RL解决'LunarLander-v2' (SOTA)
在之前的公众号文章中
RL解决'BipedalWalkerHardcore-v2' (SOTA)
RL解决'BipedalWalkerHardcore-v2' (SOTA) 更新
我们介绍了openai gym 环境'BipedalWalkerHardcore-v2'以及我们解决这个环境,达到效果和效率上的 state-of-the-art。
'BipedalWalker' 是连续控制问题,'LunarLander-v2' 是离散控制问题,我们使用maxsqn算法来解决,maxsqn是基于Q-值估计的算法,融合了double-Q learning和entropy regularization(SQL, soft Q learning)。算法的伪代码和实现可以参考我们的项目:
https://github.com/createamind/DRL
https://github.com/createamind/DRL/blob/master/video_pic/maxsqn.png
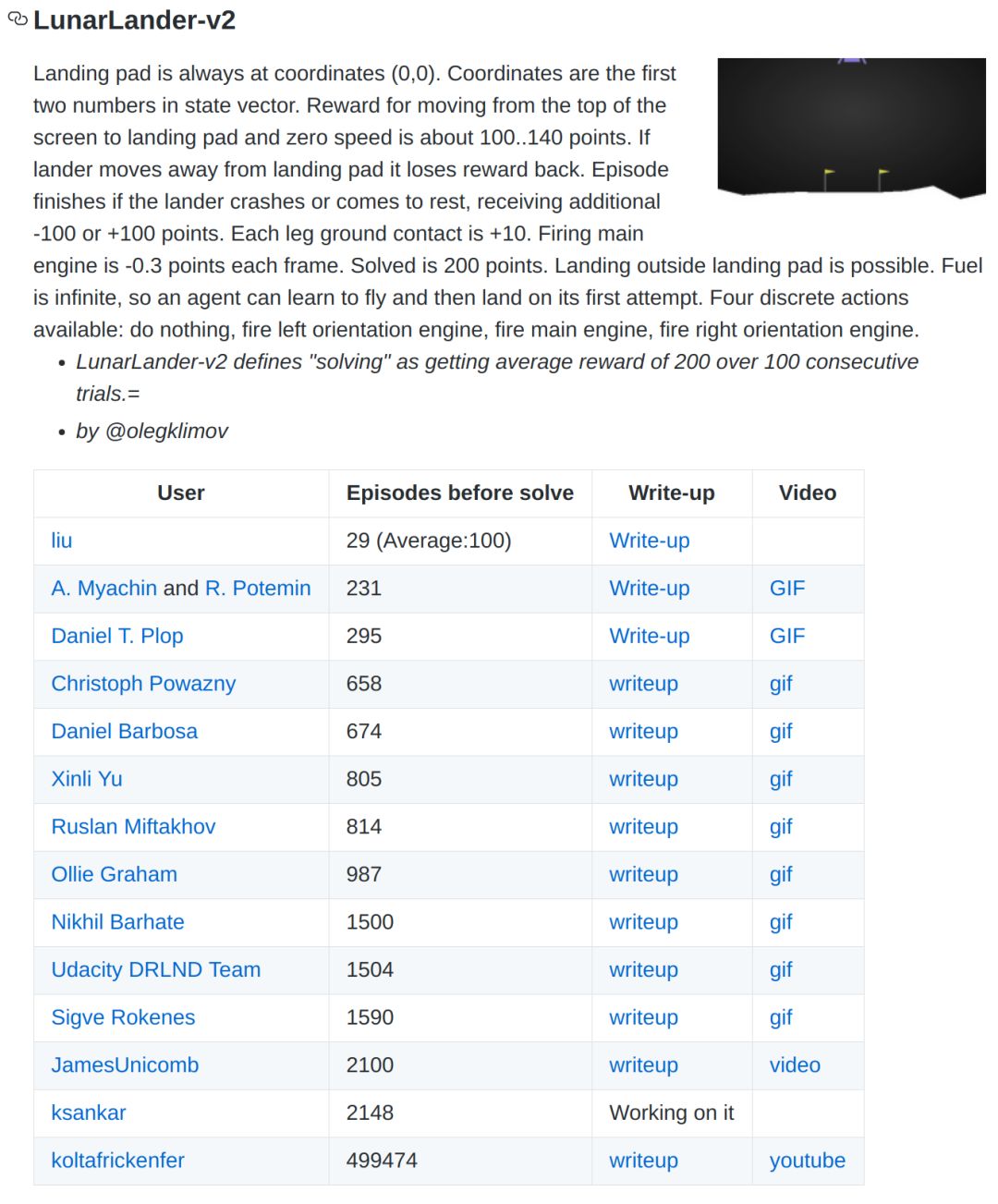
