局限于单个固定环境中。当环境发生变化时(比如环境中的其他因素受到外部干预),它的效果会大打折扣。对于第二个问题,尽管传统的MBRL学习了环境模型(有的时候大家喜欢用世界模型这个说法),但它止步于相关关系。一旦环境中存在不可观察的混杂因素,学到的模型也会变得不可靠(不妨思考一下前面的例子)。 在这一节的最后,我们给出论文中对causal RL的定义: Definition (Causal reinforcement learning). Causal RL is an umbrella term for RL approaches that incorporate additional assumptions or prior knowledge to analyze and understand the causal mechanisms underlying actions and their consequences, enabling agents to make more informed and effective decisions.
这个定义比较宽泛,它主要强调两点:一、它强调对因果关系的理解,而不是浮于表面的关联关系,并以此提升agents的决策能力;二、为了实现第一点,causal RL通常需要结合一些额外的假设和先验知识。它不像元强化学习或者离线强化学习等领域那样有一个统一的问题设定或者致力于解决某类任务。Causal RL的工作通常会根据一个研究问题的难点灵活地设计解决方案。因此,我们在综述里采用了problem-oriented的分类体系:泛化和知识迁移,虚假相关,样本效率,可解释性、公平性和安全性。接下来,我会挑选一部分论文来简单地讲解causal RL在这些问题上提供的一些新视角。
样本效率
首先,我们知道样本效率太低是强化学习常常被诟病的一个原因。围绕如何提升样本效率而开展的研究工作已经非常多了,这里介绍两个与causal RL有关的工作。 第一篇工作是发表在NeurIPS 2021上的Causal Influence Detection for Improving Efficiency in Reinforcement Learning[6]。它考虑的是一个robotic manipulation问题:
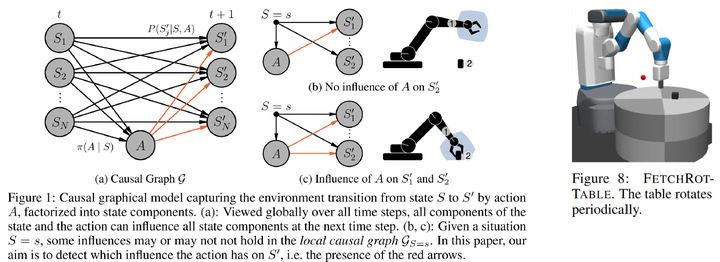
在强化学习中,状态空间通常被看成一个整体,但我们可以根据状态维度的物理意义对其进行拆分,使得每个部分对应一个实体,比如机械臂的end effector和桌子上的物体。对于这个任务来说,agent要取得成功就必须先与物体建立物理接触,只有这样它才有可能可以移动物体到指定的位置。从因果的角度来看,建立物理接触的本质就是看动作是否能在因果上影响到物体。因此,我们可以构造一个因果量用于测量动作对物体的因果效应,这在论文中被称为causal influence。基于causal influence,我们可以指导agent如何更有效地探索环境 —— 优先探索可以与物体建立物理接触的区域,从而提高样本效率。这个方案简单有效,很好地避免了agent在庞大的状态-动作空间中进行无意义的探索(比如:随机地在空中挥舞机械臂)。 第二篇工作是DeepMind在ICLR 2019上发表的,叫做“Woulda, Coulda, Shoulda: Counterfactually-Guided Policy Search”[7]。它考虑的是一个episodic POMDP问题:
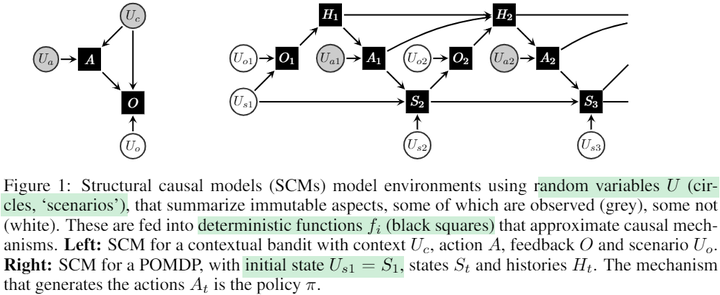
它的想法很简单:现有的很多MBRL方法是从头开始合成数据,但是对人类来说,一个普遍的做法是借助反事实推理能力来更充分地利用经验数据。举个例子,在获得某次失败经验后,我们常常会思考回到某个时间点改变某一次选择所带来的结果,这种思考方式大大提高了我们的学习效率。类似地,我们希望agents也能运用反事实推理能力来加速学习:
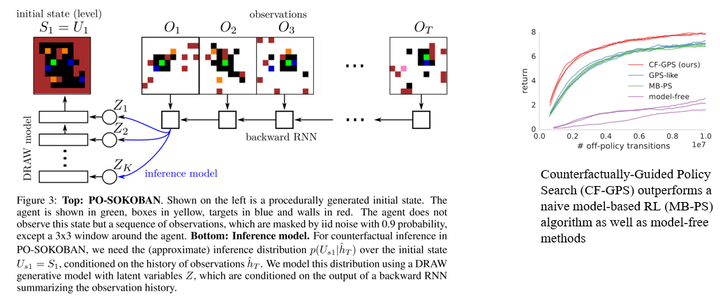
实验环境是一个推箱子游戏,绿色的是agent的本体。以本体为中心的3×3范围是可观察的,地图的其它部分则有90%的概率会被mask掉,所以这是一个POMDP问题。作者采用了一个比较理想的设定,假设环境的dynamics是已知的,这样模型只需要专注于如何推理外生变量分布就可以了。实验效果很好地验证了这个思路的有效性,反事实推理帮助agent提高了样本效率。 除了这两篇工作展现的思路之外,还有一个常见的思路是学习因果表征 —— 去除掉冗余的维度,让agents专注于那些会影响到结果的状态维度上。这样相当于在不影响决策的前提下简化了问题,从而可以间接地提高样本效率。
泛化和知识迁移
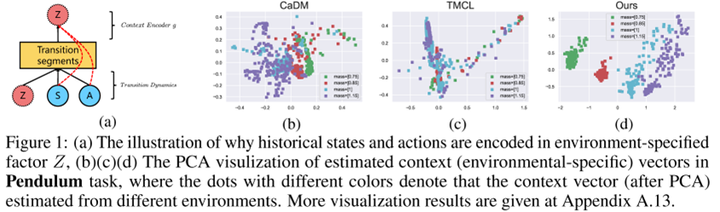
传统的RL大多是在同一个环境上进行训练和测试的,但近年来有越来越多的算法研究和benchmark关注agents的泛化能力和知识迁移能力,比如关注meta-learning, multi-task learning和continual learning等设定。这些问题普遍涉及多个不同但相似的环境和任务,在因果视角下,我们可以将这类变化解释为对上下文变量的干预。举个很简单的例子,在robotic manipulation中,要求agent对颜色变化鲁棒实际上就等价于把颜色作为一个上下文变量,然后要求agent学会该contextual MDP下的最优策略。这个contextual MDP可以用一个因果模型来描述,其中改变颜色只干预了该模型中的其中一个变量,并且这个变量可能与结果无关。在这种情况下,理解因果的agent对颜色的变化是鲁棒的,可以很轻松地泛化到新的环境中。如果被改变的是物体的质量,那么agent只需要adapt与质量对应的部分就可以了,不需要调整整个模型。 这一节同样以两篇工作为例讲解causal RL提供的思路。第一篇是ICLR 2022的“A Relational Intervention Approach for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning”[8]。这篇工作研究的是MBRL中环境模型的泛化问题,其中决定变化的上下文变量(比如天气、地形等因素的变化)是不可观察的。那么在传统的MBRL方法中,通常会用轨迹片段来编码上下文信息,但是这个过程就容易把来自状态和动作的无关信息也编码到上下文信息中,从而影响了上下文的准确性:
作者提出了一个因果启发的方法,它的架构如下:
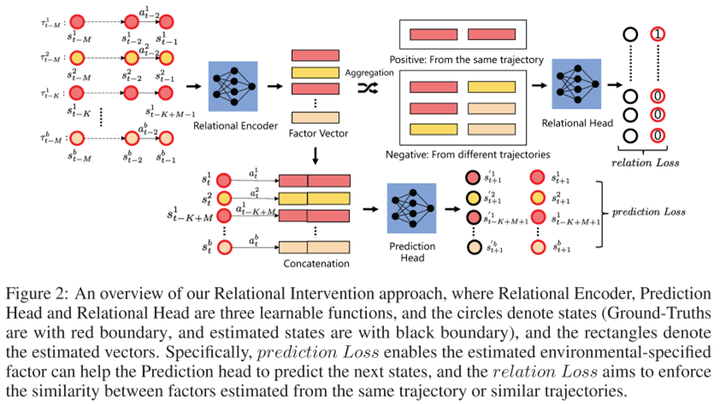