'LunarLander-v2'环境描述的是飞行器降落指定地点,根据降落的平稳程度和降落中使用的燃料来给agent打分。'LunarLander-v2'的observation是基于坐标的而不是图像,Q-network使用两个全连接层就可以解决。'LunarLander-v2'的解决要求是连续100次试验得分在200以上,我们的结果最少只需29个episodes(平均100个episodes)就能解决,比第二名快了一倍以上,learderboard链接:
https://github.com/openai/gym/wiki/Leaderboard#LunarLander-v2
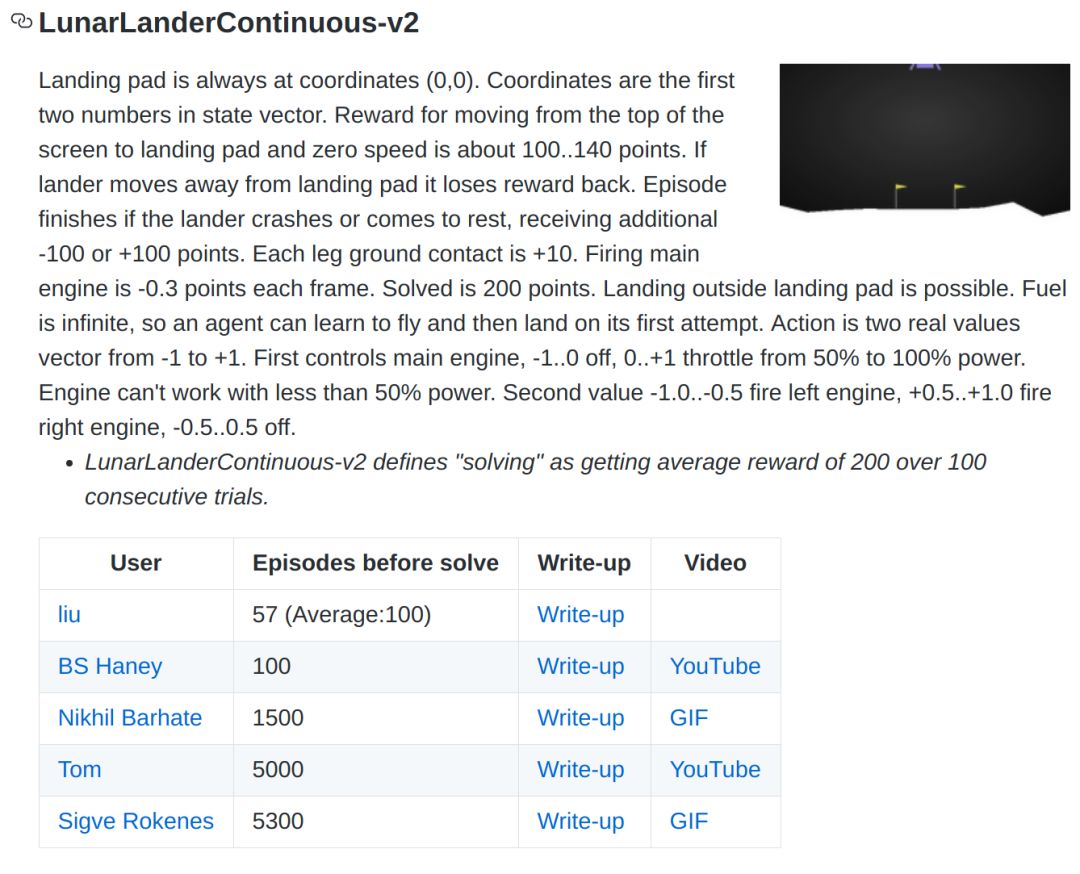
另外,我们也跑了'LunarLander-v2'的连续版本'LunarLanderContinuous-v2',同样达到了state-of-the-art:
https://github.com/openai/gym/wiki/Leaderboard#lunarlandercontinuous-v2
欢迎加入或支持我们 :)