首先,学习模型肯定有一个prediction loss,通过当前状态S 、动作A 、以及上下文Z 来预测下一时刻的状态S′ 。此外,为了学习如何编码上下文,还需要一个relation loss。它的目标是使同一条轨迹或者同一环境产生的相似轨迹的上下文变量尽量一致。这里的难点在于如何判断轨迹是否来自同一环境。从因果的角度来看,在同一环境中,上下文变量对S′ 的因果效应应该是相近的,所以我们可以用这个因果效应来判断轨迹是否同属一个环境。进一步地,Z 到S′ 有多条因果路径,比如可以是Z→S→S′ 和Z→A→S′ 。作者认为这些间接路径容易受到噪声的影响,所以选择测量受控直接效应(controlled direct effect, CDE),也即仅通过Z→S′ 这条直接路径传递的因果效应 。实验表明这个方法不但能降低状态转移的预测误差,还能在新环境上取得很好的zero-shot泛化效果。从图1的PCA结果来看,这个方法学到的上下文变量很好地捕捉了环境的变化。 第二篇要介绍的工作同样发表在ICLR 2022上,标题是“AdaRL: What, Where, And How to Adapt in Transfer Reinforcement Learning”[9]。这篇论文关注的是强化学习中的迁移学习问题。具体来说,在训练的时候,agent可以access多个不同的source domains,然后测试的时候需要在只获取target domain的少量样本的情况下取得好的效果。论文提出了一个称为AdaRL的框架:
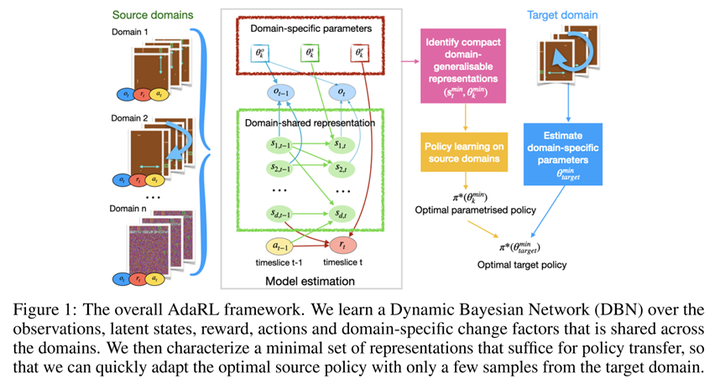
具体来说,作者将模型分成domain-specific和domain-shared两部分。domain-specific的参数是低维的,它刻画了特定domain中包含的变化,这种变化可以体现在对模型的观察、状态和奖励的影响上。domain-shared的参数包含各状态维度,动作和奖励之间的因果关系(因果图上的边),以及它们的底层的因果机制。通过利用来自多个source domains的数据,agents可以很好地学习出因果模型,这是可以可靠地迁移的知识。同时,低维的domain-specific参数只需要通过target domain的少量样本即可得到,所以这个框架非常灵活。
虚假相关
虚假相关也是一个非常普遍的问题,但是传统的强化学习很少会关注这方面的问题。下面以推荐系统为例介绍两种类型的虚假相关:
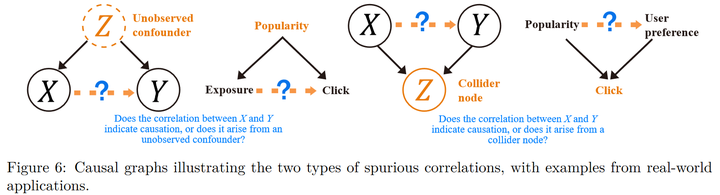
第一类称为混杂偏差,两个变量之间可能本来不存在因果关系,但是因为有一个不可观察的混杂变量同时影响这两个变量,所以它们会存在很强的关联。第二类称为选择性偏差,这种情况下两个变量之间的关联是在给定第三个变量时产生的。因果推断中分析和处理这两类问题的技术都很成熟,所以我们主要需要关心的是在强化学习的问题中存在哪些虚假相关。 这里通过发表在NeurIPS 2019的“Causal Confusion in Imitation Learning”[10]进一步讲解一下策略学习中的混杂偏差。直觉上,我们通常认为可用于决策的信息越丰富越好,一个模态不够要用多个,有的时候特征不够还要造特征。但这篇论文里提出了一个很有意思的说法 —— 拥有更多的信息并不总是更好的:
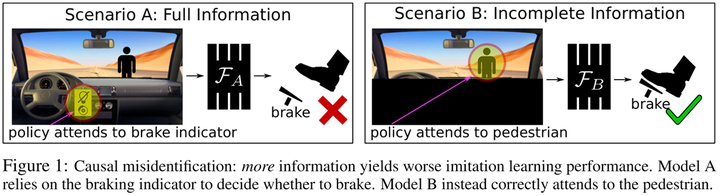
在这幅图展示的例子里,行人的出现是刹车指示灯亮起和刹车行为的共同原因(混杂变量)。如果agent可以观察到刹车指示,那它可能会误以为是刹车指示导致了刹车这个行为。但如果agent只能专注于车子前面的路况,那它就会正确地学习到前方的行人才是导致刹车这个行为的原因。如果agent学会的是前者,那它就会危险驾驶。 我们今年被TPAMI接收的“False Correlation Reduction for Offline Reinforcement Learning”[11]则关注了离线强化学习中的虚假相关问题:
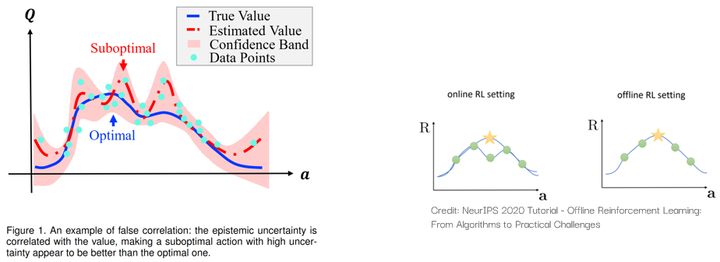
由于样本集的大小是有限的,所以一些次优动作的结果可能是“虚高”的。如果agent不考虑认知不确定性带来的虚假相关,那它就会受到这些次优动作的影响,从而无法习得最优的策略。详细的讲解可以参考专栏里的文章:Zhihong Deng:一篇顶刊论文背后的故事 | TPAMI (2023) 用于离线强化学习的伪相关削减术https://zhuanlan.zhihu.com/p/665683090
可解释性、公平性和安全性**
**这一节因为时间原因我没有写全,感兴趣的朋友可以查看我们的综述和文章的后续更新。 总的来说,我们可以用下面这张图总结causal RL现有工作提供的一些常见思路:
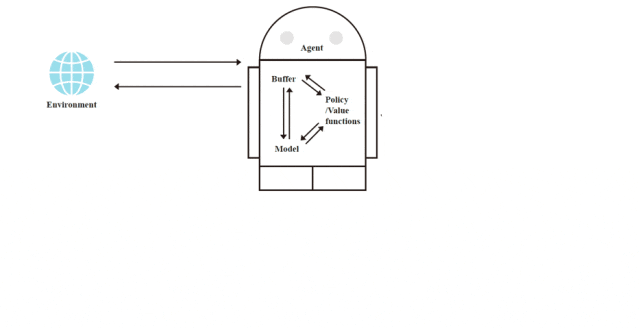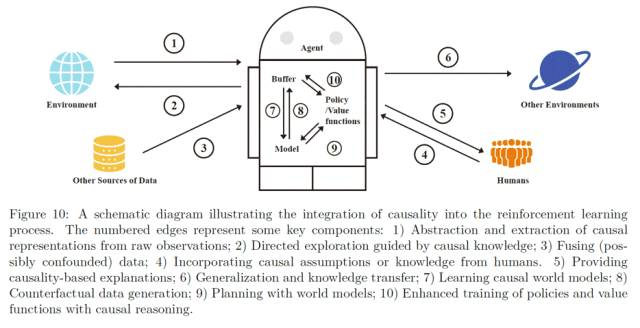
限制
到目前为止,我们已经展示了causal RL方法在增强agents的决策能力方面有巨大的前景,但它并不是一剂盘尼西林。认识到现有方法的局限性同样重要。Causal RL最重要的限制之一在于对领域知识的要求。许多causal RL方法依赖因果图,因此做出准确的因果假设非常重要。例如,在处理混杂偏差时,一些方法需要用到代理变量和工具变量,如果不小心就有可能会带来额外的风险。 此外,在一些现实场景中,原始数据通常是非结构化的,例如图像和文本数据。数据生成过程中涉及的因果变量是未知的,因此需要开发从高维原始数据中提取因果表示的方法 —— 因果表征学习。这些方法通常需要从多领域数据中学习或允许对环境成分进行显式干预以模拟干预数据的生成。学习表征的质量和粒度密切依赖于可用的分布变化、干预或相关信号,而现实中智能体通常只能访问有限数量的域。有的方法不仅仅想要学习因果表征,还想学习背后的因果模型,这是很困难的。在一些情况下,学习因果模型可能比直接学习最优策略更难,这可能会抵消使用模型带来的样本效率的增益。 最后,我们需要承认与反事实推理相关的局限性。获得准确可靠的反事实估计通常需要对潜在的因果结构做出强有力的假设,因为根据定义,反事实是无法被直接观察到的。有些反事实量几乎永远无法识别,而有些则在合适的假设下可被识别,例如 the effect of treatment on the treated(ETT)。此外,反事实推理的计算复杂性也是一个瓶颈,特别是在处理高维状态和动作空间时。这种复杂性可能会阻碍复杂任务中的实时决策。
相关资源
Prof. Elias Bareinboim[12]是最早系统地调查Causal RL这个领域的学者之一,有很多重要工作都出自他的组。他在UAI 2019和ICML 2020上发起了两个tutorial:
- 【Tutorial】Towards Causal Reinforcement Learning [Video] (UAI 2019)http://auai.org/uai2019/tutorials.php#tutorial3
- 【Tutorial】Towards Causal Reinforcement Learning [Video] (ICML 2020)https://crl.causalai.net/
陆超超博士[13]在科普Causal RL方面也做了非常棒的工作,他相信Causal RL是实现AGI的路线之一:
- Causal Reinforcement Learning: A Road to Artificial General Intelligence [Slides] https://www.youtube.com/watch?v=sqKcbjuXGn8
- Causal Reinforcement Learning: Motivation, Concepts, Challenges, and Applications [Slides] https://campus.swarma.org/course/2156
Prof. Yoshua Bengio最近几年在积极地推动因果表征学习这个新兴领域的发展。他与Prof. Bernhard Schölkopf合著的论文[14]中也包括与Causal RL有关的讨论:
- Towards Causal Representation Learning [Slides] https://www.youtube.com/watch?v=rKZJ0TJWvTk
清华大学曾艳博后也为causal RL撰写了一篇综述。这篇综述与本文切入的角度不同,它是从因果信息是否已知的角度对现有工作进行分类的,也非常推荐搭配着阅读:
- A Survey on Causal Reinforcement Learning [Paper] https://pattern.swarma.org/study_group_issue/414
最后是我们在ADMA 2023上发起的tutorial:
- 【Tutorial】Causal Reinforcement Learning: Empowering Agents with Causality [Slides] https://adma2023.uqcloud.net/tutorial.html
更多资源可以参考我们维护的Github项目,欢迎了解 : GitHub - familyld/Awesome-Causal-RL: A curated list of causal reinforcement learning resources. https://github.com/familyld/Awesome-Causal-RL
后记
在着手这篇综述的时候,Agents还是一个相对小众的概念,讨论它的主要是强化学习和机器人领域的学者。然而,短短一年的时间里,伴随着ChatGPT引发的浪潮,从年初的斯坦福小镇[15],再到最近OpenAI开放的GPTs商店[16],LLM驱动的Agents展现出了令人惊叹的智能水平和广阔的应用前景,这不仅引发了学界的广泛讨论,也吸引了各行各业的关注。在热闹的背后,也有不少研究者在思考多样化的路线,以及Agents和人类的关系。除了多模态和具身之外,因果也是一个很好的切入点。我们期待causal RL可以在Agents的时代中能展现出更强大的创造力和发挥更大的作用。 最后的最后打一个小广告,对Causal RL感兴趣的同学欢迎reach out~ 也欢迎合作新的paper! 个人主页:https://2wildkids.com/
参考
- “Causal Parrots: Large Language Models May Talk Causality But Are Not Causal.” https://arxiv.org/abs/2308.13067
- "The Book of Why" - Introduction. http://bayes.cs.ucla.edu/WHY/
- ab“Causality. ” http://bayes.cs.ucla.edu/BOOK-2K/
- "Causal Inference Using Potential Outcomes." https://www.jstor.org/stable/27590541
- “Causal Inference in Statistics: A Primer.” http://bayes.cs.ucla.edu/PRIMER/
- "Causal Influence Detection for Improving Efficiency in Reinforcement Learning." https://proceedings.neurips.cc/paper/2021/hash/c1722a7941d61aad6e651a35b65a9c3e-Abstract.html
- "Woulda, Coulda, Shoulda: Counterfactually-Guided Policy Search." https://openreview.net/forum?id=BJG0voC9YQ
- "A Relational Intervention Approach for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning." https://openreview.net/forum?id=YRq0ZUnzKoZ
- "AdaRL: What, Where, And How to Adapt in Transfer Reinforcement Learning." https://openreview.net/forum?id=8H5bpVwvt5
- "Causal Confusion in Imitation Learning." https://proceedings.neurips.cc/paper_files/paper/2019/hash/947018640bf36a2bb609d3557a285329-Abstract.html
- "False Correlation Reduction for Offline Reinforcement Learning." https://ieeexplore.ieee.org/document/10301548
- https://causalai.net/
- https://causallu.com/
- "Towards Causal Representation Learning." https://ieeexplore.ieee.org/abstract/document/9363924
- “Generative Agents: Interactive Simulacra of Human Behavior.” https://dl.acm.org/doi/abs/10.1145/3586183.3606763
- “Introducing GPTs.” https://openai.com/blog/introducing-gpts
本文首发于作者知乎,原文链接:https://zhuanlan.zhihu.com/p/668830312